







文章目录
摘要
本篇文章,由笔者最初遇到的decode报错开始,叙述笔者如何解决这个bug,并深入源码理清 decode 与 batch_decode的区别。
引出原因
最开始遇到了一个如下的报错,如果你运行我在下述给出的代码,你也能得到一个这样的报错信息。这个问题是由batch_decode引起的。
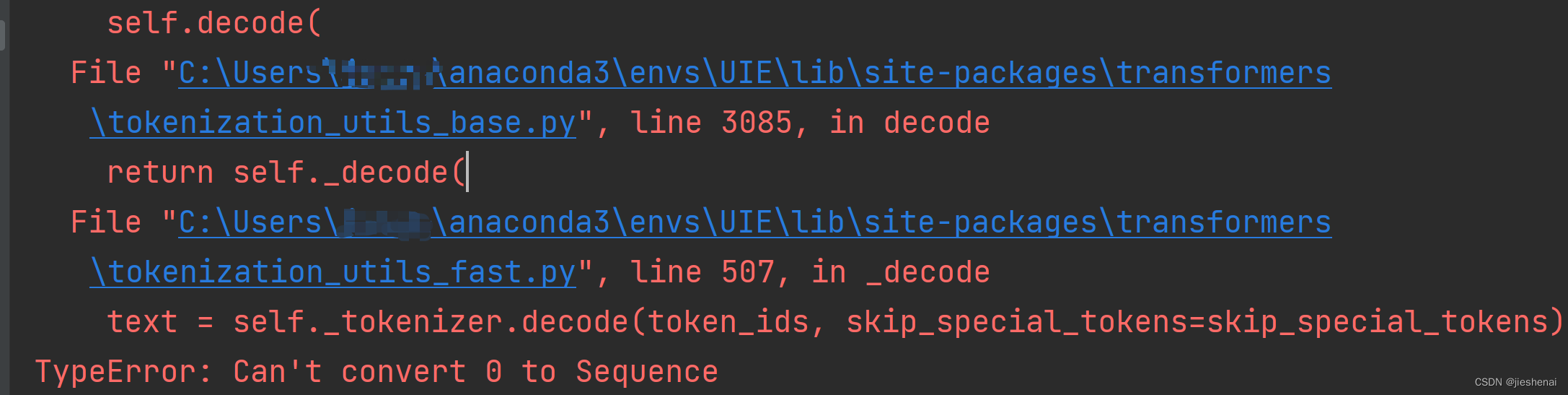
报错信息
File "C:\Users\anaconda3\envs\lib\site-packages\transformers\tokenization_utils_base.py", line 3047, in <listcomp>
self.decode(
File "C:\Users\anaconda3\envs\lib\site-packages\transformers\tokenization_utils_base.py", line 3085, in decode
return self._decode(
File "C:\Users\anaconda3\envs\lib\site-packages\transformers\tokenization_utils_fast.py", line 507, in _decode
text = self._tokenizer.decode(token_ids, skip_special_tokens=skip_special_tokens)
TypeError: Can't convert 0 to Sequence
通用代码部分:
import numpy as np
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("任意一个预训练模型")
一个会报错的代码
arr = np.array(
[0]
)
print(tokenizer.batch_decode(arr))
笔者刚开始想:
既然报错信息是decode函数报错,故我直接
print(tokenizer.decode(arr))
然而我惊讶的发现,这行代码居然能成功执行并输出 <pad>。
凭借笔者现在给出的精简代码,读者可以很容易的发现是 batch_decode的问题。但笔者当时所在的项目代码量有点大,于是笔者一步步debug,才最终发现程序在 batch_decode这个函数所在位置崩溃。(我绝对不会告诉你们,当天晚上遇到这个bug之后,我直接放弃了,打游戏去了。)
我们在使用 decode 与 batch_decode 的过程中,发现任何可以使用 decode 的地方,都可以用 batch_decode 来代替。其实这种观点并不总是正确的。举个反例:numpy的一维数据,就不适用。笔者在下文会详细解释这个原因 。
最初报错的解决办法
将 numpy 的一维转成多维数据,即可解决这个bug。
arr = np.array(
[[0]]
)
print(tokenizer.batch_decode(arr))
希望此方法,已经解决了您的问题,若您对该bug的细节感兴趣,可以继续往下阅读。
这是一个 numpy 类型的 bug。其他的 torch.tensor,python list,皆不存在此问题。
batch_decode 源码
def batch_decode(
self,
sequences: Union[List[int], List[List[int]], "np.ndarray", "torch.Tensor", "tf.Tensor"],
skip_special_tokens: bool = False,
clean_up_tokenization_spaces: bool = True,
**kwargs
) -> List[str]:
return [
self.decode(
seq,
skip_special_tokens=skip_special_tokens,
clean_up_tokenization_spaces=clean_up_tokenization_spaces,
**kwargs,
)
for seq in sequences
]
decode: 解码一维数据
batch_decode:解码多维数据
通过浏览源码发现,batch_decode 使用了一个列表推导式调用 decode 进行解码。所以这就是: 我们时常将batch_decode 与 decode混用的原因。
decode 和 batch_decode 都可以成功运行的例子
tensor_arr = [0, 1, 2, 3]
print(tokenizer.decode(tensor_arr))
print(tokenizer.batch_decode(tensor_arr))
输出结果
<pad></s><unk>
['<pad>', '</s>', '<unk>', '']
decode 和 batch_decode 不能同时成功运行的例子
不支持 numpy 的一维数据
np_arr = np.array([0, 1, 2, 3])
print(tokenizer.decode(np_arr))
print(tokenizer.batch_decode(np_arr))
只需要将上述的列表转成 numpy,就会报错。(转成 torch.tensor 不会报错)
源码将输入转成 python list
这里给出的一些函数都是源码,若您不感兴趣,建议直接看后面的结论。
# Convert inputs to python lists
token_ids = to_py_obj(token_ids)
def to_py_obj(obj):
"""
Convert a TensorFlow tensor, PyTorch tensor, Numpy array or python list to a python list.
"""
if isinstance(obj, (dict, UserDict)):
return {k: to_py_obj(v) for k, v in obj.items()}
elif isinstance(obj, (list, tuple)):
return [to_py_obj(o) for o in obj]
elif is_tf_available() and _is_tensorflow(obj):
return obj.numpy().tolist()
elif is_torch_available() and _is_torch(obj):
return obj.detach().cpu().tolist()
elif isinstance(obj, np.ndarray):
return obj.tolist()
else:
return obj
tokenizer.decode 会将输入 (类型为:TensorFlow tensor, PyTorch tensor, Numpy array or python list) 都转成 list,再进行解码操作。
_decode中,会将int型的整数也转成 python list。
if isinstance(token_ids, int):
token_ids = [token_ids]
将对象转成 python list时,使用isinstance 根据对象类型转成 python list。
np_arr = np.array([0, 1, 2, 3])
for item in np_arr:
print(item, type(item))
numpy 一维数据,单个item 的类型是 numpy.int32, 源码没有把这个类型转成list, 从而引发错误。(笔者觉得huggingface 可以专门针对 numpy.int32这个类型, 实现将其转成list,但是huggingface并没有做这项工作。)
(在此感谢您的浏览,若您觉得这些工作帮助到了您,可以给我们一个赞,这样笔者会感到他工作是有意义的!)
















 282
282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











