







上次小编在《Flux“炼丹炉”——fluxgym安装教程》一文中已经分享了flux的便捷炼丹炉,并且手把手分享了安装方法,现在丹炉有了,那就开始着手炼丹!
如何炼丹(训练 Lora)?
使用方法非常简单,总的来说就以下三步:
- 输入 lora 信息
- 上传图片并为其添加标题(使用触发词)
- 点击“训练”。
然后喝杯咖啡慢慢等待即可。
下面我们来训练一个刘亦菲的 Lora,看看效果怎么样。
1.获取训练素材
训练素材渠道很多,可以从网上找,如果想训练其它的东西,可以使用 midjourney、SD、Flux 等生成图片,然后挑选合适的作为素材用来训练。我从网上随便找了几张:
这里只是是顺手改了图片名,也可以不修改,在这个丹炉中炼丹主打的就是一个方便~
2.基本处理(可选)
得到图片素材后可以选择进行一定的处理,提高质量。特别是找到的图片清晰度不高(马赛克风)的话,可以使用超分(超分辨率)提高质量。当然追求更高质量的话,还可以对图片进行抠图操作,抠图后只保留需要训练的主体,能够有利于算法捕捉到特征。可以先进行抠图,然后再使用超分提高质量。
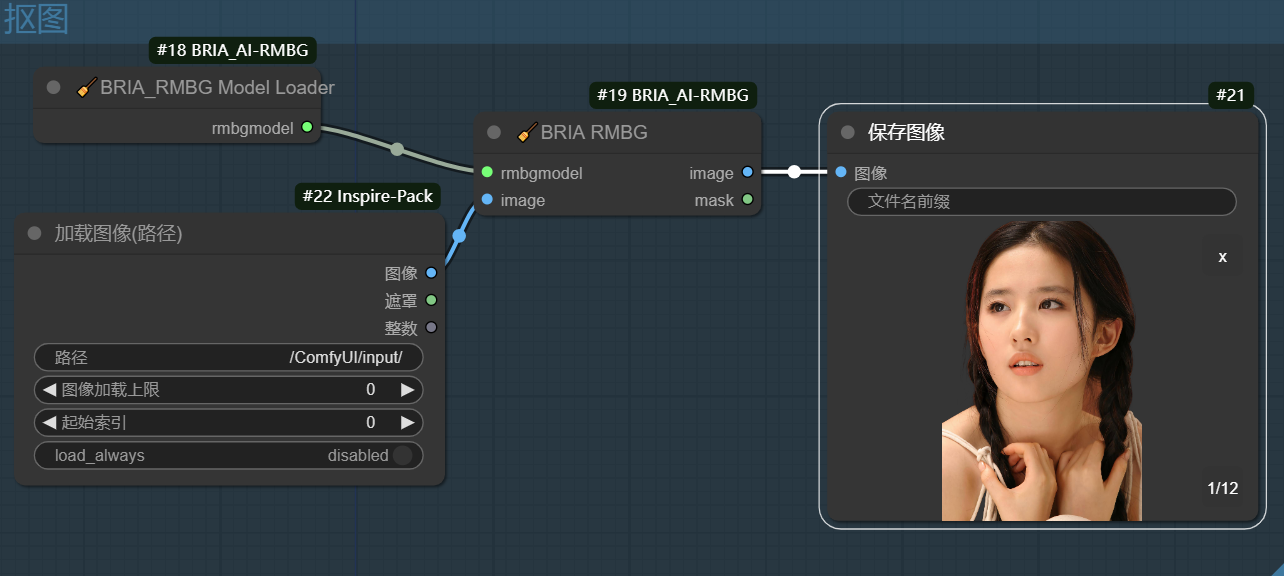
① 抠图
我使用 ComfyUI 工作流进行批量处理,当然 sd-webui 还有 Ps 都可以。下面是我抠图的工作流,主要是使用 BRIA_AI 节点(没有的可以安装),处理下来效果挺不错的。
② 超分放大
超分放大(高清修复、高分放大)有很多种方法,按原理大致可分为:像素放大、模型放大、重采样放大、区块放大。在 stable diffusion webui 中可以通过插件来获取这些功能,比如:Ultimate SDupscale(终极 sd 放大)、ControlNet 的 tile、AI upscaler(AI 放大)等等,也可以混合使用,下面我通过使用 ControlNet 的 tile 和终极 sd 放大法相结合进行图片超分(混合会增加处理时长)。
需要一提的是 Ultimate SDupscale(终极 sd 放大)和 ControlNet 的 tile 的方法都需要额外的模型支撑,也就是需要下对于的模型,但是并不大,一共也就几百 MB。
Ultimate SDupscale (终极 sd 放大):
安装方法如下图:
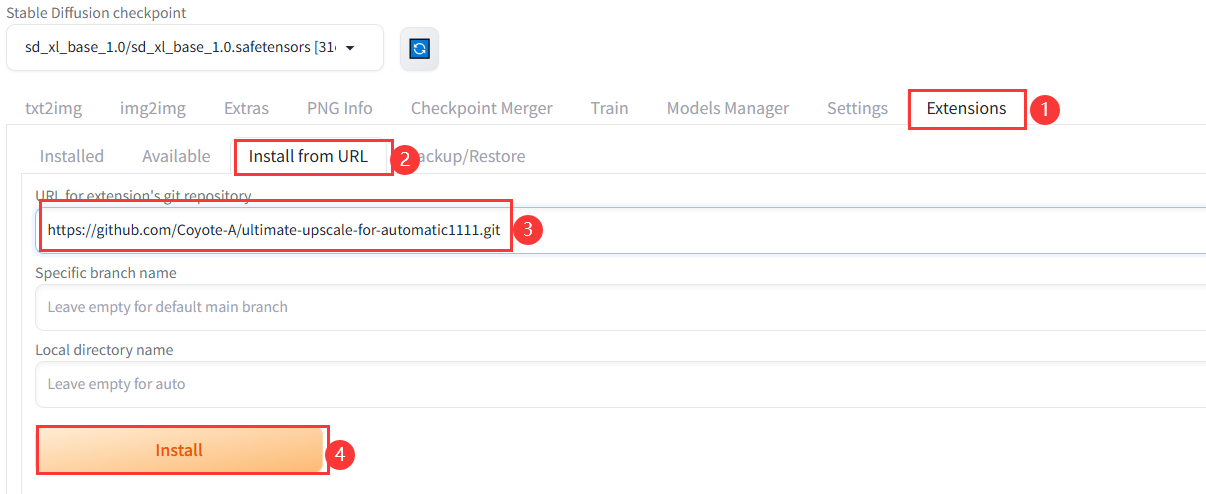
插件地址为:https://github.com/Coyote-A/ultimate-upscale-for-automatic1111.git
安装后,重新启动 sd webui 即可。
ControlNet 的 tile:
ControlNet 的地址为:https://github.com/Mikubill/sd-webui-controlnet.git
安装方法和上面相同,ControlNet 的功能有很多,每个功能有对应的模型,这里我们只使用 tile 功能,因此只需下载对应的模型。
我的模型下载地址如下:
https://hf-mirror.com/bdsqlsz/qinglong_controlnet-lllite
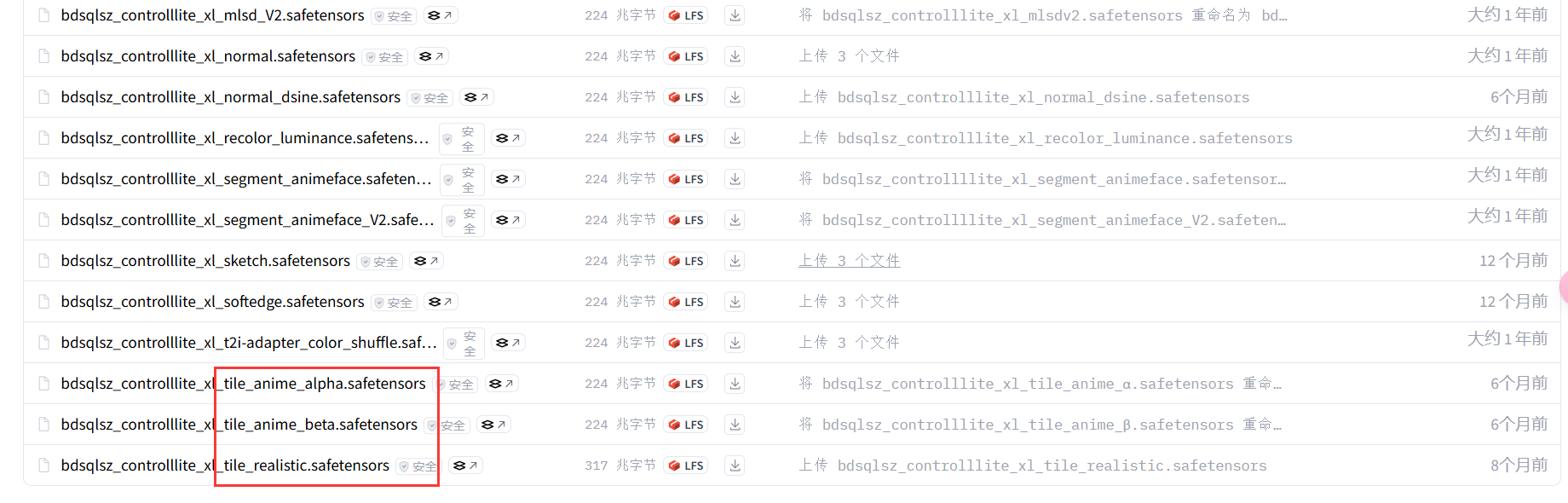
上面两个是动漫类型的,最后一个是我们需要的现实风模型,将其下载后放到 /stable-diffusion-webui/extensions/sd-webui-controlnet/models/ 文件夹下。下载完成后就可以进行图片处理操作了。
操作步骤:
设置 Sampling steps 为 20,这是迭代步数,想要更多细节可以适当调大。
设置 Denoising strength(去噪强度)为 0.2,也称为重绘幅度,值越大,AI 越放飞自我;值越小,与原图就越像。
然后点击 ControlNet 选项卡:
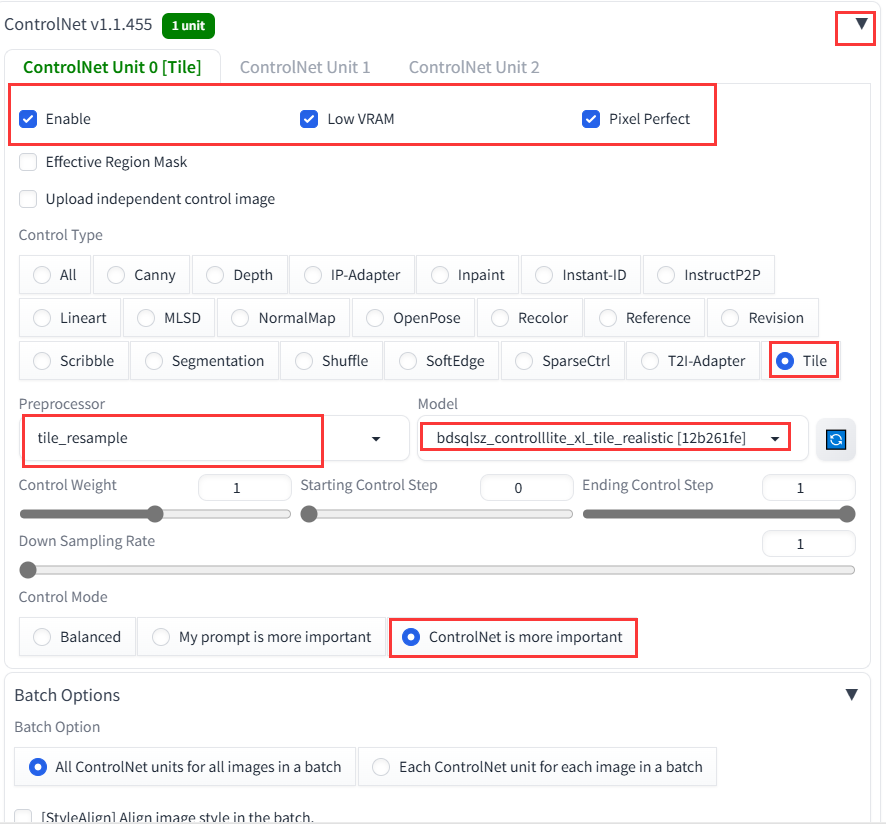
其中,Enable 表示启用 controlnet 功能,如果显存小就把 Low VRAM 勾选上,Pixl Perfect (完美像素模式)选上。然后在 Preprocessor 中选择 tile_resample 功能,并在 Model 处选择下载好的模型,例如我的为:bdsqlsz_controlllite_xl_tile_realistic [12b261fe]
然后点击 Script 选项卡,选择 Ultimate SD Uscale,并按下图选择:
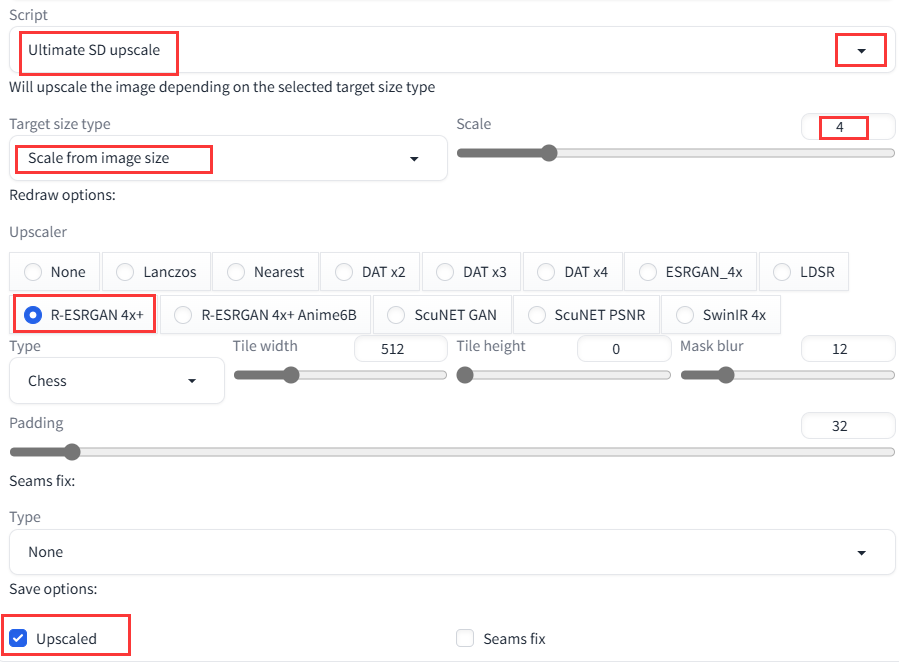
全部设置完成之后点击“Generate”进行生图,其中,Ultimate SD upscale 会自动下载它的模型,如果因为网络问题无法下载,可在下面的网址中手动下载并将其放到 /stable-diffusion-webui/models/RealESRGAN/ 文件夹,并重新启动 webui。
下载地址:https://hf-mirror.com/epishchik/RealESRGAN_x4plus/tree/main

处理完成之后,如下:
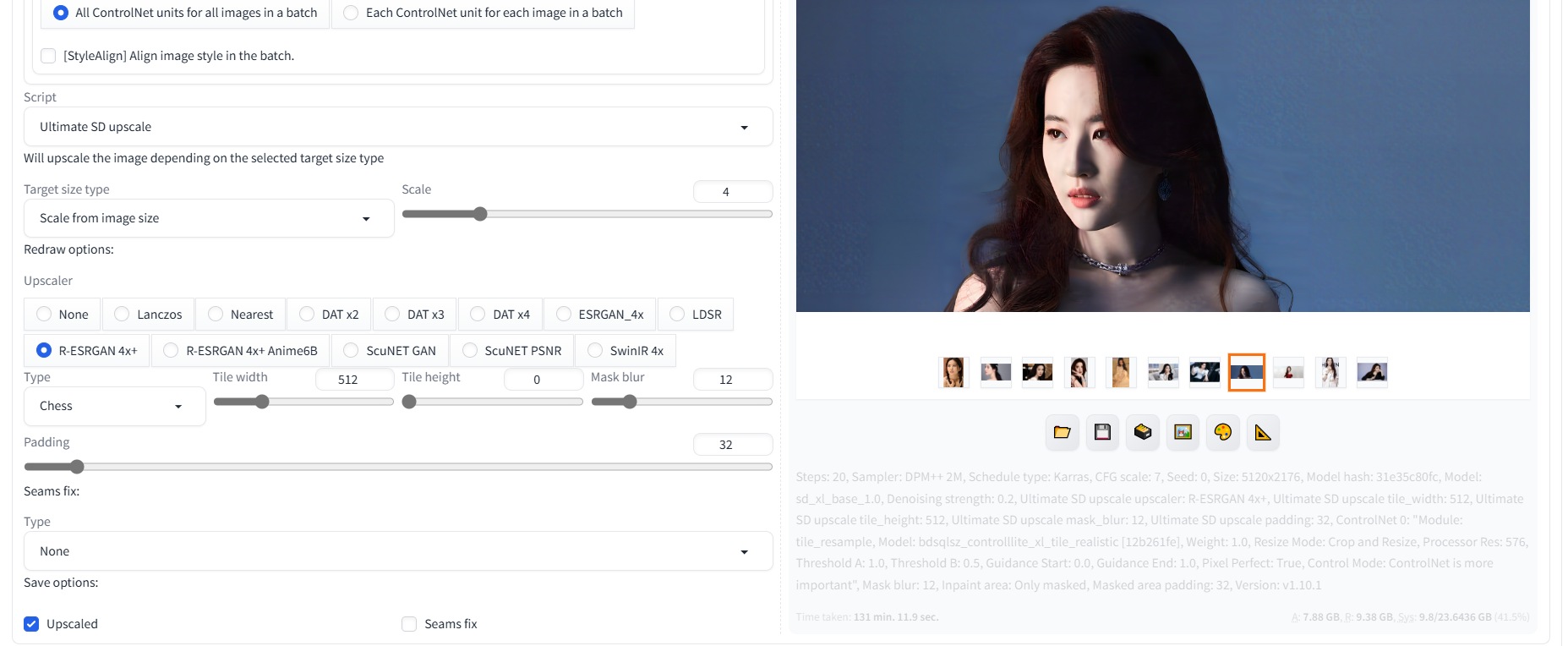
使用 ControlNet 的 tile 和 Ultimate SD upscale 进行超分处理前后的对比图:


可以看出处理的效果还是不错的。如果用处理后的图片进行 Lora 模型训练,那效果就会好的多。想要追求质量的话当然是需要处理更多的东西的,下面就可以正式开始炼丹了!
3.开始炼丹
经过前面的处理,我们已经有了训练 Lora 的资本了,接下来是紧张又激动的环节,操作步骤如下(非常简单):
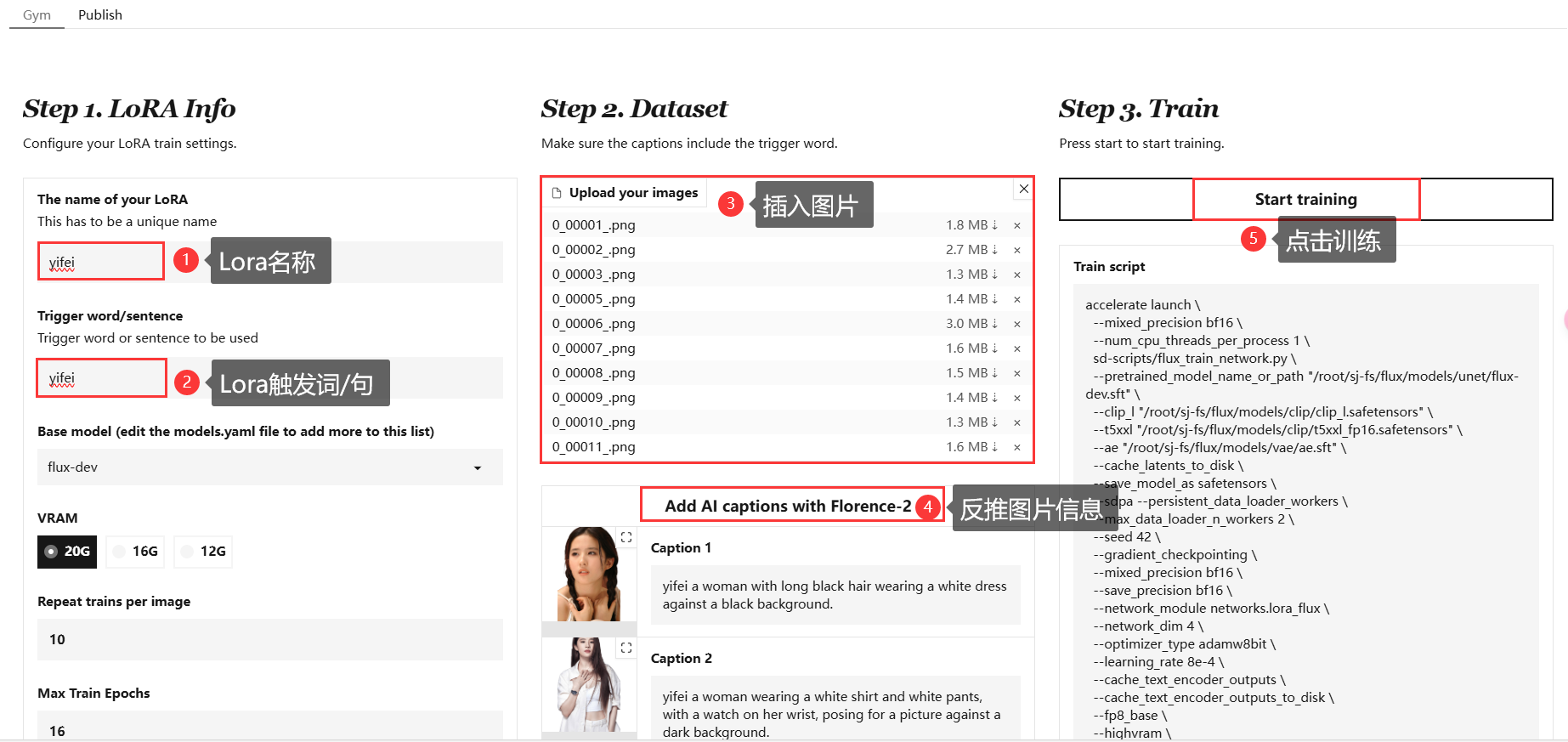
没错就只需要以上几步你就可以训练自己的模型了,后面只需等待“起丹”即可:
其它功能
虽然,只需要上面三步就已经进行训练,但是想要更好的控制训练的过程和质量,就需要更多的参数,下面这些也起到很大的作用,一起来看看吧:
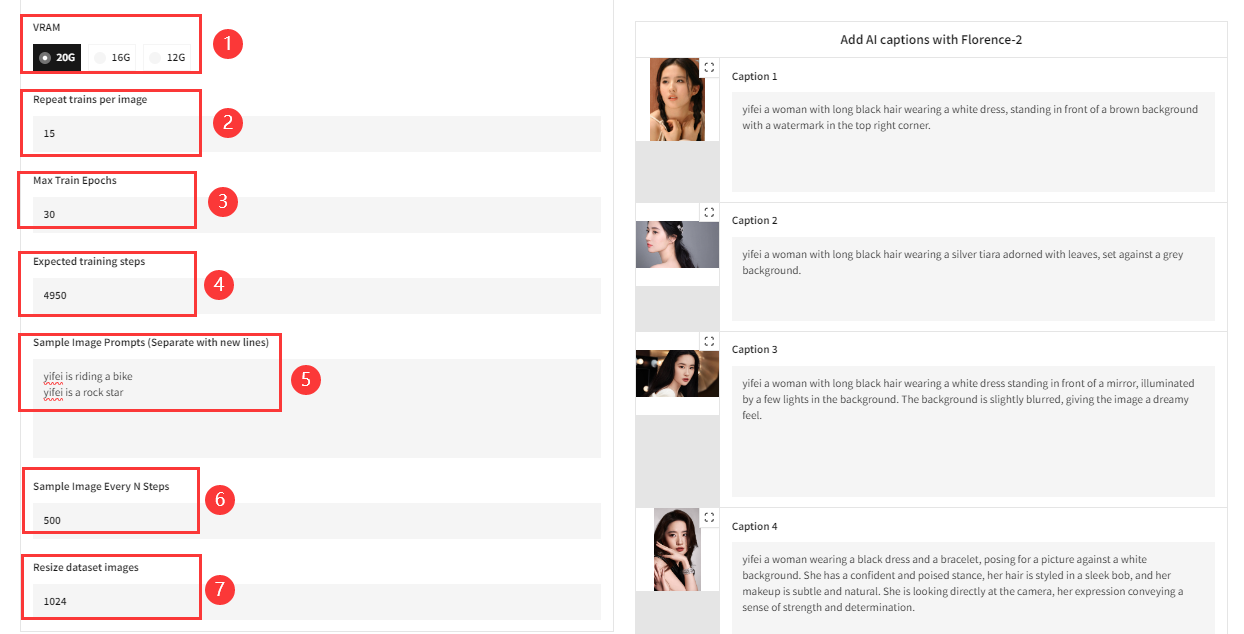
①VARM 也就是显存大小,正如之前介绍中所提到的一样,本丹炉对于低显存玩家也非常友好,你可以根据自己的显存进行选择。
③Max Train Epochs 表示完整遍历图片的轮数,比如我的图片素材有 5 张,训练的时候依次从图片 1 到图片 5 遍历一遍,这就称为一轮。
②Repeat trains per image 这个超参数的的意思是一轮中每张图像重复训练的次数,举个栗子:还是那 5 张图片,在一轮中,每张图片训练一次就开始下一张,每张重复了 1 次那“Repeat trains per image”就是 1;但是在一轮中,我每张图片重复训练 15 次,那“Repeat trains per image”就为 15。
④Expected training steps 是通过计算出来的:总步骤=轮次 * 每张图片重复次数 * 图片的数量。
⑤Sample Image Prompts (Separate with new lines):这个是在我们炼丹时通过生成图片的方式实时反馈我们的训练效果。默认情况下, fluxgym 在训练期间不会生成任何样本图像。但是,你可以将 Fluxgym 配置为每 N 个步骤自动生成样本图像。这是它的样子:
要打开此功能,只需设置两个字段:
- 示例图像提示 :也就是上面的标号 ⑤ 。输入的这些提示将用于训练期间自动生成图像。如果需要多个,换行再输入提示就行。
- 每 n 步采样图像 (标号 ⑥): 如果你的的“Expected training steps(预期训练步骤)”为 960,“Sample Image Every N Steps(每 N 步样本图像)”为 100,则将在步骤 100、200、300、400、500、600、700、800、900 为每个提示生成图像。
⑦Resize dataset images 用于调整数据集中图像的大小。所有的图像会被重设为指定的尺寸,以便训练过程中的图像大小一致。如果设置为 512,所有数据集的图像会被调整为 512x512 像素大小,推荐为 1024。
高级选项
通常高级选项中的参数是默认的,我们可以不用修改直接炼丹即可。但是其中有几个参数还是建议根据实际情况进行修改,一起来看看吧:
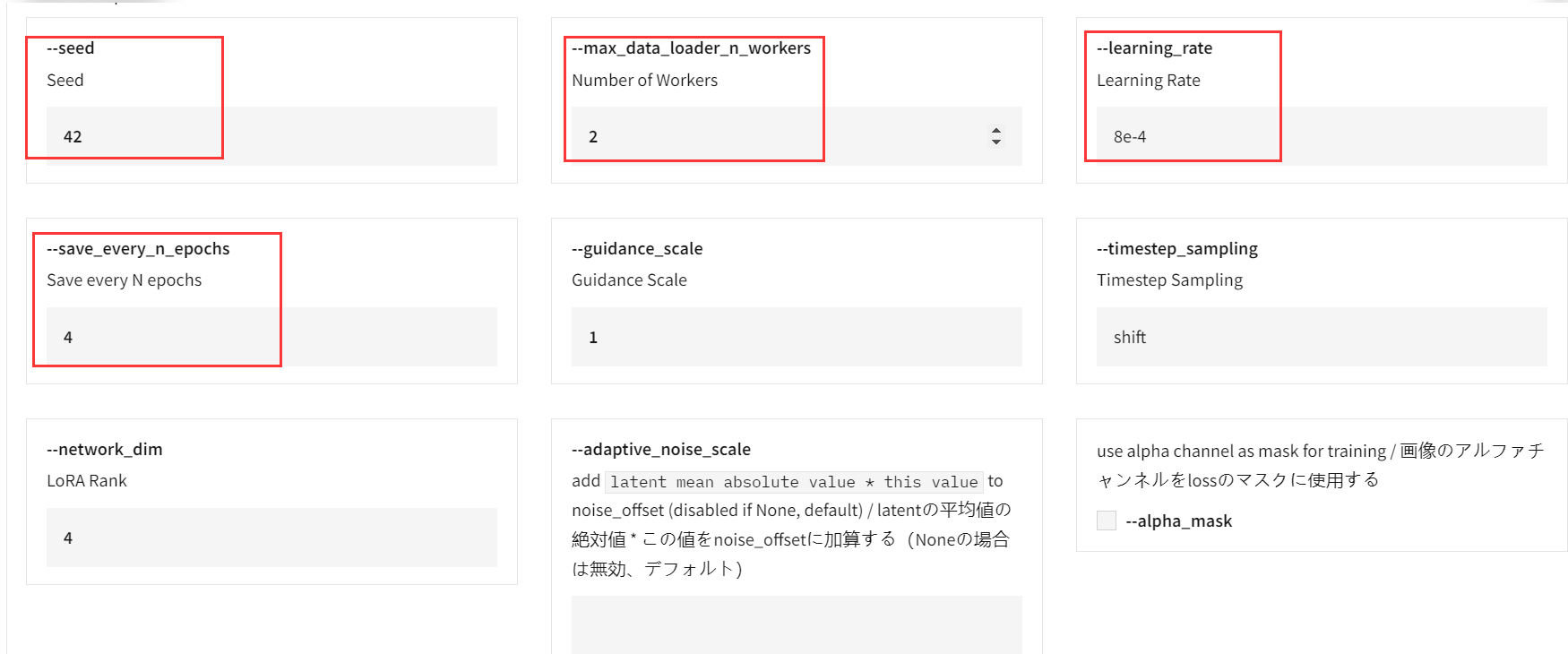
--seed(Seed) :
这是训练过程中的随机数种子,决定了随机数生成的序列。设定一个固定的种子可以保证结果的可重复性。每次使用相同的种子训练模型,模型的训练过程和输出结果将是一致的,方便调试和对比。
--max_data_loader_n_workers(Number of Workers) :
表示数据加载时使用的工作线程数。更多的工作线程可以加速数据加载,特别是在处理大型数据集时。设置较高的线程数能加快数据的预处理和加载,但会占用更多的 CPU 资源。这需要根据实际设备的能力进行修改。
--learning_rate(Learning Rate) :
这是学习率,学习率决定了模型在每一步更新时参数的变化速度。较大的学习率会使模型收敛更快,但可能导致跳过最优解;较小的学习率则会使训练更加稳定,但可能收敛得较慢。默认的学习率是 8e-4(即 0.0008),表示每次更新参数时会按 0.0008 的比例调整。
--save_every_n_epochs(Save every N epochs) :
每 N 个 epoch (轮次)保存一次模型。这里设置为 4,意味着模型每训练 4 个 轮次就会保存一次。定期保存模型,以防训练中断或者之后可以使用中间模型进行评估,这是最需要修改的选项,如果你的轮次设置的多,那么建议这个参数也相应的修改,但是建议和 epoch 成整数倍。比如:我设置 20 论,那么这个参数为:4*5、
--network_dim(LoRA Rank) :
这是 LoRA 模型的秩(Rank)参数,影响 LoRA 低秩矩阵的维度。较高的维度会增加模型的容量,但也会增加训练时间和资源消耗。调节 LoRA 模型的复杂性。值越大,模型能够学习到的细节越多,但会增加计算量。
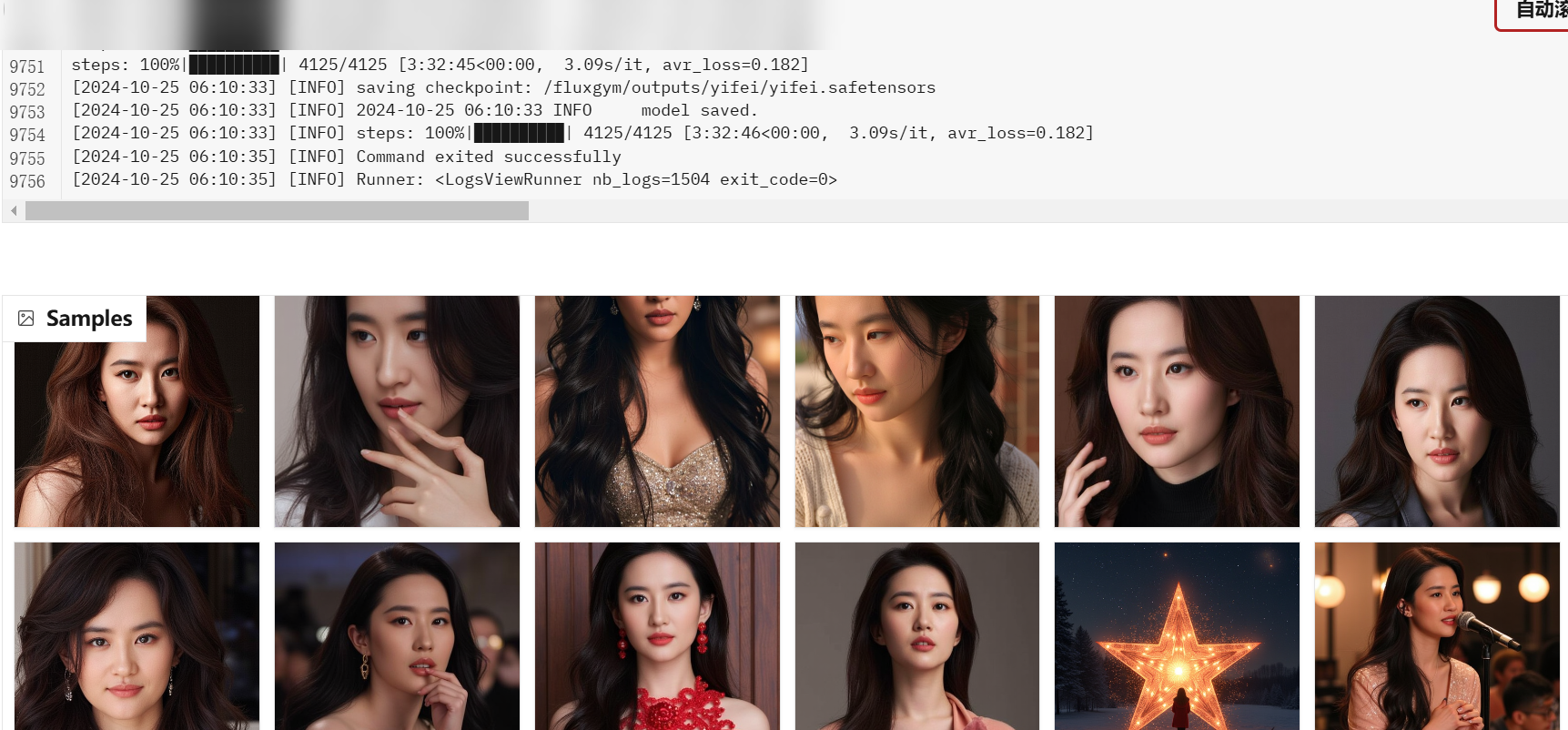
4.起丹
等待训练结束后,可在 /fluxgym/outputs/ 文件夹下获取,每一次保存的节点模型都在这里,yifei.safetensors 是最终的模型,如下图:
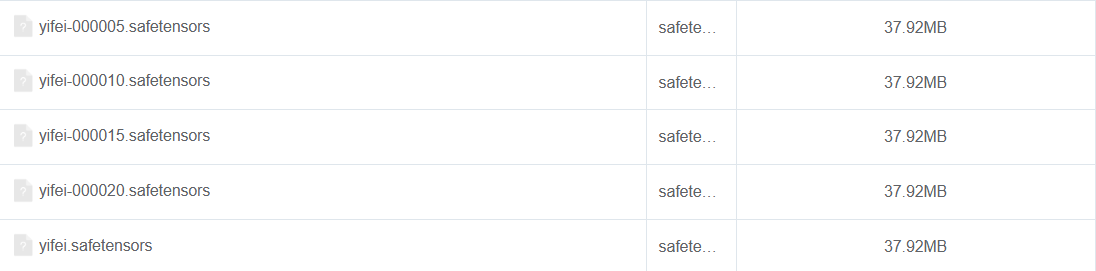
这些模型效果各异,也不一定就是最后一个模型效果最好,我们可以通过 xyz 的方法进行模型测试,然后挑选最好出来使用,测试的方法后面再介绍吧~


















 353
353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









