







 本文详细介绍了OpenCV中的stitching_detail算法,包括程序运行流程、接口介绍、代码分析等。从特征点检测、匹配、运动估计、光束平均法、波形校正到图像融合等步骤,深入探讨了图像拼接的各个环节,并提供了参数使用示例。
本文详细介绍了OpenCV中的stitching_detail算法,包括程序运行流程、接口介绍、代码分析等。从特征点检测、匹配、运动估计、光束平均法、波形校正到图像融合等步骤,深入探讨了图像拼接的各个环节,并提供了参数使用示例。
已经不负责图像拼接相关工作,有技术问题请自己解决,谢谢。
一、stitching_detail程序运行流程
1.命令行调用程序,输入源图像以及程序的参数
2.特征点检测,判断是使用surf还是orb,默认是surf。
3.对图像的特征点进行匹配,使用最近邻和次近邻方法,将两个最优的匹配的置信度保存下来。
4.对图像进行排序以及将置信度高的图像保存到同一个集合中,删除置信度比较低的图像间的匹配,得到能正确匹配的图像序列。这样将置信度高于门限的所有匹配合并到一个集合中。
5.对所有图像进行相机参数粗略估计,然后求出旋转矩阵
6.使用光束平均法进一步精准的估计出旋转矩阵。
7.波形校正,水平或者垂直
8.拼接
9.融合,多频段融合,光照补偿,
二、stitching_detail程序接口介绍
img1 img2 img3 输入图像
--preview 以预览模式运行程序,比正常模式要快,但输出图像分辨率低,拼接的分辨率compose_megapix 设置为0.6
--try_gpu (yes|no) 是否使用GPU(图形处理器),默认为no
/* 运动估计参数 */
--work_megapix <--work_megapix <float>> 图像匹配的分辨率大小,图像的面积尺寸变为work_megapix*100000,默认为0.6
--features (surf|orb) 选择surf或者orb算法进行特征点计算,默认为surf
--match_conf <float> 特征点检测置信等级,最近邻匹配距离与次近邻匹配距离的比值,surf默认为0.65,orb默认为0.3
--conf_thresh <float> 两幅图来自同一全景图的置信度,默认为1.0
--ba (reproj|ray) 光束平均法的误差函数选择,默认是ray方法
--ba_refine_mask (mask) ---------------
--wave_correct (no|horiz|vert) 波形校验 水平,垂直或者没有 默认是horiz
--save_graph <file_name> 将匹配的图形以点的形式保存到文件中, Nm代表匹配的数量,NI代表正确匹配的数量,C表示置信度
/*图像融合参数:*/
--warp (plane|cylindrical|spherical|fisheye|stereographic|compressedPlaneA2B1|compressedPlaneA1.5B1|compressedPlanePortraitA2B1
|compressedPlanePortraitA1.5B1|paniniA2B1|paniniA1.5B1|paniniPortraitA2B1|paniniPortraitA1.5B1|mercator|transverseMercator)
选择融合的平面,默认是球形
--seam_megapix <float> 拼接缝像素的大小 默认是0.1 ------------
--seam (no|voronoi|gc_color|gc_colorgrad) 拼接缝隙估计方法 默认是gc_color
--compose_megapix <float> 拼接分辨率,默认为-1
--expos_comp (no|gain|gain_blocks) 光照补偿方法,默认是gain_blocks
--blend (no|feather|multiband) 融合方法,默认是多频段融合
--blend_strength <float> 融合强度,0-100.默认是5.
--output <result_img> 输出图像的文件名,默认是result,jpg
命令使用实例,以及程序运行时的提示:
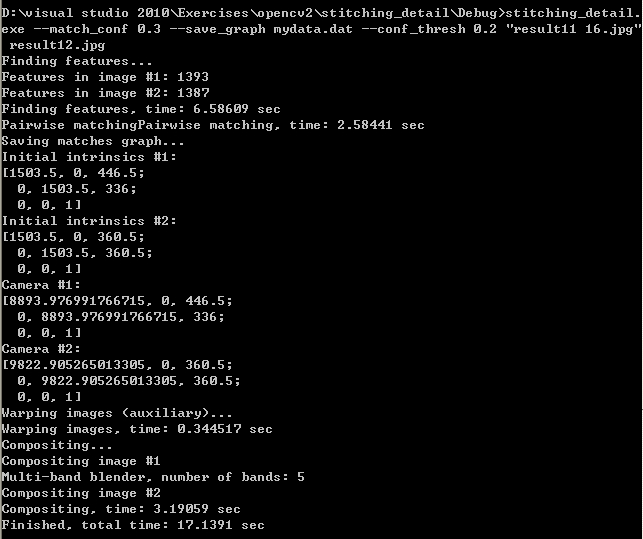
三、程序代码分析
1.参数读入
程序参数读入分析,将程序运行是输入的参数以及需要拼接的图像读入内存,检查图像是否多于2张。
int retval = parseCmdArgs(argc, argv);
if (retval)
return retval;
// Check if have enough images
int num_images = static_cast<int>(img_names.size());
if (num_images < 2)
{
LOGLN("Need more images");
return -1;
}2.特征点检测
判断选择是surf还是orb特征点检测(默认是surf)以及对图像进行预处理(尺寸缩放),然后计算每幅图形的特征点,以及特征点描述子
2.1 计算work_scale,将图像resize到面积在work_megapix*10^6以下,(work_megapix 默认是0.6)
work_scale = min(1.0, sqrt(work_megapix * 1e6 / full_img.size().area()));resize(full_img, img, Size(), work_scale, work_scale);
2.2 计算seam_scale,也是根据图像的面积小于seam_megapix*10^6,(seam_megapix 默认是0.1),seam_work_aspect目前还没用到
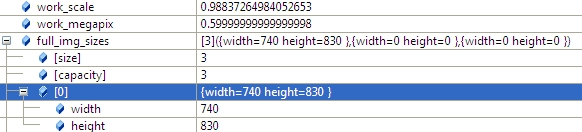
seam_scale = min(1.0, sqrt(seam_megapix * 1e6 / full_img.size().area()));
seam_work_aspect = seam_scale / work_scale; //seam_megapix = 0.1 seam_work_aspect = 0.69
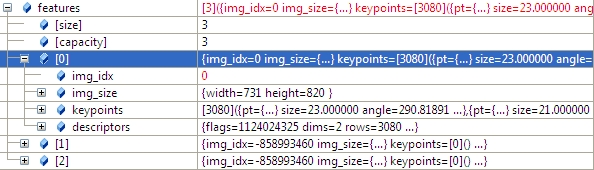
2.3 计算图像特征点,以及计算特征点描述子,并将img_idx设置为i。
(*finder)(img, features[i]);//matcher.cpp 348
features[i].img_idx = i; struct detail::ImageFeatures
Structure containing image keypoints and descriptors.
struct CV_EXPORTS ImageFeatures
{
int img_idx;//
Size img_size;
std::vector<KeyPoint> keypoints;
Mat descriptors;
};
2.4 将源图像resize到seam_megapix*10^6,并存入image[]中
resize(full_img, img, Size(), seam_scale, seam_scale);
images[i] = img.clone();对任意两副图形进行特征点匹配,然后使用查并集法,将图片的匹配关系找出,并删除那些不属于同一全景图的图片。
3.1 使用最近邻和次近邻匹配,对任意两幅图进行特征点匹配。
vector<MatchesInfo> pairwise_matches;//Structure containing information about matches between two images.
BestOf2NearestMatcher matcher(try_gpu, match_conf);//最近邻和次近邻法
matcher(features, pairwise_matches);//对每两个图片进行matcher,20-》400 matchers.cpp 502 //Features matcher which finds two best matches for each feature and leaves the best one only if the ratio between descriptor distances is greater than the threshold match_conf.
detail::BestOf2NearestMatcher::BestOf2NearestMatcher(bool try_use_gpu=false,float match_conf=0.3f,
intnum_matches_thresh1=6, int num_matches_thresh2=6)
Parameters: try_use_gpu – Should try to use GPU or not
match_conf – Match distances ration threshold
num_matches_thresh1 – Minimum number of matches required for the 2D projective
transform estimation used in the inliers classification step
num_matches_thresh2 – Minimum number of matches required for the 2D projective
transform re-estimation on inliersBestOf2NearestMatcher::BestOf2NearestMatcher(bool try_use_gpu, float match_conf, int num_matches_thresh1, int num_matches_thresh2)
{
#ifdef HAVE_OPENCV_GPU
if (try_use_gpu && getCudaEnabledDeviceCount() > 0)
impl_ = new GpuMatcher(match_conf);
else
#else
(void)try_use_gpu;
#endif
impl_ = new CpuMatcher(match_conf);
is_thread_safe_ = impl_->isThreadSafe();
num_matches_thresh1_ = num_matches_thresh1;
num_matches_thresh2_ = num_matches_thresh2;
}以及MatchesInfo的结构体定义:
Structure containing information about matches between two images. It’s assumed that there is a homography between those images.
struct CV_EXPORTS MatchesInfo
{
MatchesInfo();
MatchesInfo(const MatchesInfo &other);
const MatchesInfo& operator =(const MatchesInfo &other);
int src_img_idx, dst_img_idx; // Images indices (optional)
std::vector<DMatch> matches;
std::vector<uchar> inliers_mask; // Geometrically consistent matches mask
int num_inliers; // Number of geometrically consistent matches
Mat H; // Estimated homography
double confidence; // Confidence two images are from the same panorama
};
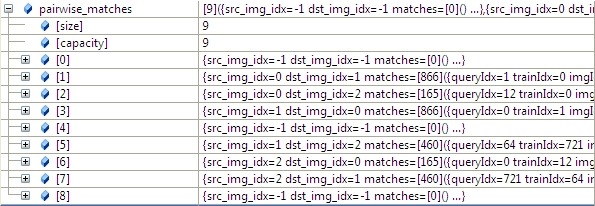
3.2 根据任意两幅图匹配的置信度,将所有置信度高于conf_thresh(默认是1.0)的图像合并到一个全集中。
我们通过函数的参数 save_graph打印匹配结果如下(我稍微修改了一下输出):
"outimage101.jpg" -- "outimage102.jpg"[label="Nm=866, Ni=637, C=2.37864"];
"outimage101.jpg" -- "outimage103.jpg"[label="Nm=165, Ni=59, C=1.02609"];
"outimage102.jpg" -- "outimage103.jpg"[label="Nm=460, Ni=260, C=1.78082"];通过查并集方法,查并集介绍请参见博文:
http://blog.csdn.net/skeeee/article/details/20471949
vector<int> indices = leaveBiggestComponent(features, pairwise_matches, conf_thresh);//将置信度高于门限的所有匹配合并到一个集合中
vector<Mat> img_subset;
vector<string> img_names_subset;
vector<Size> full_img_sizes_subset;
for (size_t i = 0; i < indices.size(); ++i)
{
img_names_subset.push_back(img_names[indices[i]]);
img_subset.push_back(images[indices[i]]);
full_img_sizes_subset.push_back(full_img_sizes[indices[i]]);
}
images = img_subset;
img_names = img_names_subset;
full_img_sizes = full_img_sizes_subset;4.1 焦距参数的估计
根据前面求出的任意两幅图的匹配,我们根据两幅图的单应性矩阵H,求出符合条件的f,(4副图,16个匹配,求出8个符合条件的f),然后求出f的均值或者中值当成所有图形的粗略估计的f。
estimateFocal(features, pairwise_matches, focals); for (int i = 0; i < num_images; ++i)
{
for (int j = 0; j < num_images; ++j)
{
const MatchesInfo &m = pairwise_matches[i*num_images + j];
if (m.H.empty())
continue;
double f0, f1;
bool f0ok, f1ok;
focalsFromHomography(m.H, f0, f1, f0ok, f1ok);//Tries to estimate focal lengths from the given homography 79
//under the assumption that the camera undergoes rotations around its centre only.
if (f0ok && f1ok)
all_focals.push_back(sqrt(f0 * f1));
}
}
其
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2656
2656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









