







一、正则化
1、模型选择典型的方式就是正则化。正则化就是结构风险最小化策略的实现,就是在经验风险项中添加一个郑泽华想或者叫做惩罚项。
正则化项与模型的关系一般是模型复杂度越高,正则化项的值就会越大。
正则化项的作用就是平衡经验风险较小与模型复杂度较小。最好的结果就是经验风险和模型复杂度同时较小。
正则化的一般形式为:
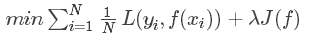
其中,第一项为经验风险项,第二项为正则化项。值λ是为了调整两者关系的系数。
二、交叉验证
通常情况下,我们做模型选择的时候将数据分为训练集、验证集和测试集。但是实际应用中,往往数据并不是很充足,这就导致分为三部分后每一部分数据量不足,这样计算选择得到的模型往往是不可用的。因此我们在这种情况下,可以选择使用交叉验证的方式解决数据量不足的情况。
1、简单地交叉验证
简单地交叉验证,就是指随机的将数据分为两部分,一部分为训练数据,一部分为测试数据,一般情况下比例为7:3。使用训练数据应用到各种模型的训练上得到多个不同的模型,然后利用测试数据计算每个模型的计算误差,最终选择误差最小的模型即为最优的模型。
2、S折交叉验证
S折交叉验证,就是将数据等比例的分为S份,然后选择其中的S-1份数据作为训练数据,剩余的一份作为测试数据,这样训练数据及测试数据就有S中选择,于是最终选择通过S次评测平均测试误差最小的模型为最优模型。
三、泛化能力
1、定义:泛化能力就是指所学到的模型对未知数据的预测能力,通常情况我们使用测试数据来验证模型的泛化能力,但是由于数据集有线,其并不能包含数据所有的可能情况,因此测试数据的测试结果并不能完全体现模型的泛化能力,这种评测结果并不可靠。
2、泛化误差
假设学到的模型为
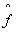
,则模型的泛化误差为:
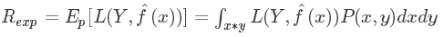
泛化误差反映了模型的泛化能力,模型选择中,泛化误差越小则模型越好。
3、泛化误差上界
通常学习方法的泛化能力分析是研究泛化误差得概率上界。比较两个学习方法的泛化误差上界来确定两个学习方法的优劣。其性质如下:
(1)泛化误差上界是样本容量的函数,样本容量越大,则泛化误差上界越趋于0。
(2)泛化误差上界是函数空间的函数,假设空间容量越大,模型就越难学,泛化误差上界就越大。















 1229
1229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









