







00x1
论文标题:Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks
来源:清华大学Jittor
00x2
文章重点通过引入external attention来代替self-attention,并且external attention能够贯穿所有样本,学习到所有样本共享的特征。为此,我们需要引入一个外部的SxD的记忆单元M。
They(two memories) are independent of individual samples and shared across the entire dataset, which plays a strong regularization role and improves the generalization capability of the attention mechanism.
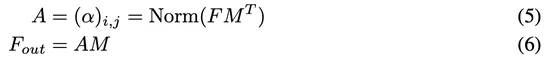
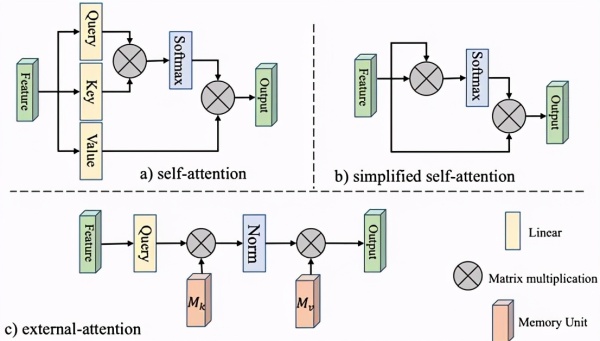
引入两个不同的记忆单元用于增强External-attention的表达能力,
00x3
这个论文挺有意思。引入了两个记忆单元隐式地共享了样本上的特征。















 5135
5135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









