









参考:
1.各类GAN特征描述:https://blog.csdn.net/AndyViky/article/details/96484742
2.GAN的系列经典模型讲解:https://blog.csdn.net/ch18328071580/article/details/96721665?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
3.GAN,DCGAN,cGAN,pix2pix,CycleGAN,原理简单理解:https://blog.csdn.net/weixin_41866216/article/details/101657693
GAN系列的总结
最近再看GAN网络,顺便把GAN系列的网络总结一下。
GAN
(1)介绍
首先是一个比较典型的GAN模型,GAN全称是生成对抗网络,包括一个生成器G和一个判别器D。
(2)特点
相比于其他生成式模型,有两大特点:
(1)不依赖任何先验假设。传统的许多方法会假设数据服从某一分布,然后使用极大似然去估计数据分布。
(2)生成与真实相似的样本的方式非常简单,仅需要一个生成器即可。
(3)结构
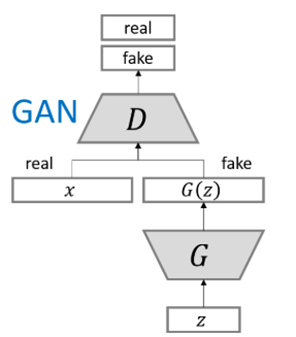
这是GAN的一个简单的结构图,它主要是将一个噪声z,输入到生成器G中,然后输出一张假的图像,然后把这张生成图像与真实图像一起输入到判别器D中,判别器就相当于一个二分类器,判断为真的图像就输出1,判断假的图像就输出0。在训练的时候希望判别器D能将假的图像判断为真,所以判别网络D期望损失函数更大,相反的,生成器G损失尽可能小。
G和D的区分
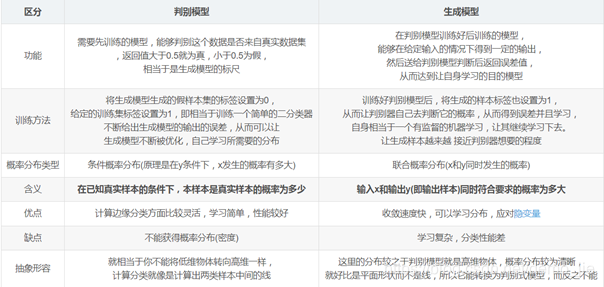
(4)训练
训练网络其实很简单,使用梯度下降法对D和G交替做优化即可,简单分为四步:
(1)从已知的噪声分布Pz(z)中选出一些样本。
(2)从训练数据中选出同样个数的真实图片
(3)设判别器D的参数为θd,,求出损失关于参数的梯度,对参数更新时加上该梯度。
(4)设生成器G的参数为θg,求出损失关于参数的梯度,对参数更新时减去该梯度。
优化的过程中可以,每对D更新一次参数,便接着再更新一次G;或者可以多次优化D的参数,再优化一次G的参数。 哪种方式要根据实际情况考虑。
(5)结果
这是训练了100次的结果,对于我们来说,我们希望判别器判断出来的图像越接近1越好,从这张图可以看出来,训练了100次之后,这个结果是接近1的。

d loss :真假图片的损失相加
g_loss :生成假的图片放入判别器中,得到假的图片与真实图片label的loss
D real: 判别器判断真的图片,越接近1越好
D fake:判别器判断假的图片,越接近0越好

可以看出来随着迭代次数的增加,效果越来越好。
(6)优缺点
GAN 的优点:
(1)GAN是一种生成式模型,相比其他所有模型, GAN可以产生更加清晰,真实的样本
(2)GAN采用的是一种无监督的学习方式训练,可以被广泛用在无监督学习和半监督学习领域
GAN的缺点:
(1)GAN不适合处理离散形式的数据,比如文本
(2)GAN存在训练不稳定、梯度消失、模式崩溃的问题(目前已解决)
原本的结果:
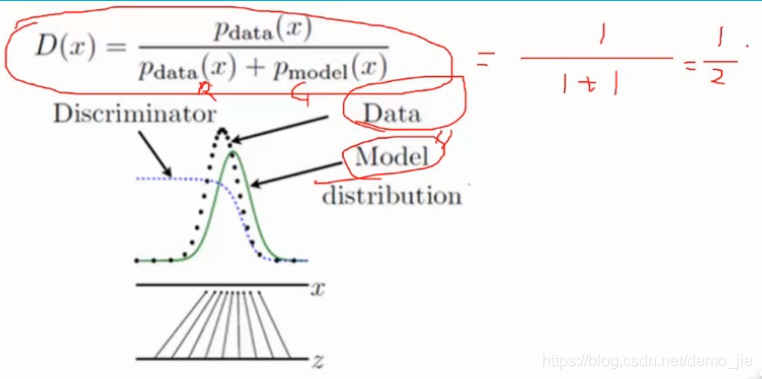
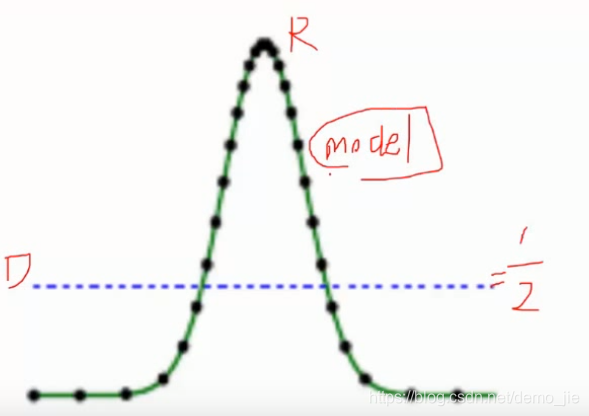
想达到最终的目标,即D(x)=0.5:
参考:GAN原理,优缺点、应用总结:https://blog.csdn.net/qq_25737169/article/details/78857724
CGAN
(1)介绍
因为GAN的限制,GAN虽然可以生成新的样本,但是我们没有办法控制样本的类型,比如刚才的结果,我们可以生成数字但是不能指定生成的是什么数字。这是由于我们输入的只有一个随机的噪声z。这个时候就出现了CGAN,CGAN可以指定生成新样本的类型。
(2)结构
CGAN全称为条件对抗生成网络,它为生成器和判别器,都额外加入了一个条件c,即我们希望生成的标签。
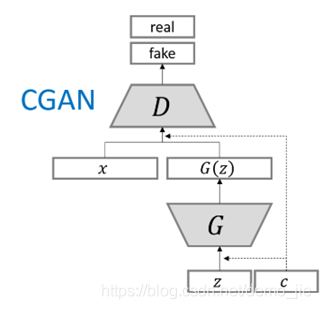
生成器G,输入一个噪声z和一个条件c,输出符合这个条件的图像G(z|c)
判别器D,输入一张图像x,一个条件c,输出该图像在该条件下的真实概率D(x|c)
(3)结果
这是CGAN的结果图:

从左到右依次是
第一张:网络的输入图片(条件)
第二张:生成器生成的建筑图像
第三张:真实的建筑图像(标签)
CycleGAN
(1)介绍
虽然CGAN可以把输入的条件值设置为数字1来生成一个数字1的图片,pix2pix中我们输入鞋子的轮廓图生成鞋子的图片。但是它的样本要求严格成对的,现实中这样成对的样本是比较难获得的。
因此,就出现了CycleGAN,全称为循环生成对抗网络,它在使用时不需要成对的样本。
(2)结构
这是关于CycleGAN的一个简单的结构图:
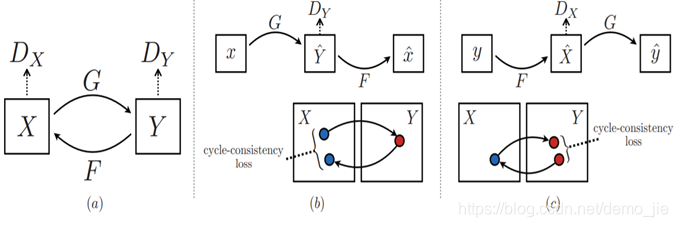 从这个图可以知道,可以将域X的图片通过G转化为域Y。
从这个图可以知道,可以将域X的图片通过G转化为域Y。
Dy:区分转移后的样本G(x)和实际样本y
Dx:区分转移后的样本F(y)和实际样本x
到此一步,根据生成器和判别器构成d的损失是与GAN损失是基本相同的。
但是只使用上面这个对抗性损失是无法训练的。因为没有成对的数据,约束严重不足,因此,又提出了循环一致性损失。另Cycle同时学习F和G两个映射,并且
F(G(x))≈ x,
G(F(y))≈ y。
将循环一致性损失和对抗性损失结合,就能得到完整的不成对图像转换的目标。
(3)结果
成功的将马和斑马完成了交换:

这是一个失败的例子,将马和人作为整体一起实现交换:

(4)优缺点
CycleGAN 的优点:
(1)可以实现无配对的两个图片集的训练
CycleGAN的缺点:
(1)不能用于几何转换,对于涉及到纹理和颜色改变的图像转移时通常会成功,但涉及到几何变化时,成功的例子就不多
waterGAN
(1)介绍
waterGAN其实很简单,从名字就可以知道它是水下生成对抗网络,我们都知道,水下图像一般呈蓝绿色。因此,对水下图像颜色的恢复是个热门话题。但是,在深海环境中的数据集很少。因此,WaterGAN就被研究出来了,它可以生成大量逼真的水下图像数据集。
(2)结构
它的结构其实很简单,也是包括一个生成器G和一个判别器D。但是在它的生成器G中,又分为三个阶段,衰减(G-I),反向散射(G-II)和相机模型(G-III)。
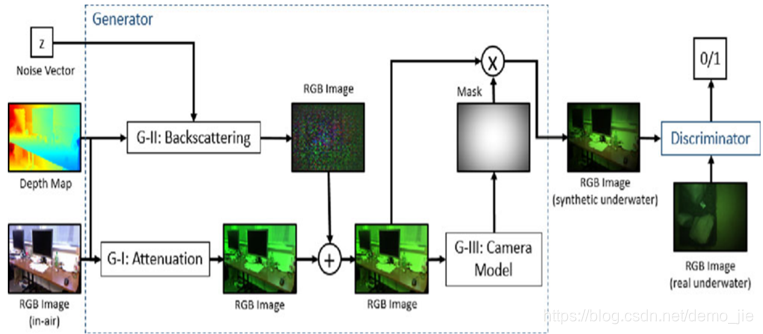
为什么要分三个阶段呢,这样每个阶段只改变其相对的颜色和强度,不改变场景本身的基础结构。
衰减阶段:输入一张RGB图片,输出一张在水中衰减后的图像,
散射阶段:输入一张刚才输入图像的深度图和噪声矢量,因为散射会产生雾效应(所以为了确保成像场景的基础结构不会因RGB-D输入而失真),因此将散射产生的M2与G-I阶段的生成图片相加,得到合成图片G2。
相机模型:因为镜头的影响,光会逐渐朝着图片的边缘变暗,产生渐晕,这样图像的边界会产生阴影,因此本文将产生的渐晕图片与G2相乘得到G3,这里生成器的任务就完成了。
然后将合成的水下图像与真实的水下图像一起输入到判别器中,由判别器判断真假。输出为0(合成图像),输出为1(真实图像)
DCGAN
(1)介绍
DCGAN全称为深度卷积对抗网络,是将CNN与GAN的一种结合。其将卷积网络引入到生成式模型当中来做无监督的训练,利用卷积网络强大的特征提取能力来提高生成网络的学习效果。
DCGAN的原理和GAN对抗生成是一样的。它只是把GAN的G和D换成了两个卷积神经网络(CNN),但不是直接换就可以了。
(2)结构改变
DCGAN对卷积神经网络的结构做了一些改变,以提高样本的质量和收敛的速度,这些改变有:
(1)取消所有pooling层。G网络中使用转置卷积(transposed convolutional layer)进行上采样,D网络中用加入stride的卷积代替pooling;
(2)除了生成器模型的输出层和判别器模型的输入层,在网络其它层上都使用了BatchNormalization,使用BN可以稳定学习,有助于处理初始化不良导致的训练问题;
(3)去掉全连接层,使网络变为全卷积网络;
(4)G网络中使用ReLU作为激活函数,最后一层使用tanh;
(5)D网络中使用LeakyReLU作为激活函数。
其中,转置卷积(也称反卷积)transposed conv或者deconv。
(3)优缺点
优点:
1 将网络应用于GAN的训练。
2 为GAN的训练提供了一个很好的网络拓扑结构。
3 表明生成的特征具有向量的计算特性。
缺点:
1 对GAN训练稳定性来说没有从根本上解决问题,而且训练的时候仍需要小心的平衡G,D的训练进程,往往是训练一个多次,训练另一个一次。


















 892
892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









