







之前说到在M有限的情况下,也就时假设空间中的假设函数的个数有限的情况下,我们可以保证,当N足够大的时候,对于假设空间中的所有假设函数h(x), Ein和Eout 没有太大差别,那么我们就可以安心的选择一个 Ein 最小的假设函数,他的泛化能力得到了保证。
那么在M无限大的情况下呢?
当M无限大的时候,根据不等式, Ein和Eout 差距很大的可能性是非常大的,我们无法接受。那难道就不能做了么?当然不是。
我们在之前证明不等式的时候说
为什么这么说,因为对于这种一类的线比如A,B两条线,他们可能同时产生坏事情(指 Ein和Eout 差距很大)而不是说A产生了坏事情,或者A不产生坏事情而B产生了坏事情,那这样的概率就要比A.B同时产生坏事情的概率要大很多。
那么我们就从无穷的M中过度到,一共有几类的M,对应到PLA中就是看一共有几类的线。
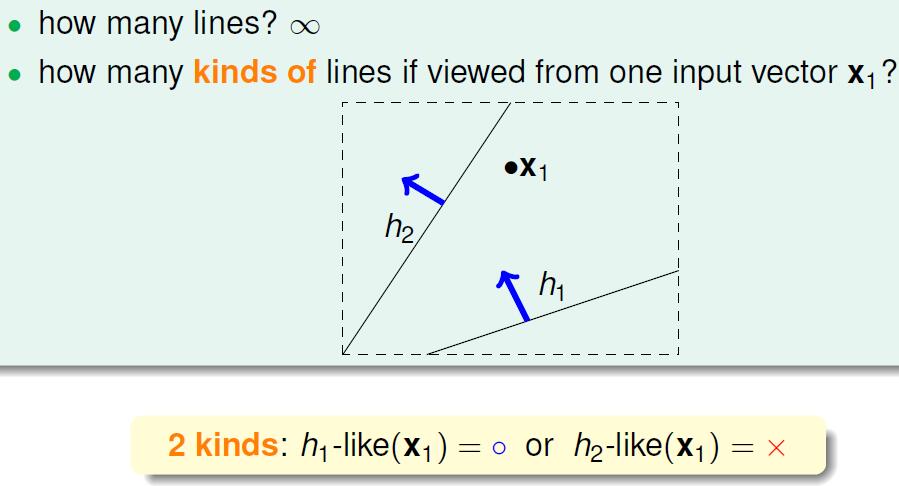

目前来看线的类别其实就是对点的划分的类别,当有N个点的时候,可以产生 2N 种点的划分(划分成圈和叉)但是有一些划分其实是做不到的,如下图。
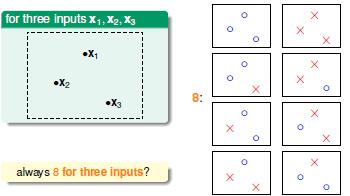
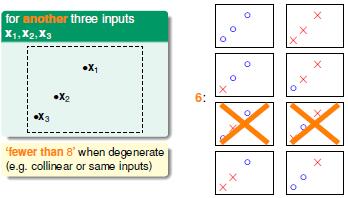
输入是三个点的时候有时候能划分成六类,最大的时候能划分出八类,也就是说点的划分其实与输入的顺序有关系。当输入点的个数是4的时候,有14种划分。其中有两种划分是无效的
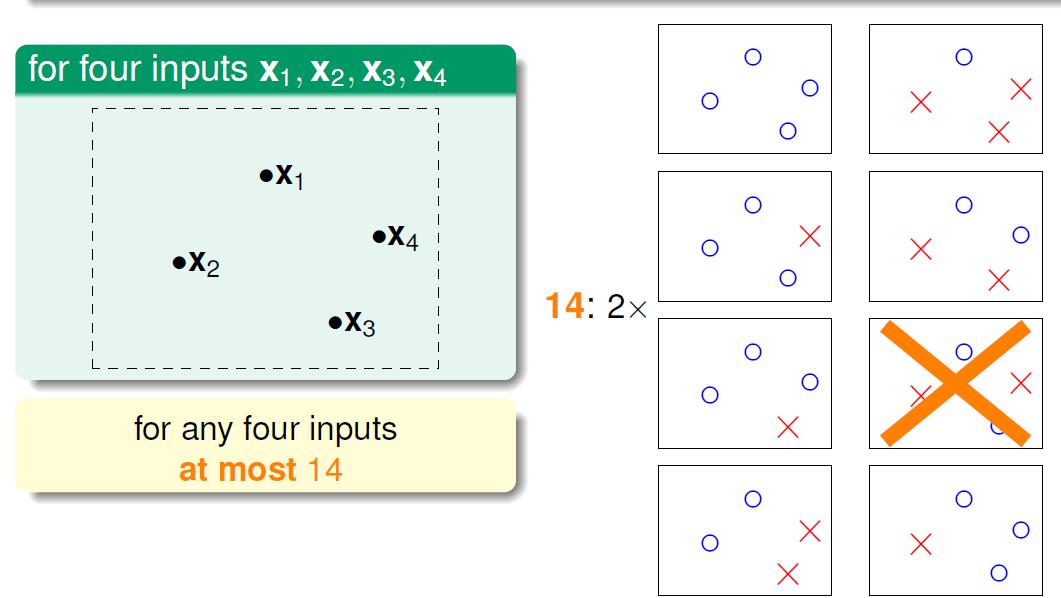
那么我们可以用这种有效的且有限的划分类的个数effective(N)代替原有的M
1. Dichotomies
那么这里我们用一个概念Dichotomies来表示hypothesis set 对大小为N的数据集的划分的集合。这样我们就可以用有限的Dichotomies来代替无限的M,因为Dichotomies集合中元素的个数不会超过
2N
因为数据集的输入个数不同会造成不同大小的Dichotomies,那么我们用一个growth function: mH(N) 来表示所有不同输入顺序的Dichotomies中,最大的那一个。 mH(N) 不会超过 2N 。那么 mH(N) 到底是多少呢。
我们先不看PLA所产生的假设空间(hypothesis set)也就是超平面上的直线,我们看看一些简单的假设空间的growth function.

这个假设空间的函数h(x)=sign(x-a)只能把某一个值a右面的点化为正的,所以对于N个点不同的划分个数N+1个。
2. break point
那么对于PLA的假设空间的直线,我们看当N=1时也就是只有一个点的时候
mH(N)=2
当N=2的时候
mH(N)=4
当N=3的时候
mH(N)=8
而当N=4时
mH(N)=14≤2N
那么N=4就是break point,因为4个点的时候无法被shattered,(shattered的含义就是说,对于N个输入点,他的
2N
种情况都可以出现,都是有效的划分)
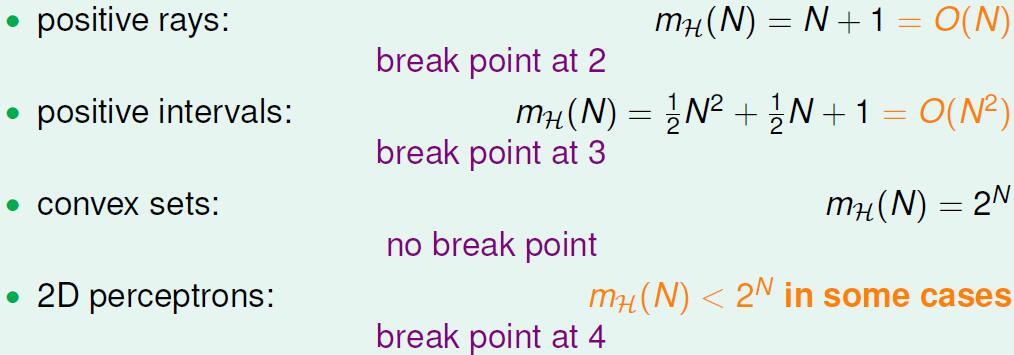
对于其他的假设空间,对应着不同的break point 如上图。比如对于positive rays 的假设空间,break point 是N=2,因为N=1的时候 21 两种情况都可以出现,N=2的时候 mH(N)=N+1=3≤22 , 所以N=2 是break point.
现在我们考虑更加一般的情况,我们知道数据样本的数量N,知道break point 那么我们能不能得到对应的 mH(N) 注意这里我们已经忽略了假设空间。
举个例子,假设现在我们已知break point = 2, 也就是说任意两个点他们无法shattered.(也就是他们所有的
22=4
种情况无法同时出现),那么如下图所示对应不同的N,
mH(N)
的取值:

根据这个例子我们就有一种感觉,实际上break point限制了
mH(N)
的值,尤其是当N大于break point k 的时候。
3. bounding function
当我们知道了k 对于
mH(N)
有限制的时候,我们就想是不是可以让
mH(N)
小于等于一个多项式,那么这样我们就可以放心的说
mH(N)
也是个多项式了。于是有了bounding function 的定义:
根据之前的结论我们可以填出来一张表:
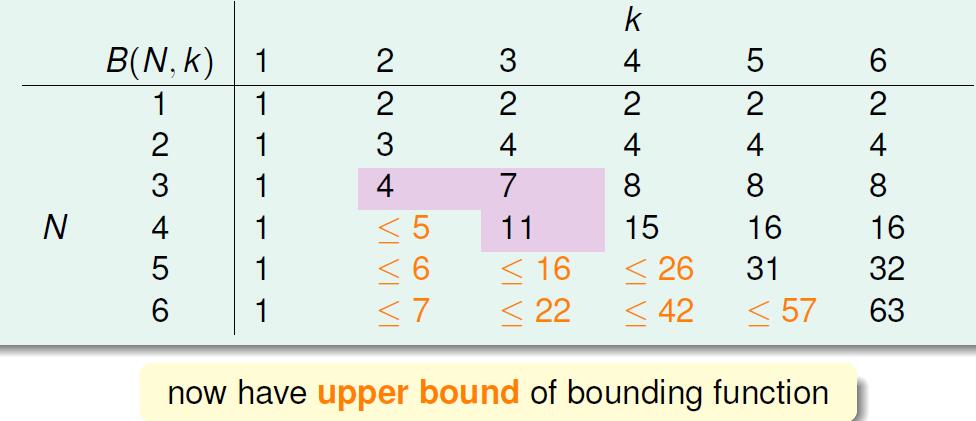
那么就可以得出结论:
VC bound
现在我们就有了
mH(N)
上界,就可以吧
mH(N)
应用到hoeffding 不等式中了,当然不是简单的带入还需要做一些复杂的处理最后的式子就是VC bounding:
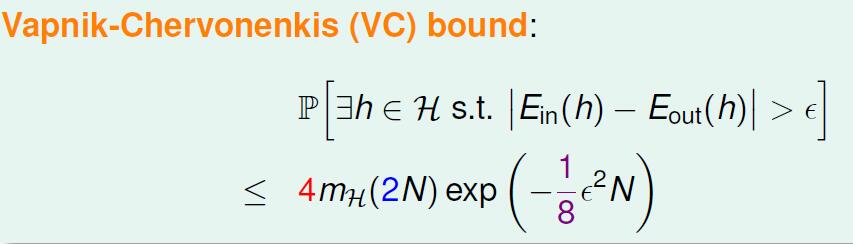















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









