







 本文详细介绍了CycleGAN的论文、基本概念和核心思想,特别是循环一致性损失在解决生成图像ID不一致问题上的作用。同时,提供了PyTorch实现CycleGAN的代码参考链接,帮助读者理解并实践CycleGAN的训练过程。
本文详细介绍了CycleGAN的论文、基本概念和核心思想,特别是循环一致性损失在解决生成图像ID不一致问题上的作用。同时,提供了PyTorch实现CycleGAN的代码参考链接,帮助读者理解并实践CycleGAN的训练过程。
1.cycleGAN论文
https://arxiv.org/abs/1406.2661
2.cycleGAN简单介绍
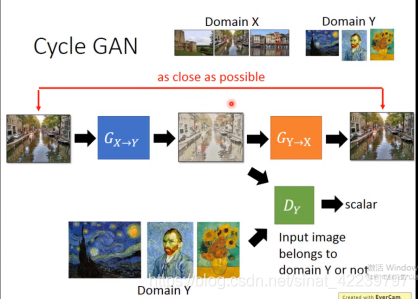
首先:
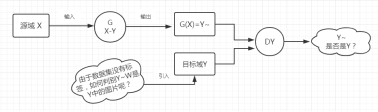
这个过程呢和GAN是一样的。
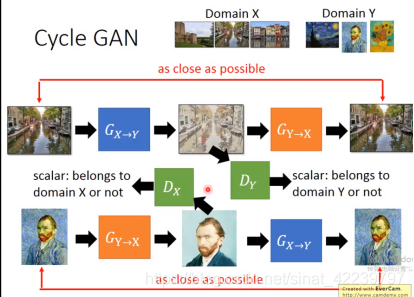
但是,最终学习后的结果,很有可能G (X-Y)输出的图像的ID并不是源域X的ID,而是目标域Y中的另一个ID的相似度极高的图片,那么如何解决这一问题呢,这篇文章就引入了一个循环一致性损失(a cycle consistency loss)来使得F(G(X))≈X(反之亦然),含义就是把源域的生成的图片再映射回源域,其分布依然是趋于相同的。
这个引入的过程如下:
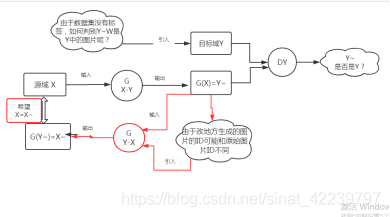
但是由于G(Y-X)并没有真正见到过目标域Y中的图像,它的输入都是G(X-Y)生成的,但是有可能生成的不一定正确,于是我们将Y作为输入,输入到G(Y-X)中,让它生成一个真实的源域X中的图片X ~ ~ 。
然后再将G(X-Y)拿过来,希望前面生成的X~~转成目标域中的图片。
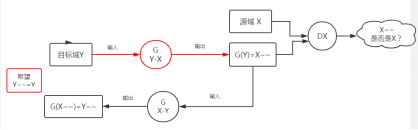
这里面其实是一个循环的过程,共两个生成器,其实图中两个红色的G(Y-X)是一个,两个黑色的G(X-Y)也是一个,两个判别器D(X),D(Y).。
3.cycleGAN代码讲解
https://github.com/aitorzip/PyTorch-CycleGAN
train.py
#!/usr/bin/python3
import argparse
import itertools
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torch.autograd import Variable
from PIL import Image
import torch
from models import Generator
from models import Discriminator
from utils import ReplayBuffer
from utils import LambdaLR
from utils import Logger
from utils import weights_init_normal
from datasets import ImageDataset
parser = argparse.ArgumentParser()
parser.add_argument('--epoch', type=int, default=0, help='starting epoch')
parser.add_argument('--n_epochs', type=int, default=200, help='number of epochs of training')
parser.add_argument('--batchSize', type=int, default=1, help='size of the batches')
parser.add_argument('--dataroot', type=str, default='datasets/horse2zebra/', help='root directory of the dataset')
parser.add_argument('--lr', type=float, default=0.0002, help='initial learning rate')
##学习率下降的epoch
parser.add_argument('--decay_epoch', type=int, default=100, help='epoch to start linearly decaying the learning rate to 0')
parser.add_argument('--size', type=int, default=256, help='size of the data crop (squared assumed)')
parser.add_argument('--input_nc', type=int, default=3, help='number of channels of input data')
parser.add_argument('--output_nc', type=int, default=3, help='number of channels of output data')
parser.add_argument('--cuda', action='store_true', help='use GPU computation')
parser.add_argument('--n_cpu', type=int, default=8, help='number of cpu threads to use during batch generation')
opt = parser.parse_args()
print(opt)
if torch.cuda.is_available() and not opt.cuda:
print("WARNING: You have a CUDA device, so you should probably run with --cuda")
###### ============ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6397
6397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









