







abstract
传统注意力机制是一个二次的复杂度(quadratic complexity),这篇论文提出的外部复杂度是一个线性的,计算复杂度低而且内存消耗小。
introduction

- 外部注意力机制复杂度低,精读高
- 多头外部注意力机制,构建了一个MLP的架构
- 大量的实验
注:多层感知器(Multilayer Perceptron,缩写MLP)是一种前向结构的人工神经网络,映射一组输入向量到一组输出向量
method
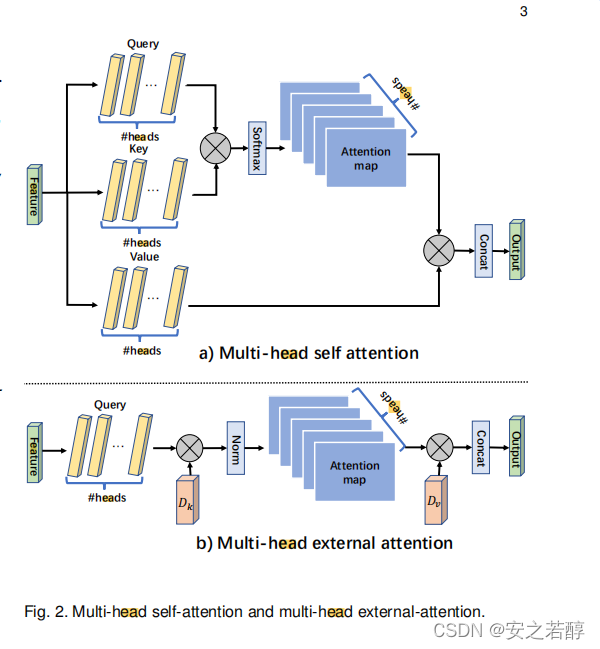
这个图是对比self-attention和external-attention的
这个公式比较好理解,可以看一看(虽然可能并不太好写
)
传统self-attention:
A
=
(
α
)
i
,
j
=
s
o
f
t
m
a
x
(
Q
K
T
)
A=(\alpha)_{i,j}=softmax(QK^T)
A=(α)i,j=softmax(QKT)
(Q是query K是key)
F
o
u
t
=
A
V
F_{out}=AV
Fout=AV
(V是value)
mulit-head external attention:
A
=
(
α
)
i
,
j
=
N
o
r
m
(
F
M
T
K
)
A=(\alpha)_{i,j}=Norm(FM^K_T)
A=(α)i,j=Norm(FMTK)
F o u t = A M V F_{out}=AM_V Fout=AMV
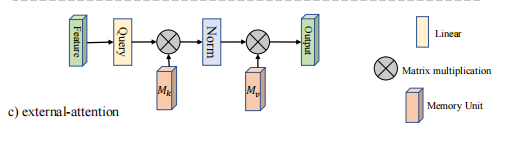
这样利用额外的空间就是一个线性的了
experiment
这篇文章感觉提出来的东西不多,但是实验真的非常多,在主要是在不同的领域都进行了实验
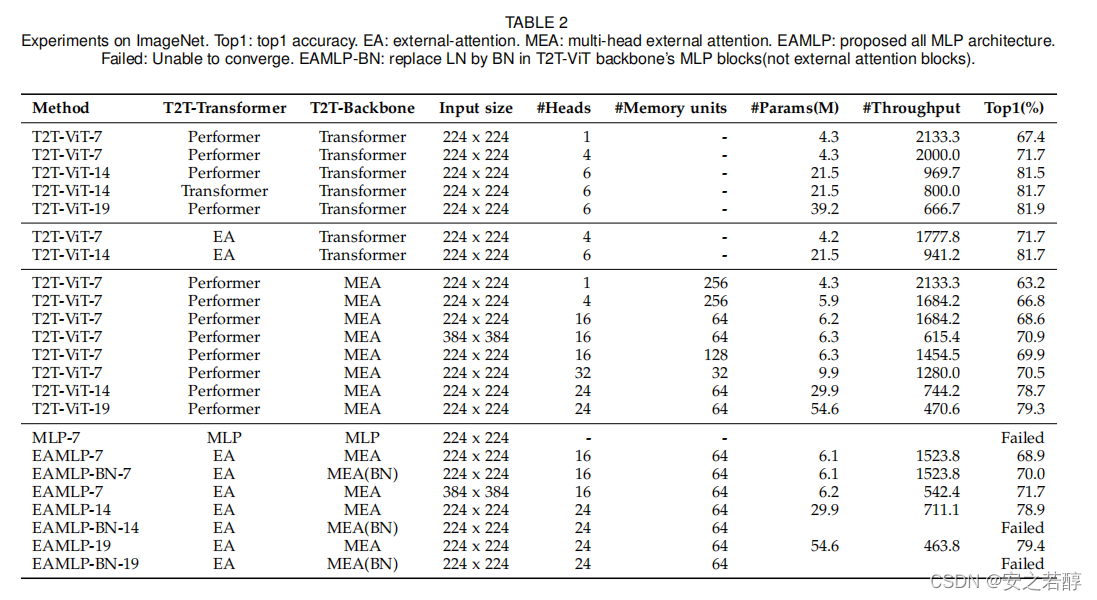
这里主要是跟传统注意力做对比
底下主要就是跟其他网络了
conclusion
主要也是说了说自己提出了一个注意力机制
我是分隔线
再往底下翻了翻,发现居然是清华团队写的论文、、、、
可能感觉只提出了一个自注意力机制没有那么强,但是后面的实验可谓是涉及到了各个领域(感觉就是比较严谨的实验)
后来参考了一篇大佬的博客
大佬说它没有做消融实验(但是它确实有一个标题是ablation study),不过看看底下的表格的话确实好像没有,虽然结果也非常不错。
大佬说用一层来储存信息有点太草率了,虽然结果还不错。但是有道理,可能要研究的就是简化一下这个机制,所以肯定是越变越草率?(buzhidao T_T)
小白的总结:
还行吧这篇读下来,感觉以后可能速读的时候也要看看实验了(因为虽然每个实验的结果肯定都是自己好,但是不同的论文会用不同的dataset和不同的ablation study )所以还是看看。还有就是公式那块,有些推导可能没有那么重要,但是一些基本的输入输出的维度还是也要看看的。















 1310
1310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









