







 本文详细介绍了从单隐层神经网络到深度神经网络的构建过程,通过Keras实现预测客户流失率的案例。讨论了神经网络的优势,如自动特征工程,并解释了传统机器学习的局限性。文章深入探讨了神经网络的超参数,如激活函数、损失函数和优化器的选择,并提出特征缩放的重要性。通过训练和调整,展示了如何提高模型性能和避免过拟合,如使用Dropout层和TensorBoard进行可视化。
本文详细介绍了从单隐层神经网络到深度神经网络的构建过程,通过Keras实现预测客户流失率的案例。讨论了神经网络的优势,如自动特征工程,并解释了传统机器学习的局限性。文章深入探讨了神经网络的超参数,如激活函数、损失函数和优化器的选择,并提出特征缩放的重要性。通过训练和调整,展示了如何提高模型性能和避免过拟合,如使用Dropout层和TensorBoard进行可视化。
深度神经网络
一、神经网络原理
1.传统机器学习算法的局限性
越简单的关系越容易过拟合。
对于特征的变换、升阶,以及多个特征相互组合形成新特征的过程,就是机器学习过程中既耗时又耗力的特征工程。
特征空间是数据特征所形成的空间,特征维度越高,特征空间越复杂。而假设空间则是假设函数形成的空间,特征越多,特征和标签之间的对应的关系越难拟合,假设空间也就越复杂。
维度灾难:高维度带来了超高的复杂度和超巨大的特征空间。比如,尾气特征维度是19x19,但是它的有效状态数量超过了10170。
2.神经网络优势
当用神经网络去识别猫的时候,不需要手工去编写猫的定义,他的定义只存在于网络中的大量“分道器”中。这些分道器负责控制在网络的每一个分岔口把图片往目的地输送。而神经网络 就像一张无比旁大、带有大量分岔路的铁轨网。
在这密密麻麻的铁轨的一边是输入的图片,另一边则是对应的输出结果,也是道路的终点。网络会通过调整其中的每一个分道器来确保输入映射到正确的输出。训练数据越多,这个网络中的轨道越多,分岔路口越多,网络也就是越复杂。一旦训练好了,我们就有了大量的预定轨道,对新图片也能做出可靠的预测,这就是神经网络的自我学习原理。
数据越多,投票者越多,就能获得越多的模式。
那些机械化的定义在神经网络面前变得不再有任何用处。
深度学习的机理:他是用一串一串的函数,也就是层,堆叠起来,作用域输入数据,进行从原始数据到分类结果的过滤于提纯。这些层通过权重来参数化 ,通过损失函数来判断当前网络的效能,然后通过优化器来调整权重,寻找从输入到输出的最佳函数。
注意以下两点:
- 学习:就是为了神经网络的每个层中的每个神经元寻找最佳的权重。
- 知识:就是学到的权重。
二、从感知层到单隐层网络
神经网络由神经元组成,最简单的神经网络只有一个神经元,叫感知器。
Sigmiod函数,在逻辑回归中叫做逻辑函数,在神经网络中则被称作激活函数,用以类比人类神经系统中神经元的“激活”过程。
根据不同的数据输入,感知器适当的调整权重,在不同的功能之间切换(也就是拟合),形成了一个简单的自适应系统,人们就说它有了“感知"事物的能力。
单神经元,也就是感知器,通过训练可以用作逻辑回归分类器。
- 输入空间:x,输入值的集合。
- 输出空间:y,输出值的耳机和,通常,输出空间会小于输入空间。
- 特征空间:每一个样本被称作一个实例,通常由特征向量表示,所有特征向量存在的空间称为特征空间,特征空间有时候与输入空间相同,有时候不同。因为有时候经过特征工程之后,输入空间可通过某种映射生成新的特征空间。
- 假设空间:假设空间一般是对于学习到的模型而言的。模型表达了输入到输出的一种映射集合,这个集合就是假设空间,假设空间代表着模型学习过程中能够覆盖的最大范围。
基本的原则:模型的假设空间,一定要大到覆盖特征空间,否则模型就不可能精准地完成任务。
无论我们如何调整感知器的权重和偏置,都无法拟合”同或“数据集从特征到标签的逻辑。感知器是有局限性的。
神经网络隐层的出现把手工的特征工程丢给了神经网络,网络第一层权重和偏置自己去学,网络的第二层的权重和偏置自己去学,网络其他层的权重和偏置也是自己去学。我们除了提供数据以及一些网络的初始参数之外,剩下的事情都让网络自己完成。
哪怕特征数量再大,特征空间在复杂,神经网络通过多层框架也可以将其搞定。
注意神经网络的上下标符号。
三、用Keras单隐层网络预测客户流失率
前面的许多,都是为了了解神经网络的”分层“
层,是神经网络的基本元素。 在实际应用中,神经网络是通过不同类型的”层“来构建的,而这个构建过程并不需要,具体到每层内部的神经元。
1.数据的准备于分析
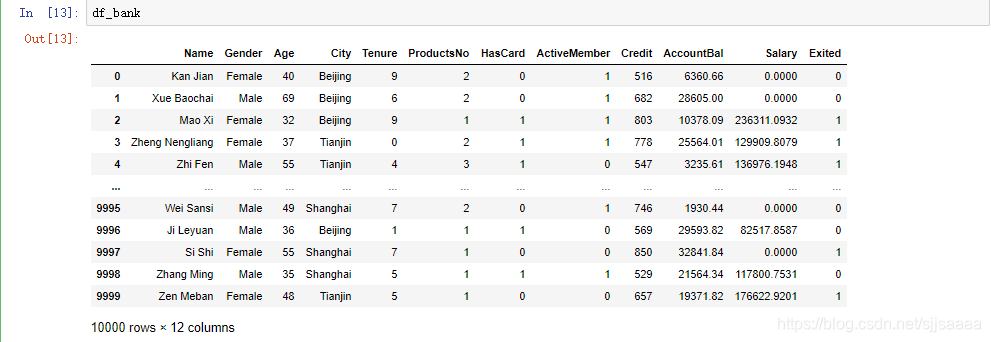
| 标签 | 含义 |
|---|---|
| Name | 姓名 |
| Gender | 性别 |
| Age | 年龄 |
| City | 城市 |
| Tenure | 已经成为客户的年头 |
| ProductsNo | 拥有的产品数量 |
| HasCard | 是否有信用卡 |
| ActiveMember | 是否为活跃用户 |
| Credit | 信用等级 |
| AccountBal | 银行存款余额 |
| Salary | 薪水 |
| Exited | 客户是否已经流失 |
这些信息对于客户是否流失是具有指向性的。
读取文件
数据下载地址:https://download.csdn.net/download/sjjsaaaa/18176777
import numpy as np
import pandas as pd
df_bank = pd.read_csv(r'E:\Users\lenovo\Desktop\银行客户流失\数据集\BankCustomer.csv')
显示数据分布情况
import matplotlib.pyplot as plt
import seaborn as sns
features = {
'City','Gender','Age','Tenure','ProductsNo','HasCard','ActiveMember','Exited'}
fig = plt.subplots(figsize=(15,15))
for i,j in enumerate(features):
plt.subplot(4,2,i+1)
plt.subplots_adjust(hspace = 1.0)
sns.countplot(x=j, data = df_bank)
plt.title("No, of cnstumers")
plt.show()
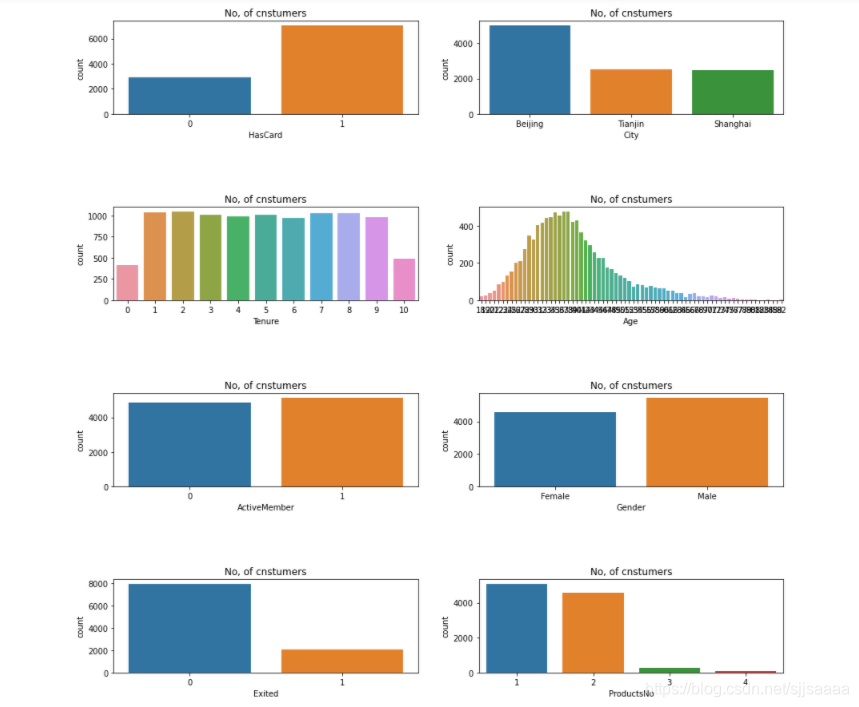
从图中可以看出:北京的客户最多,男女客户比例大概一致,年龄和客户,数量呈正态分布。
数据预处理
- 性别。这是一个二元类别的特征,需要转为0/1代码格式进行读取处理。
- 城市。这是一个多元类别的特征,应把它转换为多个二元类别的哑变量。
- 姓名。这个字段对于客户流失与否的预测应该是完全不相关的,可以在进一步处理之前忽略。
原始数据集中标签也应移除,放置于标签集。
#把二元类别文本数字化
df_bank['Gender'].replace("Female",0,inplace = True)
df_bank['Gender'].replace("Male",1,inplace = True)
df_bank

#把多元类别转成多个二元类别哑变量,然后放回原始集
a = pd.get_dummies(df_bank['City'],prefix='City')
b = [df_bank,a]
df_bank = pd.concat(b,axis=1)
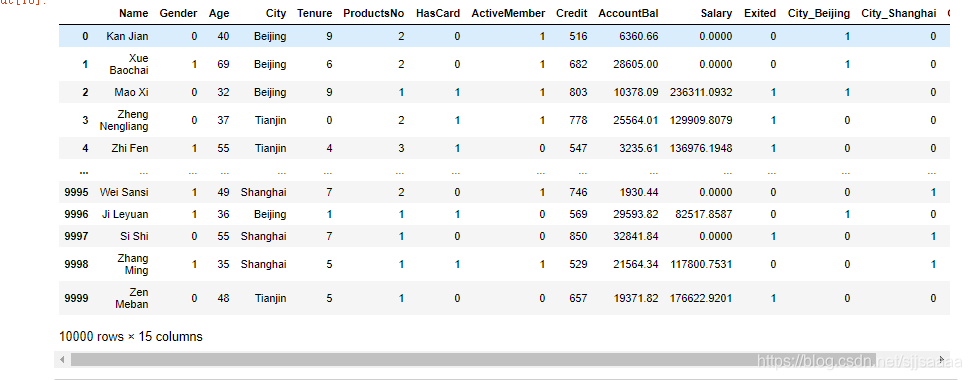
df_bank = df_bank.drop(columns='City')
#构建特征集和标签
X = df_bank.drop(columns=['Name','Exited'])
y = df_bank['Exited']
#划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=0)

2.先尝试使用逻辑回归算法
from sklearn.linear_model import LogisticRegression # 导入Sklearn模型
lr = LogisticRegression() # 逻辑回归模型
history = lr.fit(X_train,y_train) # 训练机器
print("逻辑回归测试集准确率 {:.2f}%".format(lr.score(X_test,y_test)*100))

3. 单隐层神经网络的Keras实现
Keras构建出来的神经网络通过模块组装在一起,各个深度学习元件都是Keras模块,比如:神经网络层、损失函数、优化器、参数初始化、激活函数、模型正则化、都是可以组合起来构建新模型的模块。
(1)用序贯模型构建网路
去除警告模块:
import os
import warnings
os.environ['PYTHONHASHSEED'] = '0'
warnings.filterwarnings('ignore')
首先导入Keras库
import keras # 导入Keras库
from keras.models import Sequential # 导入Keras序贯模型
from keras.layers import Dense # 导入Keras密集连接层
- 序贯模型,也可以叫做顺序模型,是最常用的深度网络层和层间的框架,也就是一个层接着一个层**,顺序地堆叠**。
- 密集层,是最常用的深度网络层的类型,也称为全连接层,既当前层和其下一层的所有的神经元之间全有链接。
搭建网络模型
#搭建神经网络
ann = Sequential()
ann.add(Dense(units=12, input_dim = 11,activation='relu')) #添加输入层
ann.add(Dense(units = 24, activation = 'relu')) #添加隐层
ann.add(Dense(units = 1,activation = 'sigmoid' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 682
682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











