







 本文介绍了OpenCV2.4.9中图像拼接的关键步骤——寻找接缝线,包括逐点法、动态规划法和图割法。动态规划法因效率和内存使用较少,适合移动设备上的全景拼接。图割法利用最大流图割算法,通过构建有向图来分割图像。文章详细阐述了各种方法的原理和源码实现。
本文介绍了OpenCV2.4.9中图像拼接的关键步骤——寻找接缝线,包括逐点法、动态规划法和图割法。动态规划法因效率和内存使用较少,适合移动设备上的全景拼接。图割法利用最大流图割算法,通过构建有向图来分割图像。文章详细阐述了各种方法的原理和源码实现。
6、寻找接缝线
6.1 原理
拼接图像的另一个重要的步骤是找到图像重叠部分内的一条接缝线,该接缝是重叠部分最相似的像素的连线。当确定了接缝线后,在重叠部分,线的一侧只选择该侧的图像部分,线的另一侧只选择这一侧的图像部分,而不是把重叠部分的两幅图像简单融合起来。这么做的目的可以避免图像的模糊及伪像。
目前,常用的寻找接缝线的方法有三种:逐点法、动态规划法和图割法。
逐点法比较简单,它的原理就是重叠部分内的像素距离哪个图像更近,就用哪个图像中的相应像素值。这种方法并不是基于像素值,只是基于距离准则。所以这种方法并不能真正得到最佳的接缝线,寻找的结果比较粗糙原始,仅仅是能够分割重叠部分而已。
动态规划法可以快速的找到最佳的接缝线,并且所需的内存较少,因此该方法很适合在移动终端设备上进行高清晰度的全景拼接。
设图像1和图像2之间有重叠部分,我们需要得到它们之间的最佳接缝,首先定义重叠部分的误差表面函数:

式中,I1,I2表示两幅图像各自的重叠部分,││,||表示范数。
一般来说,接缝线有三个限制条件:一是如果重叠区域是宽大于高,则接缝是横向走向的,而如果重叠区域是宽小于高,则接缝是纵向走向的,也就是要保证接缝线要有一定的长度;二是如果是横向的接缝,则不允许有绝对垂直的接缝线,而如果是纵向的接缝,则不允许有绝对水平的接缝线;三是重叠区域是矩形,接缝线从矩形的一边出发,必须到达与该边平行的另一边结束。
假设重叠区域的宽小于高,则接缝线是垂直的,我们需要横向遍历e值,并且计算所有可能到达当前像素(i, j)的路径的累积最小误差E:

式中,min中的三项内容分别表示当前像素与其左上侧、上侧和右上侧的E。在E中最后一行的最小值表明已经到达了最小垂直路径的尽头,那么我们就可以追溯,从而得到最佳路径,即接缝线。
同理,重叠区域的宽大于高也能够做出类似的计算过程。
我们可以看出,动态规划算法非常适用于对式89的求解,这也是该寻找最佳接缝线方法名称的由来。
对于彩色图像,计算式88可以有两种方法:直接法和梯度法。设p和q是两个相邻像素,直接法的计算公式为:

梯度法的计算公式为:
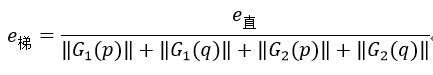
式中,G表示灰度图像的p到q方向上的梯度。
最后一种方法是图割法。它的主要思想是将图像看成是一个有向图G={ V, E},V表示节点,E表示边。节点分为两种:普通节点和终端节点。图像的像素可以作为普通节点,图像的聚类结果可以看成是终端节点,即某一聚类中的普通节点会汇聚于一个终端节点,一般图只有两个终端节点:s和t,也就是说一般图割法只能够把图像分割成两类S和T。边指的是节点之间的连接,对于普通节点,只有相邻节点可以连接,该边被称为n-links,而所有普通节点都可与属于它们的终端节点之间有连接,该边被称为t-links。用最大流图割法可以得到哪些普通节点属于终端节点s,那么剩下的普通节点就会属于t。
Opencv中所实现的最大流图割算法是基于Boykov和Kolmogorov所提出的算法。该算法是以s和t为根,以得到的两棵无不相交的搜索树S和T为目标,它迭代的重复以下三个阶段:
生长阶段:搜索树S和T的生长,直到两棵树生长到了一起,形成了从s到t的通路(即为流);
增广阶段:该通路被增广,使相连的两棵树又重新分开;
收养阶段:搜索树S和T收养孤立的节点(称为孤儿)。
在生长阶段,如果找不到任何一条从s到t的通路,则迭代结束。在增广阶段,开始孤儿集合是空集,而该阶段结束后,可能会出现一些孤儿。在该阶段,我们需要得到通路上最小的容量值(也称为边的权值),然后所有的容量值都减去该值(即通过流量更新容量值),则该通路上至少会有一个权值为0的边(称为饱和边),假设饱和边上的两个节点为p和q,并且在正向通路中是由p流向q,如果p和q都属于树S,则q为孤儿,如果p和q都属于树T,则p为孤儿。在收养阶段,检查孤儿集合中的所有孤儿的邻域像素,连接那些它们的边的容量值不为0的像素,如果最终可以从该孤儿连通到s或t,则该孤儿就属于树S或树T,否则由该孤儿组成的树就属于自由节点集,在下次迭代时的生长阶段,树S和树T就通过连接自由节点集中的节点来使两棵树生长发育的。
如何用最大流图割法寻找接缝线呢?接缝线把重叠区域分割成了两个区域,那么我们通过最大流图割法得到树S和树T,即得到了被分割的两个区域,则区域之间的接缝线自然就可以得到。
普通节点之间的初始容量值(即边的权值)也可以通过直接法和梯度法计算得到,它们的计算公式分别与式90和式91相同。终端节点与普通节点之间的初始容量值可以定义为一个很大的值,当重叠区域中的节点只属于图像1或图像2时,节点与相应的终端节点的边赋予该值,其他情况都置为0,表示它们与终端节点无直接连接。
6.2 源码
SeamFinder类是寻找缝的基类,该类内有一个最重要的虚函数是find,它的作用是寻找缝:
virtual void find(const std::vector<Mat> &src, const std::vector<Point> &corners,
std::vector<Mat> &masks) = 0;
它的三个输入参数分别为:src表示待拼接的图像,corners表示待拼接图像在最终的全景图像坐标系内的左上角的坐标位置,masks输入时表示上一步得到的映射变换掩码,输出时表示接缝掩码,也就是该参数是要更新输出的,输出时如果像素值更新为0了,则表示该像素是在接缝的另一侧,拼接时是不需要该像素的。
基于SeamFinder类有四个子类,分别对应于四种不同的寻找缝的算法——NoSeamFinder(无需寻找缝)、PairwiseSeamFinder(逐点寻找缝算法)、DpSeamFinder(动态规划寻找缝算法)和GraphCutSeamFinder(图割寻找缝算法)。
我们先来介绍PairwiseSeamFinder类。逐点寻找缝算法又可分为不同的方法,Opencv只实现了Voronoi图方法,实现该方法的类为VoronoiSeamFinder类,它是PairwiseSeamFinder类的子类。VoronoiSeamFinder类的find函数为:
void VoronoiSeamFinder::find(const vector<Size> &sizes, const vector<Point> &corners,
vector<Mat> &masks)
{
LOGLN("Finding seams...");
if (sizes.size() == 0) //没有图像,则返回
return;
#if ENABLE_LOG
int64 t = getTickCount(); //计时
#endif
//参数赋值
sizes_ = sizes;
corners_ = corners;
masks_ = masks;
run(); //调用run函数
//计时输出
LOGLN("Finding seams, time: " << ((getTickCount() - t) / getTickFrequency()) << " sec");
}
VoronoiSeamFinder类没有实现run函数,因此这里的find函数调用的是它的父类PairwiseSeamFinder类的run函数:
void PairwiseSeamFinder::run()
{
//遍历图像对
for (size_t i = 0; i < sizes_.size() - 1; ++i)
{
for (size_t j = i + 1; j < sizes_.size(); ++j)
{
Rect roi; //表示图像间的重叠部分
//如果图像i和图j之间有重叠的区域,则执行findInPair函数
if (overlapRoi(corners_[i], corners_[j], sizes_[i], sizes_[j], roi))
findInPair(i, j, roi);
}
}
}
findInPair函数表示寻找两幅图像之间的接缝:
void VoronoiSeamFinder::findInPair(size_t first, size_t second, Rect roi)
//first和second表示两幅图像的尺寸大小,roi表示图像间重叠部分
{
const int gap = 10;
//分别表示图像first和图像second的重叠部分的掩码,它们要比roi四周多gap个距离
Mat submask1(roi.height + 2 * gap, roi.width + 2 * gap, CV_8U);
Mat submask2(roi.height + 2 * gap, roi.width + 2 * gap, CV_8U);
Size img1 = sizes_[first], img2 = sizes_[second]; //得到两幅图像的尺寸
Mat mask1 = masks_[first], mask2 = masks_[second]; //得到两幅图像的掩码
Point tl1 = corners_[first], tl2 = corners_[second]; //得到两幅图像的左上角坐标
// Cut submasks with some gap
//遍历重叠部分,得到submask1和submask2
for (int y = -gap; y < roi.height + gap; ++y)
{
for (int x = -gap; x < roi.width + gap; ++x)
{
//y1和x1表示重叠部分相对于图像first的坐标
int y1 = roi.y - tl1.y + y;
int x1 = roi.x - tl1.x + x;
//把图像first的掩码赋值给submask1
//表示当前坐标在图像first内
if (y1 >= 0 && x1 >= 0 && y1 < img1.height && x1 < img1.width)
submask1.at<uchar>(y + gap, x + gap) = mask1.at<uchar>(y1, x1);
else //表示当前坐标不在图像first内
submask1.at<uchar>(y + gap, x + gap) = 0;
//y2和x2表示重叠部分相对于图像second的坐标
int y2 = roi.y - tl2.y + y;
int x2 = roi.x - tl2.x + x;
//把图像second的掩码赋值给submask2
//表示当前坐标在图像second内
if (y2 >= 0 && x2 >= 0 && y2 < img2.height && x2 < img2.width)
submask2.at<uchar>(y + gap, x + gap) = mask2.at<uchar>(y2, x2);
else //表示当前坐标不在图像second内
submask2.at<uchar>(y + gap, x + gap) = 0;
}
}
//collision表示submask1和submask2交集,roi区域可能有些区域是无效的部分(由于映射的原因),而collision(像素值为1的部分)则是图像first和图像second的真正有意义部分的重叠区域,我们是需要在collision区域内寻找接缝的
Mat collision = (submask1 != 0) & (submask2 != 0);
//复制submask1和submask2为unique1和unique2,并且把collision部分的像素清零
Mat unique1 = submask1.clone(); unique1.setTo(0, collision);
Mat unique2 = submask2.clone(); unique2.setTo(0, collision);
Mat dist1, dist2; //表示距离矩阵
//分别得到unique1和unique2内为0的像素值与最近的非0值之间的L1距离,显然为0的区域肯定要比collision大
distanceTransform(unique1 == 0, dist1, CV_DIST_L1, 3);
distanceTransform(unique2 == 0, dist2, CV_DIST_L1, 3);
//得到缝矩阵,dist1 < dist2成立,说明离first图像近,则seam内相应的像素为1,否则为0
Mat seam = dist1 < dist2;
//遍历roi内的所有像素
for (int y = 0; y < roi.height; ++y)
{
for (int x = 0; x < roi.width; ++x)
{
//如果seam内的像素值为1,说明collision区域内的相应像素离图像first近,所以该点的值选择图像first的像素值,因此需把mask2清零,反之把mask1清零。也就是在重叠部分,哪些区域应该属于图像first,哪些区域属于图像second。
if (seam.at<uchar>(y + gap, x + gap))
mask2.at<uchar>(roi.y - tl2.y + y, roi.x - tl2.x + x) = 0;
else
mask1.at<uchar>(roi.y - tl1.y + y, roi.x - tl1.x + x) = 0;
}
}
}
DpSeamFinder类利用动态规划算法寻找缝,它的构造函数为:
DpSeamFinder::DpSeamFinder(CostFunction costFunc) : costFunc_(costFunc) {}其中CostFunction为:
enum CostFunction { COLOR, COLOR_GRAD };
它表示动态规划寻找接缝的两种不同方法,直接法和梯度法,默认是直接法。
DpSeamFinder类的find函数为:
void DpSeamFinder::find(const vector<Mat> &src, const vector<Point> &corners, vector<Mat> &masks)
{
LOGLN("Finding seams...");
#if ENABLE_LOG
int64 t = getTickCount(); //用于计时
#endif
if (src.size() == 0) //没有图像,则返回
return;
vector<pair<size_t, size_t> > pairs; //表示图像对
for (size_t i = 0; i+1 < src.size(); ++i)
for (size_t j = i+1; j < src.size(); ++j)
pairs.push_back(make_pair(i, j)); //每两幅图像组成一个图像对
//根据图像位置(基于左上角坐标),对图像对进行排序
sort(pairs.begin(), pairs.end(), ImagePairLess(src, corners));
reverse(pairs.begin(), pairs.end()); //逆序
for (size_t i = 0; i < pairs.size(); ++i) //遍历图像对,
{
size_t i0 = pairs[i].first, i1 = pairs[i].second;
//寻找i0和i1这两幅图像的接缝,该函数在后面有介绍
process(src[i0], src[i1], corners[i0], corners[i1], masks[i0], masks[i1]);
}
LOGLN("Finding seams, time: " << ((getTickCount() - t) / getTickFrequency()) << " sec");
}
寻找两幅图像间的接缝:
void DpSeamFinder::process(
const Mat &image1, const Mat &image2, Point tl1, Point tl2,
Mat &mask1, Mat &mask2)
//image1和image2分别表示待处理的两幅图像
//tl1和tl2分别表示这两幅图像的左上角坐标
//mask1和mask2分别表示这两幅图像的掩码
{
CV_Assert(image1.size() == mask1.size()); //确保图像与掩码尺寸相同
CV_Assert(image2.size() == mask2.size());
//intersectTl和intersectBr分别表示image1和image2的交集区域(即重叠部分)的左上角和右下角坐标
Point intersectTl(std::max(tl1.x, tl2.x), std::max(tl1.y, tl2.y));
Point intersectBr(std::min(tl1.x + image1.cols, tl2.x + image2.cols),
std::min(tl1.y + image1.rows, tl2.y + image2.rows));
//如果if条件成立,则说明image1和image2没有重叠区域,因此退出该函数
if (intersectTl.x >= intersectBr.x || intersectTl.y >= intersectBr.y)
return; // there are no conflicts
//unionTl_和unionBr_分别表示image1和image2的并集区域(即外围最大部分的矩形)的左上角和右下角坐标
unionTl_ = Point(std::min(tl1.x, tl2.x), std::min(tl1.y, tl2.y));
unionBr_ = Point(std::max(tl1.x + image1.cols, tl2.x + image2.cols),
std::max(tl1.y + image1.rows, tl2.y + image2.rows));
//得到image1和image2的并集区域的尺寸大小
unionSize_ = Size(unionBr_.x - unionTl_.x, unionBr_.y - unionTl_.y);
//定义两幅图像的掩码大小,先清零
mask1_ = Mat::zeros(unionSize_, CV_8U);
mask2_ = Mat::zeros(unionSize_, CV_8U);
//tmp为mask1_中image1的区域
Mat tmp = mask1_(Rect(tl1.x - unionTl_.x, tl1.y - unionTl_.y, mask1.cols, mask1.rows));
mask1.copyTo(tmp); //把image1的掩码mask1赋值给mask1_
//tmp为mask2_中image2的区域
tmp = mask2_(Rect(tl2.x - unionTl_.x, tl2.y - unionTl_.y, mask2.cols, mask2.rows));
mask2.copyTo(tmp); //把image2的掩码mask2赋值给mask2_
// find both images contour masks
//在并集中分别得到边界掩码contour1mask_和contour2mask_
contour1mask_ = Mat::zeros(unionSize_, CV_8U); //先清零
contour2mask_ = Mat::zeros(unionSize_, CV_8U);
//遍历并集区域
for (int y = 0; y < unionSize_.height; ++y)
{
for (int x = 0; x < unionSize_.width; ++x)
{
if (mask1_(y, x) &&
((x == 0 || !mask1_(y, x-1)) || (x == unionSize_.width-1 || !mask1_(y, x+1)) ||
(y == 0 || !mask1_(y-1, x)) || (y == unionSize_.height-1 || !mask1_(y+1, x))))
{
contour1mask_(y, x) = 255; //得到image1的边界掩码
}
if (mask2_(y, x) &&
( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









