







机器学习是通过现有的资料学习出一种假设函数,让这个假设函数尽可能的接近真实的函数。
那么我们如何验证假设函数与真是函数之间的关系?
对于一份验证数据D,我们把学习得到的假设函数h(x)应用到D上,会得到一个错误率。我们希望这个错误率与真实情况的错误率是接近的,这样当h(x)在我们所看到的资料上的错误率很低的时候,它在真实情况下的错误率也会很小。
原理就是霍夫丁不等式:
hoeffding 告诉我们,v是样本中事件A发生的比例,u是真实情况事件A发生的概率,那么这两个值相差很大的情况发生的概率是小于一个值的,而且这个值与样本数量有关系。
那么对于一个假设函数h(x),当验证集也就是样本的规模很大的情况下。它的错误率接近真实情况。
然而我们要从多个h(x)中选择一个最好也就是错误率最小的作为g(x),那么我们怎么保证在多个h(x)中每一个的误差率
Ein
与真实误差的误差率
Eout
相差很近呢。因为有可能在
ht(x)
的
Ein
很小但是
Eout
就很大,所以我们希望对于所有的h(x),
Ein
,
Eout
差距都不大。那么对于有M个h(x),
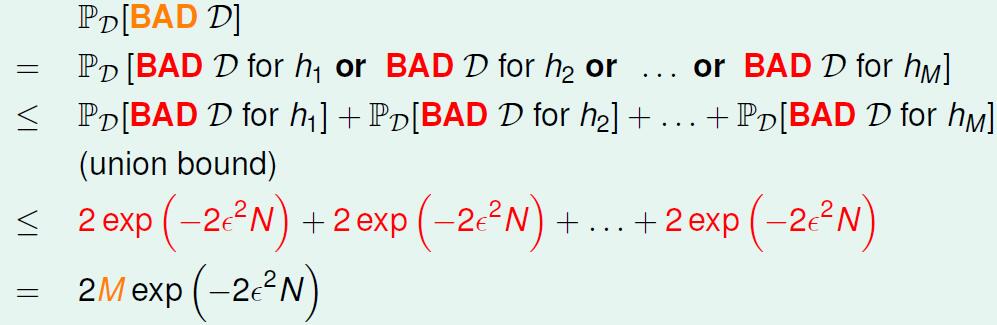
bad d 就是说,
Ein
,
Eout
这样我们就可以通过机器学习的算法在有限的H(x)中选择一个恰当的h(x),它的
Ein
最小。
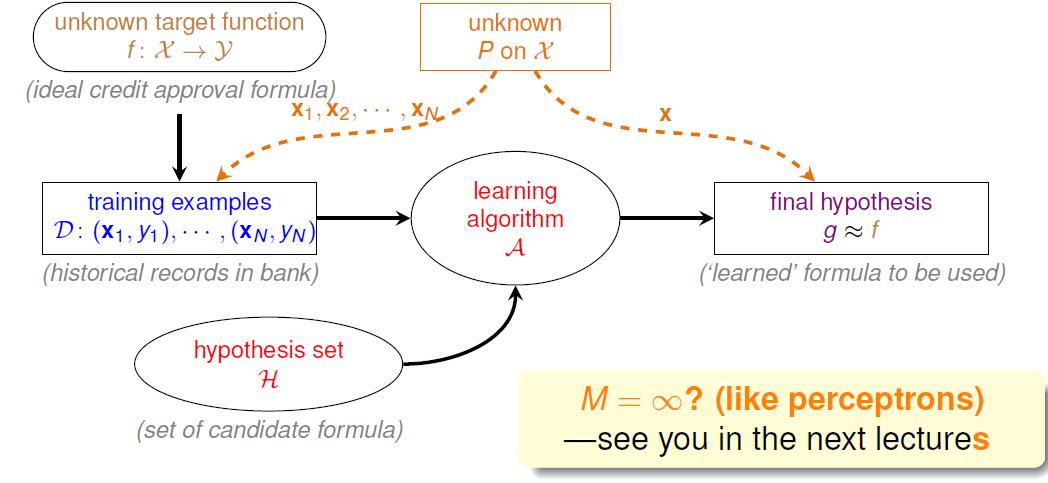
那么对于无穷的H(x)怎么办下次再讲。
我们注意到对于两个h(x)=sign(x), h(x) = sign(-x) 这两个的BAD D 是一样的因为只是翻转一下,正的变负,负的变正。















 960
960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









