






论文解读《超越自注意力机制:视觉任务中使用两个线性层的外部注意力机制》
期刊名:CVPR2021
代码:代码地址
论文地址:论文地址
一、摘要:
1) 在 自注意力机制 中,使用计算特征图的加权,来源于成对关联,以捕获单个样本的长期依赖性。平方复杂度以及忽略对不同特征图之间的潜在关联。
2) 外部注意力机制 ,基于两个外部的、小的共享存储模块,两个线性层和归一化层BN。多头机制融入到外部注意力,即多头外部注意力。
二、介绍
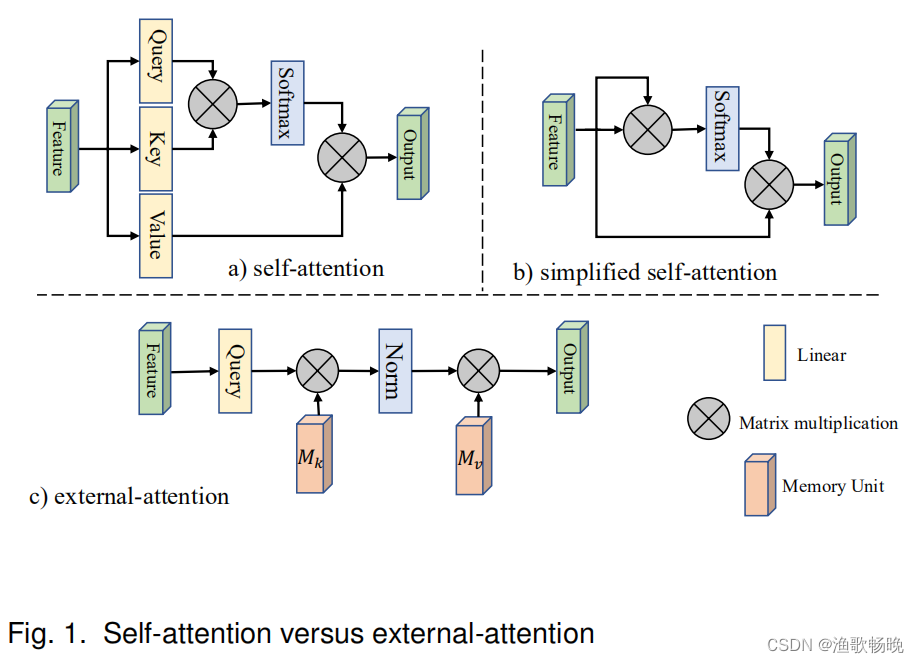
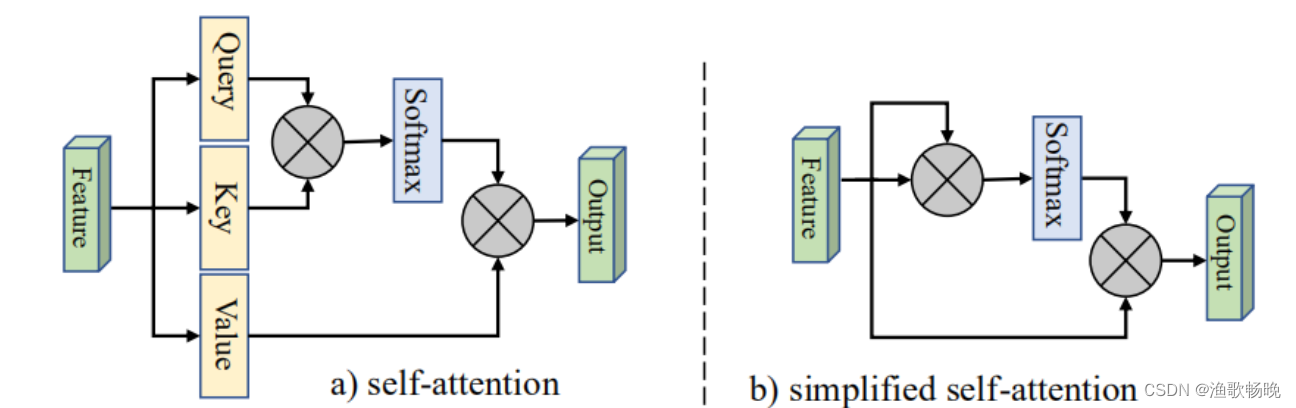
1、 自注意力: self query vectors(自查询向量)+ self key vectors(自键向量)之间的 亲和度(affinities) 计算attention map(注意力特征), attention map(注意力特征) 对 self value vectors(自值向量)进行加权来生成一个 新的特征图 。如 图1a) 所示。
计算复杂度:O(dN^2)
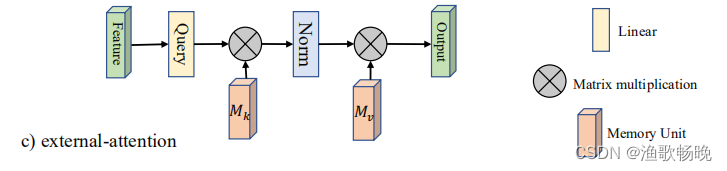
2、 外部注意力:首先通过计算self query vectors(自查询向量)与一个external learnable key memory(外部键存储模块)之间的亲和度来计算(注意力特征) attentionmap,然后通过将该 attention map(注意力特征) 与另一个 external learnable value memory(外部可学习值存储模块) 相乘来得到一个精细的特征图 (featuremap)。
计算复杂度:O(dSN); d和S是超参数,该算法在像素数上是线性的。
3、 两个存储模块通过线性层实现,在整个数据集中共享参数,具有强大的正则作用。
三、方法:

3.1 Self-Attention 自注意力
自注意力机制(可见图1a)。给定一个输入特征:F∈R^N*d,其中N是元素数量(或图像像素数量),d是特征维度数,自注意力线性投射输入为一个query(查询)矩阵、一个key(键)矩阵和一个value(值)矩阵。
自注意力公式为:
给定一个输入特征 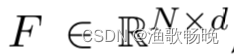 ,其中N是元素数量(或图像像素数量),d是特征维度数,自注意力线性投射输入为一个query矩阵
,其中N是元素数量(或图像像素数量),d是特征维度数,自注意力线性投射输入为一个query矩阵
,一个key矩阵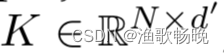
和一个value矩阵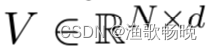
。
自注意力公式为:
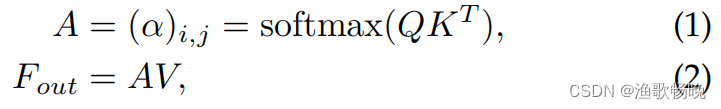
A∈R^NXN是注意力矩阵,是第i个和第j个元素的成对亲和度值。
计算复杂度:O(dN^2)。
3.2 External Attention 外部注意力
输入像素和一个external memory(外部存储)单元M∈R^SXd 的注意力,公式为:
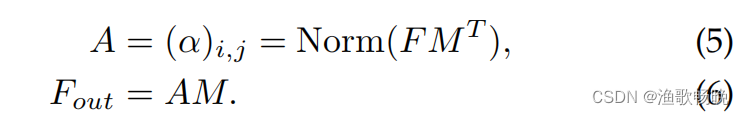
和自注意力不同,等式(5)中的αi,j是第i个像素和M第j行的相似度,其中M是一个独立于输入的可学习参数,其作为整个训练数据集的存储模块。
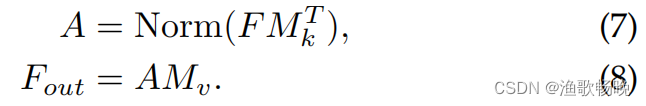
外部注意力的计算复杂度是O(dSN);d和S是超参数,该算法在像素数上是线性的。
3.3 正则化:
1) 自注意力中使用Softmax去归一化注意力特征,因此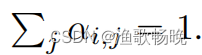
2) 然而,注意力特征是通过矩阵乘法计算出来的。与余弦相似度不同,注意力特征对输入特征的尺寸非常敏感。
3) 选用double-normalization,它其对列和行分别计算,分别归一化列和行
4) 用了 softmax + L1 norm 的这种 double normalization 的方式
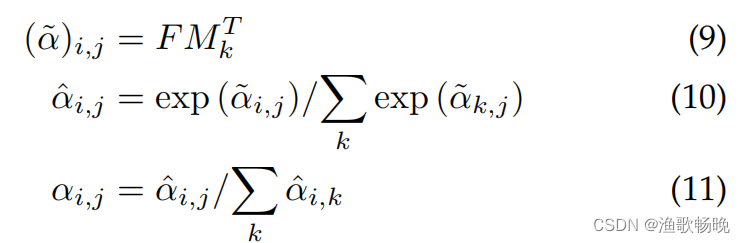
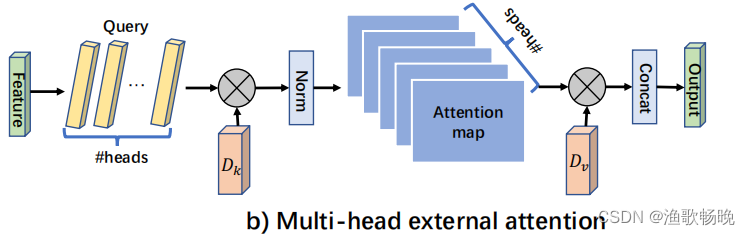
3.4 Multi-head external attention 多头外部注意力
如算法2和图2所示。

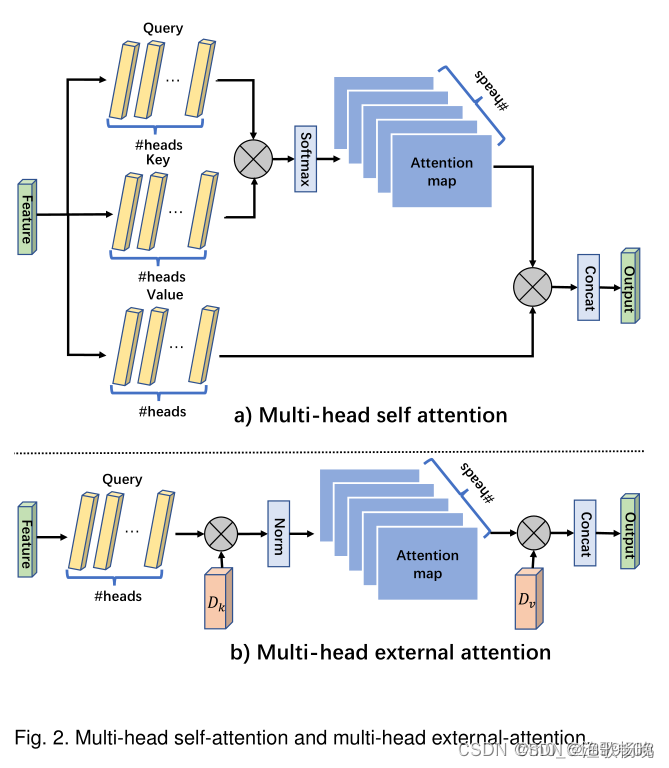
多头外部注意力可以写成:

其中hi是第i个头,H是头的数量,Wo是一个用来保持输入输出维度一致的线性转换矩阵。
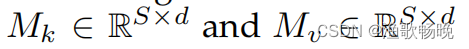 是不同头共享的内存单元。
是不同头共享的内存单元。
这种架构的灵活性能够平衡共享存储单元中头H的数量和元素S的数量。
四、实验部分
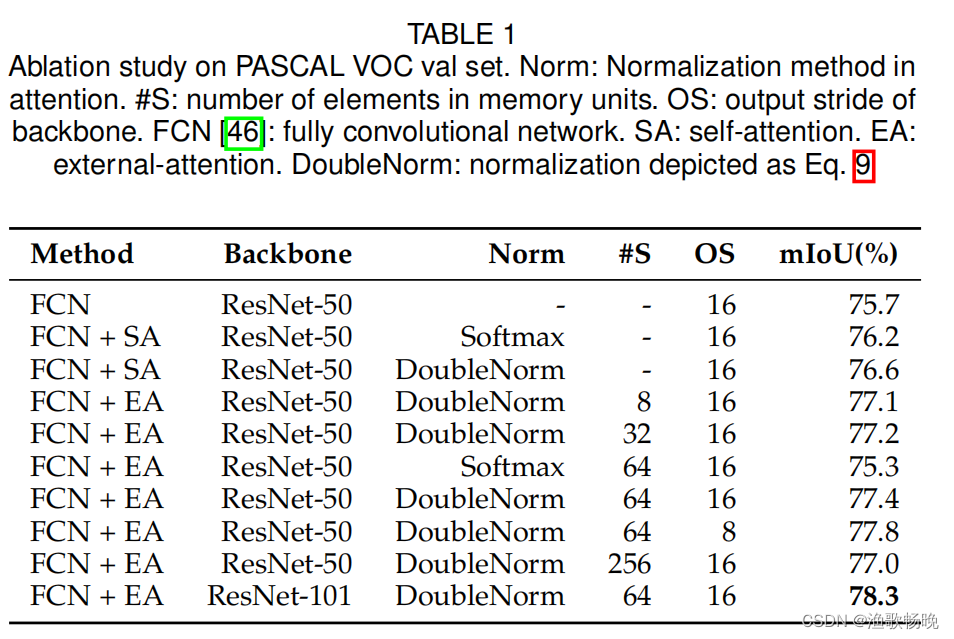
4.1 消融实验
图3为消融研究中使用的架构,该架构以FCN为特征主干。批大小设置为12,总迭代次数设置为30000。
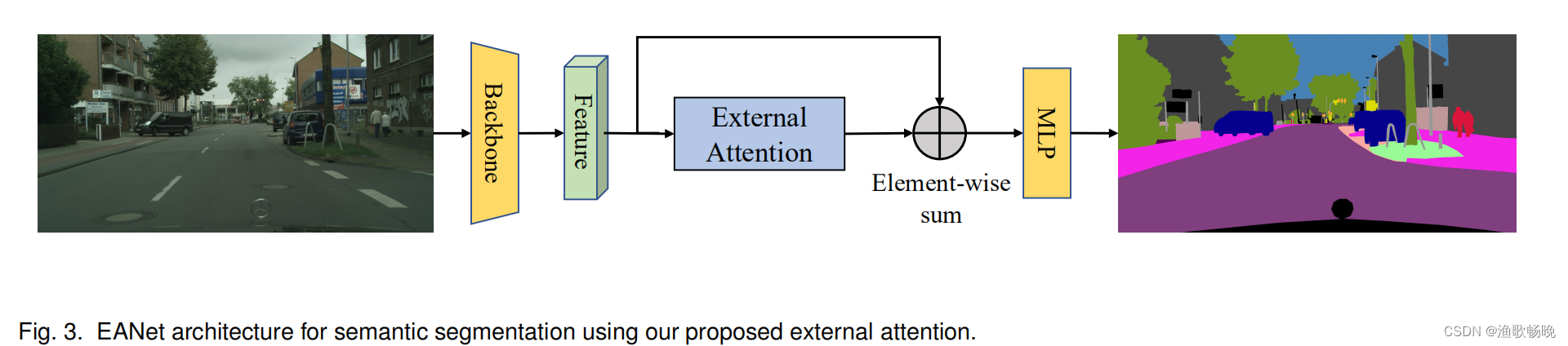
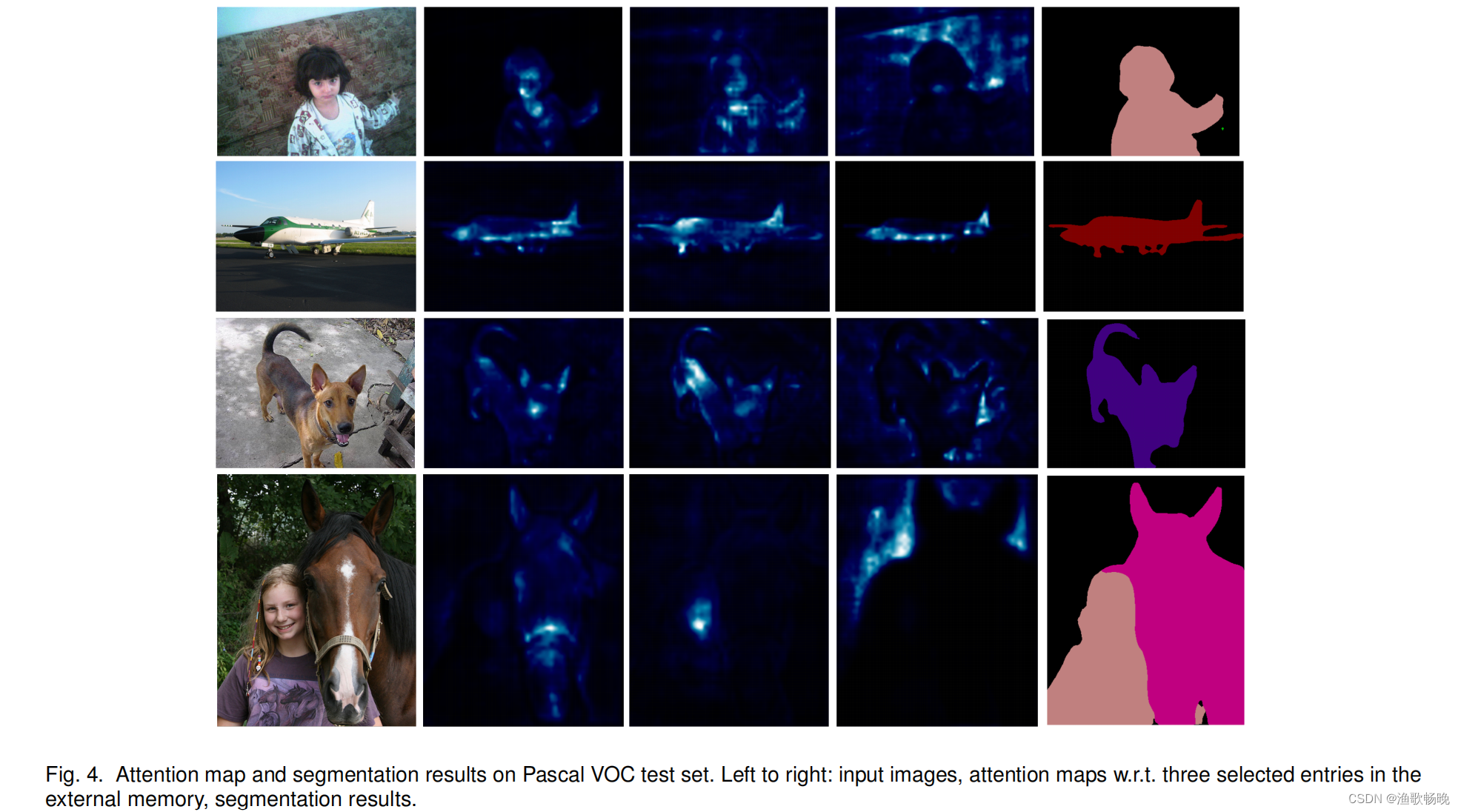
4.2 可视化分析
使用外部注意力进行分割 图3) 和使用多头外部注意力进行分类 分别如图4和图5 所示。
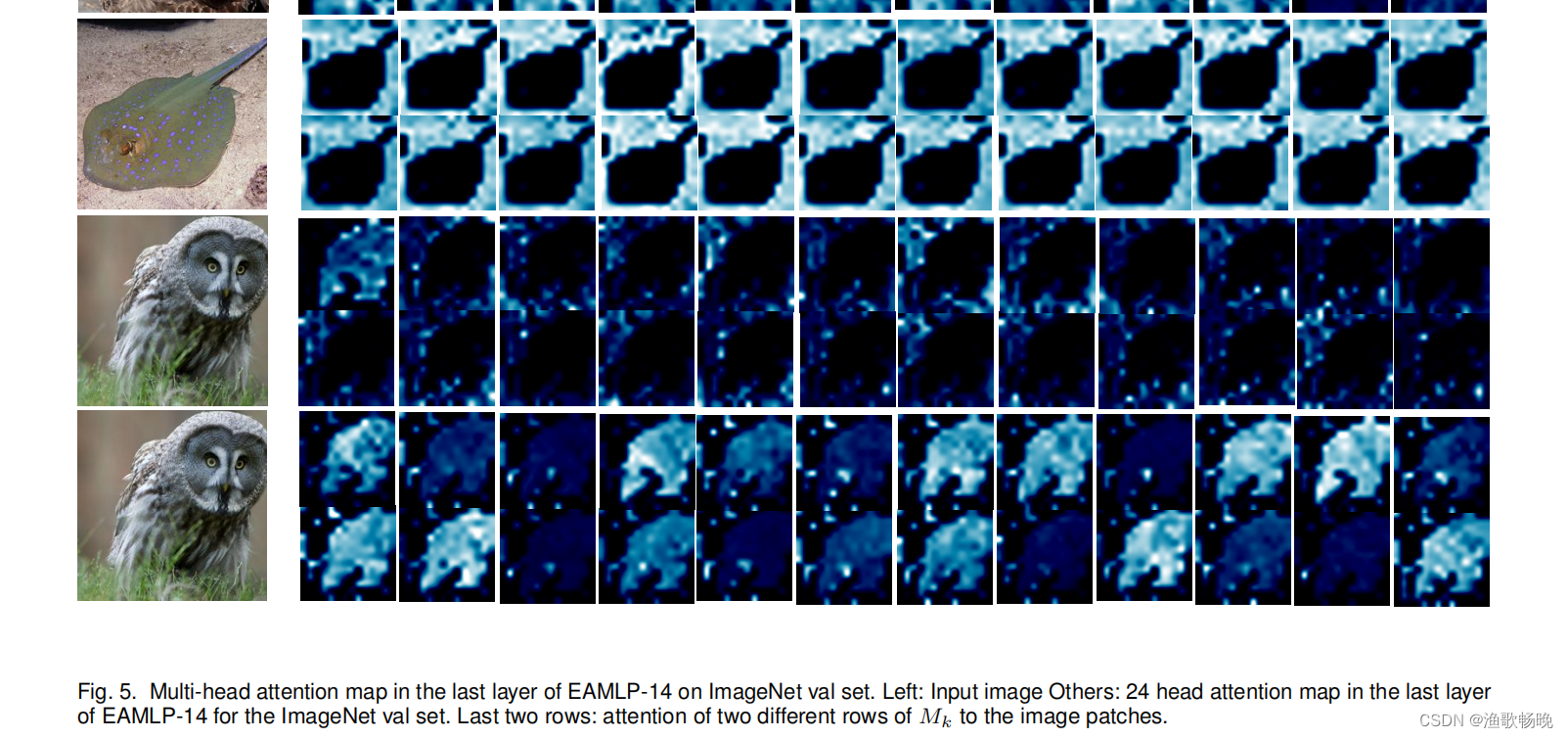
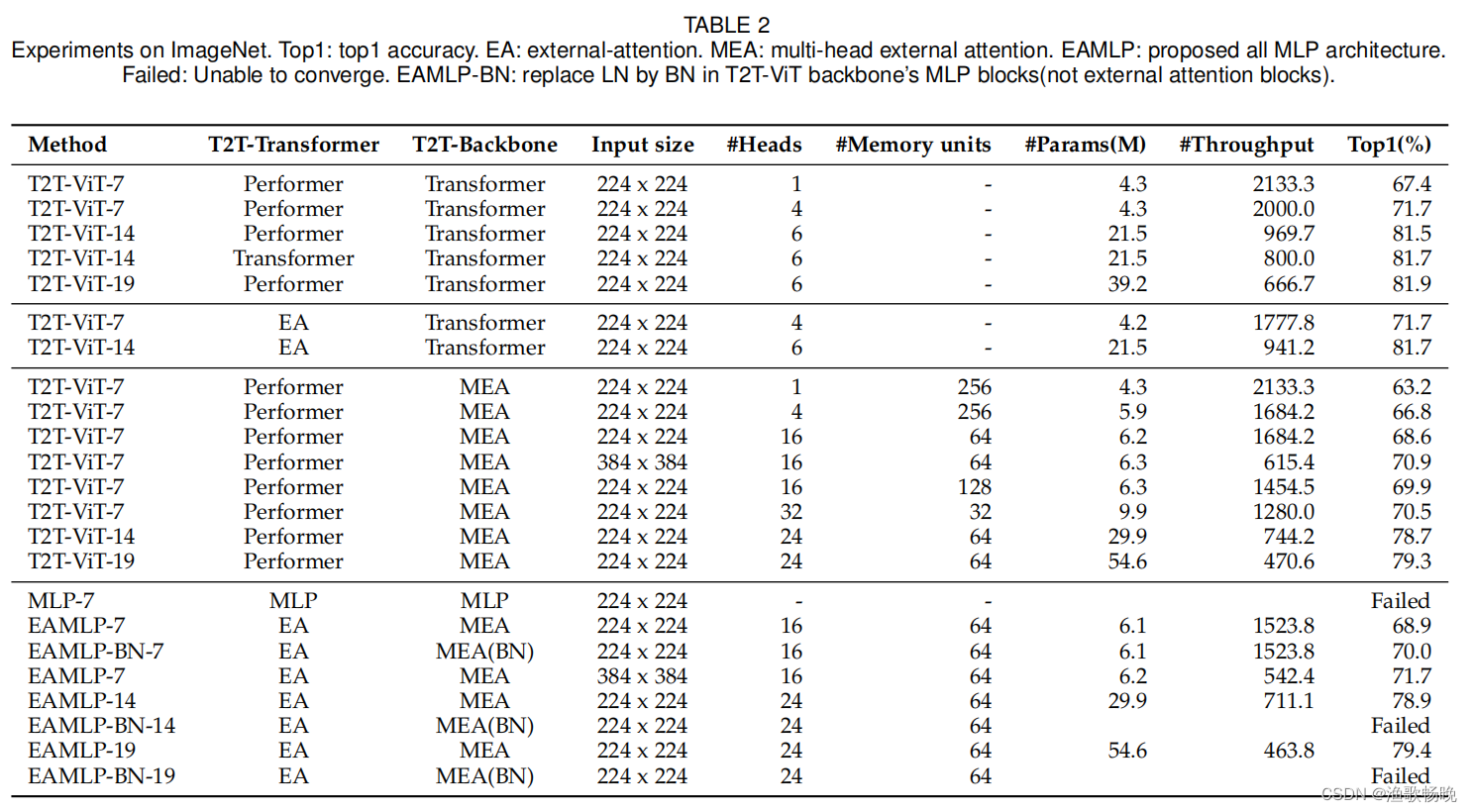
4.3 图像分类
ImageNet-1K是一个用于图像分类的广泛使用的数据集。
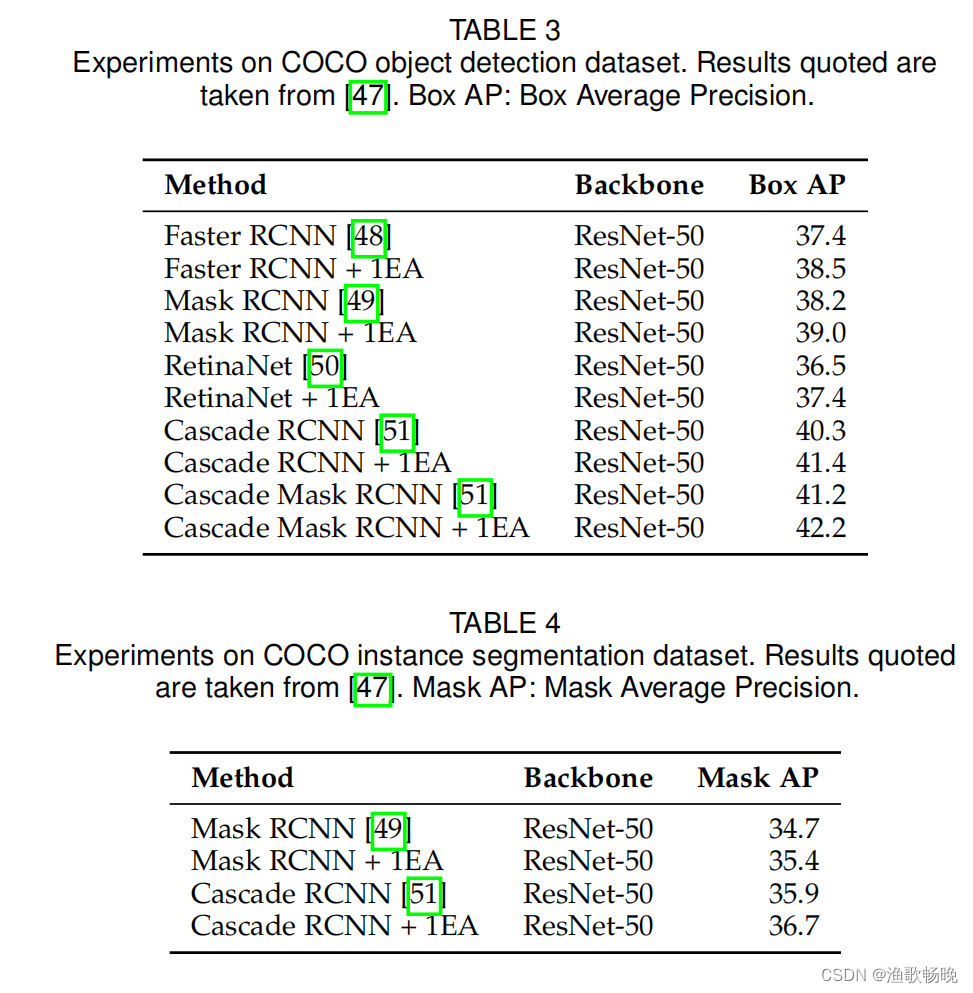
4.4 目标检测和实例分割
MS COCO数据集是对象检测和实例分割的流行基准。它包含来自80个类别的20多万张图像和50多万个注释对象实例。
MMDetection是一个被广泛使用的对象检测和实例分割工具集。我们使用带有RestNet-50骨干的MMDetection进行对象检测和实例分割实验,并将其应用于COCO数据集。在残差阶段结束时才增加了外部注意力。
五、结论
1) 本文提出了一种新型的、轻量级的、有效的、适用于各种视觉任务的注意机制——外部注意力。外部注意力所采用的两个外部内存单元可以看作是整个数据集的字典,能够学习更多的输入的代表性特征,同时降低计算代价。
2) 希望外部注意力能够激发它在其他领域的实际应用和研究,比如自然语言处理。
外部注意力
class External_attention(nn.Module):##外部注意力核心模块
def __init__(self, c):
super(External_attention, self).__init__()
self.conv1 = nn.Conv2d(c, c, 1)
self.k = 64
self.linear_0 = nn.Conv1d(c, self.k, 1, bias=False)
self.linear_1 = nn.Conv1d(self.k, c, 1, bias=False)
self.linear_1.weight.data = self.linear_0.weight.data.permute(1, 0, 2)
self.conv2 = nn.Sequential(
nn.Conv2d(c, c, 1, bias=False),
norm_layer(c))
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.Conv1d):
n = m.kernel_size[0] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, _BatchNorm):
m.weight.data.fill_(1)
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
idn = x
x = self.conv1(x) #self.conv1 = nn.Conv2d(c, c, 1)
b, c, h, w = x.size()
n = h*w
x = x.view(b, c, h*w) # b * c * n
attn = self.linear_0(x) # b, k, n self.linear_0 = nn.Conv1d(c, self.k, 1, bias=False)
#linear_0是第一个memory unit
attn = F.softmax(attn, dim=-1) # b, k, n
attn = attn / (1e-9 + attn.sum(dim=1, keepdim=True)) # # b, k, n double-normalization
x = self.linear_1(attn) # b, c, n self.linear_1 = nn.Conv1d(self.k, c, 1, bias=False)
#linear_1是第二个memory unit
x = x.view(b, c, h, w)
x = self.conv2(x) #self.conv2 = nn.Sequential(
# nn.Conv2d(c, c, 1, bias=False),
# norm_layer(c))
x = x + idn
x = F.relu(x)
return x

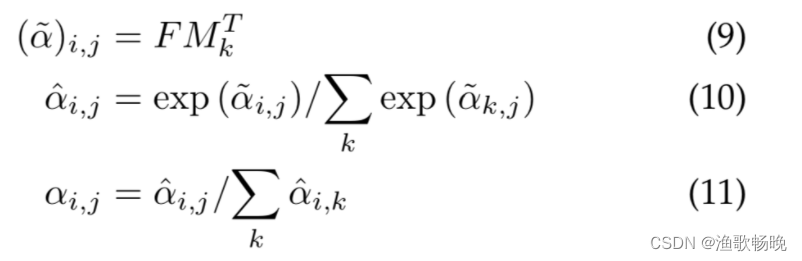
多头外部注意力
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
assert dim % num_heads == 0
self.coef = 4
self.trans_dims = nn.Linear(dim, dim * self.coef)
self.num_heads = self.num_heads * self.coef
self.k = 256 // self.coef
self.linear_0 = nn.Linear(dim * self.coef // self.num_heads, self.k)
self.linear_1 = nn.Linear(self.k, dim * self.coef // self.num_heads)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim * self.coef, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
x = self.trans_dims(x) # B, N, C
x = x.view(B, N, self.num_heads, -1).permute(0, 2, 1, 3)
attn = self.linear_0(x)
attn = attn.softmax(dim=-2)
attn = attn / (1e-9 + attn.sum(dim=-1, keepdim=True))
attn = self.attn_drop(attn)
x = self.linear_1(attn).permute(0,2,1,3).reshape(B, N, -1)
x = self.proj(x)
x = self.proj_drop(x)
return x

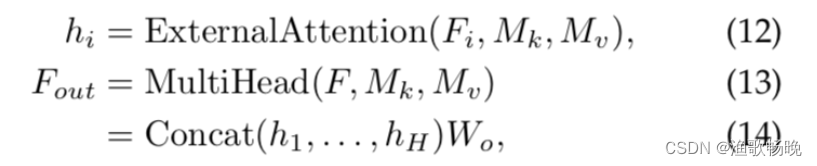















 2012
2012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









