









前言
卷积参数
- k e r n e l kernel kernel:卷积核大小k。
- C o u t C_{out} Cout:卷积核数量,即输出通道数。
- C i n C_{in} Cin:卷积核维度,即输入通道数。
- p a d d i n g padding padding:填充数p。
- s t r i d e stride stride:滑动步长s。
- d i l a t i o n dilation dilation: 内核点之间的距离d。
- gourp:将卷积组分组。
1. 传统卷积计算
假如输入图像 ( H , W , C i n ) (H,W,C_{in}) (H,W,Cin),使用 C o u t C_{out} Cout个 ( K , K , C i n ) (K,K,C_{in}) (K,K,Cin)的卷积,且填充为P,步长为S。
卷积核以滑动窗口形式扫描输入图片,对应元素逐点相乘再多通道相加:
o
u
t
(
N
i
,
C
o
u
t
j
)
=
b
i
a
s
(
C
o
u
t
j
)
+
∑
k
=
0
C
i
n
−
1
w
e
i
g
h
t
(
C
o
u
t
j
,
k
)
⨂
i
n
p
u
t
(
N
i
,
k
)
out(N_i, C_{out_j})=bias(C_{out_j})+\sum^{C_{in}-1}_{k=0}weight(C_{out_j},k)\bigotimes input(N_i,k)
out(Ni,Coutj)=bias(Coutj)+k=0∑Cin−1weight(Coutj,k)⨂input(Ni,k)
传统卷积后特征图大小
H o u t = f l o o r ( H i n − K + 2 P S + 1 ) H_{out}=floor(\frac{H_{in}-K+2P}{S}+1) Hout=floor(SHin−K+2P+1),对W同理。
卷积计算量
c o n s u m p t i o n s = K ∗ K ∗ C ∗ C o u t ∗ H ∗ W + C o u t consumptions=K*K*C*C_{out}*H*W+C_{out} consumptions=K∗K∗C∗Cout∗H∗W+Cout
卷积参数量
p a r m s = K ∗ K ∗ C ∗ C o u t + C o u t parms=K*K*C*C_{out}+C_{out} parms=K∗K∗C∗Cout+Cout
2. 反卷积
也就是传统卷积的逆运算:
H
o
u
t
=
(
H
i
n
−
1
)
∗
S
−
2
P
+
K
H_{out}=(H_{in}-1)*S-2P+K
Hout=(Hin−1)∗S−2P+K
常用于GAN等生成任务中,缺点是容易出现棋盘格伪影。

如何减少棋盘效应:
- 确保使用的filters的大小能被步长整除,以避免不均匀的重叠问题。
- 可以使用步长=1的转置卷积。
- 调整图像的大小(使用最近邻插值或双线性插值),然后再进行卷积。
3. 空洞卷积
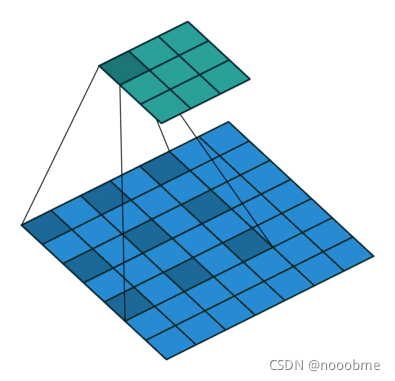
使用空洞卷积后特征图大小:
H o u t = f l o o r ( H i n + 2 P − d ( K − 1 ) − 1 S + 1 ) H_{out}=floor(\frac{H_{in}+2P-d(K-1)-1}{S}+1) Hout=floor(SHin+2P−d(K−1)−1+1),对W同理。
好处:
- 不需要额外的计算量就可以获得更大的感受野。例如(3,3)的卷积核,设置d为1时,等同(3,3)的感受野;当d为2时,等同于(5,5)的感受野;当d=3时,等同于(7,7)的感受野。
4. 分组卷积
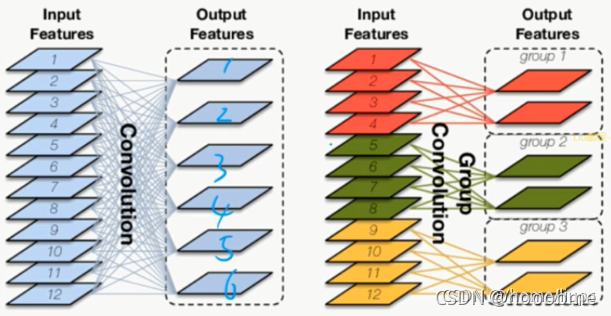
对应的输入组与对应的卷积组进行卷积操作。
-
例如输入特征图为 ( C 1 , H , W ) (C_1,H,W) (C1,H,W),卷积组为 C 2 C_2 C2个 ( C , K , K ) (C,K,K) (C,K,K),分成3个group。
-
每 ( C 1 3 , H , 2 ) (\frac{C_1}{3},H,2) (3C1,H,2)的特征图与每 C 2 3 个 ( C , K , K ) \frac{C_2}{3}个(C,K,K) 3C2个(C,K,K)进行卷积,然后再拼接起来。
分组卷积的优点:
- 分组卷积的参数量是正常卷积的1/N 。N为分组数。
- 分组卷积可以看成是正常卷积的稀疏结构,可以视为一种正则。
- 逐通道卷积可以进一步减少参数,在轻量化网络中很常用。
- GPU并行化,加速训练。
分组卷积的缺点:
- 数据信息只存在本组里面。通道之间的信息没有交互,存在信息的屏蔽和阻塞,不流通。
- groups一定要同时被输入通道数和输出通道数整除,否则会报错。
参数量和计算量对比
假如输入的特征图 ( H 1 , W 1 , C 1 ) (H_1,W_1,C_1) (H1,W1,C1),输出 ( H 2 , W 2 , C 2 ) (H_2,W_2,C_2) (H2,W2,C2)
- 标准卷积:使用带
C
2
C_2
C2个标准卷积
(
K
,
K
,
C
1
)
(K,K,C_1)
(K,K,C1):
- 计算量为: ( K ∗ K ∗ C 2 ) ∗ ( C 1 ∗ H 1 ∗ W 1 ) (K*K*C_2)*(C_1*H_1*W_1) (K∗K∗C2)∗(C1∗H1∗W1)
- 参数量为: K ∗ K ∗ C 2 ∗ C 1 + C 2 K*K*C_2*C_1+C_2 K∗K∗C2∗C1+C2
- 分组卷积:使用N组
(
K
,
K
,
C
2
N
)
(K,K,\frac{C_2}{N})
(K,K,NC2)的卷积核,且输入图也分为N组,即
(
H
1
,
W
1
,
C
1
N
)
(H_1,W_1,\frac{C_1}{N})
(H1,W1,NC1):
- 计算量为: ( K ∗ K ∗ C 2 N ) ∗ ( C 1 N ∗ H 1 ∗ W 1 ) ∗ N (K*K*\frac{C_2}{N})*(\frac{C_1}{N}*H_1*W_1)*N (K∗K∗NC2)∗(NC1∗H1∗W1)∗N
- 参数量为: K ∗ K ∗ C 2 N ∗ C 1 N ∗ N + C 2 K*K*\frac{C_2}{N}*\frac{C_1}{N}*N+C_2 K∗K∗NC2∗NC1∗N+C2
- 计算量占比: ( K ∗ K ∗ C 2 N ) ∗ ( C 1 N ∗ H 1 ∗ W 1 ) ∗ N ( K ∗ K ∗ C 2 ) ∗ ( C 1 ∗ H 1 ∗ W 1 ) = 1 N \frac{(K*K*\frac{C_2}{N})*(\frac{C_1}{N}*H_1*W_1)*N}{(K*K*C_2)*(C_1*H_1*W_1)}=\frac{1}{N} (K∗K∗C2)∗(C1∗H1∗W1)(K∗K∗NC2)∗(NC1∗H1∗W1)∗N=N1
- 参数量占比,忽略加号: K ∗ K ∗ C 2 N ∗ C 1 N ∗ N K ∗ K ∗ C 2 ∗ C 1 = 1 N \frac{K*K*\frac{C_2}{N}*\frac{C_1}{N}*N}{K*K*C_2*C_1}=\frac{1}{N} K∗K∗C2∗C1K∗K∗NC2∗NC1∗N=N1
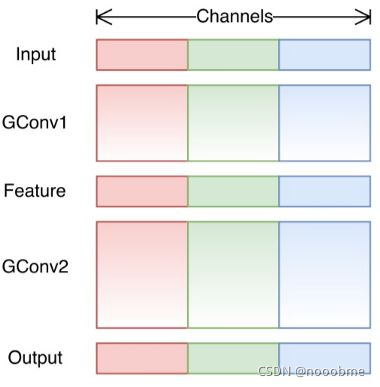
4.1 随机分组卷积
随机分组卷积于ShuflleNet提出,核心思想是将组卷积后得到的特征图进行组通道混合,使得跨通道信息流通。
正常的按顺序分组,分3组情况如下,不同颜色代表不同组:
下图是Shuffle Channel情况,是将随机打乱(输入组*卷积组)得到的特征组,即将输出的特征组内的channel人为分配到不同的组中。
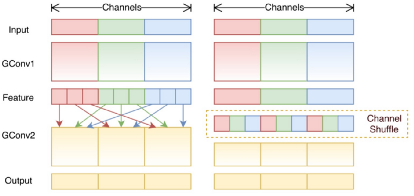
好处:
- 未shuffle的问题在于每个filters组仅处理从先前层中的固定部分向下传递的信息。因此,每个filters组仅限于学习特定特征,阻止不同channel 组之间的信息流通。
- 将shuffled后的特征不同channel组进行混合,信息能够在通道组之间流动,加强了特征表示。
但是 shuffleNet 也有两个缺点:
缺点:
- Channel Shuffle 在实现的时候需要大量的指针跳转和 Memory set,这本身就是极其耗时的;同时又特别依赖实现细节,导致实际运行速度不会那么理想。
- Channel Shuffle 的规则是人定的,每个通道都需要等量地交换信息,不一定是最优的,不是网络自己学出来的。
4.2 逐点分组卷积
1*1的普通卷积占据了总计算量的大部分,为了减少计算量,也将1*1的卷积进行分组。
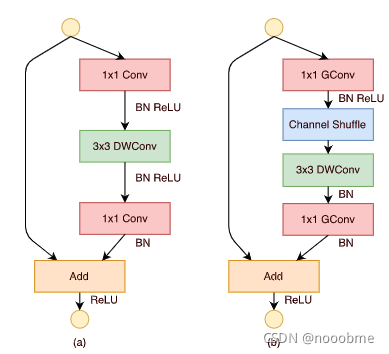
参数量和计算量对比
假如输入特征图 ( H , W , C ) (H,W,C) (H,W,C),输出 ( H 2 , W 2 , C ) (H_2,W_2,C) (H2,W2,C),假设第一个(1,1)和(3,3)卷积的输出通道为 m m m,最终的输出通道数为 C C C,则不同网络参数量为:
- ResNet :
H ∗ W ∗ ( 1 ∗ 1 ∗ C ∗ m ) + H ∗ W ∗ ( 3 ∗ 3 ∗ m ∗ m ) + H ∗ W ∗ ( 1 ∗ 1 ∗ m ∗ C ) = H ∗ W ∗ ( 2 ∗ C ∗ m + 9 m 2 ) H*W*(1*1*C*m)+H*W*(3*3*m*m)+H*W*(1*1*m*C)\\=H*W*(2*C*m+9m^2 ) H∗W∗(1∗1∗C∗m)+H∗W∗(3∗3∗m∗m)+H∗W∗(1∗1∗m∗C)=H∗W∗(2∗C∗m+9m2) - ResNeXt :
H ∗ W ∗ ( 1 ∗ 1 ∗ C × m ) + H ∗ W ∗ ( 3 ∗ 3 ∗ m ∗ m ) / N + H ∗ W ∗ ( 1 ∗ 1 ∗ m ∗ c ) = H ∗ W ∗ ( 2 ∗ C ∗ m + 9 m 2 / N ) H*W*(1*1*C×m)+H*W*(3*3*m*m)/N+H*W*(1*1*m*c)\\=H*W*(2*C*m+9m^2 /N) H∗W∗(1∗1∗C×m)+H∗W∗(3∗3∗m∗m)/N+H∗W∗(1∗1∗m∗c)=H∗W∗(2∗C∗m+9m2/N) - ShuffleNet :
H ∗ W ∗ ( 1 ∗ 1 ∗ C ∗ m ) / N + H ∗ W ∗ ( 3 ∗ 3 ∗ m ) + H ∗ W ∗ ( 1 ∗ 1 ∗ m ∗ c ) / N = H ∗ W ∗ ( 2 ∗ C ∗ m / N + 9 m ) H*W*(1*1*C*m)/N+H*W*(3*3*m)+H*W*(1*1*m*c)/N\\=H*W*(2*C*m/N+9m) H∗W∗(1∗1∗C∗m)/N+H∗W∗(3∗3∗m)+H∗W∗(1∗1∗m∗c)/N=H∗W∗(2∗C∗m/N+9m)
DW conv 其实就是 N = m。
5. 分离卷积
5.1 空间可分离卷积
将(K, K)卷积分成(K, 1)卷积核和(1, K)卷积核,但并不是所有的卷积核都可以被拆分成两个小的卷积核。
以下是可拆分的情况:Sobel的kennel(3x3的kennel)分为3x1和1x3的kennel。

5.2 深度可分离卷积
将
(
C
i
n
,
K
,
K
)
(C_{in},K,K)
(Cin,K,K)的卷积核 拆分成
(
1
,
K
,
K
)
(1,K,K)
(1,K,K)[depthwise convolution]和
(
C
i
n
,
1
,
1
)
(C_{in},1,1)
(Cin,1,1)[pointwise convolution]的卷积核。Mobilenet中使用的基础卷积单元就是深度可分离卷积(depthwise separable convolution)。
- 先使用depthwise convolution对每一个通道分别进行卷积操作,
- 然后采用pointwise convolution将上面的输出再进行结合。


图 1 ( a ) 为 传 统 卷 积 ( K , K , C ) 操 作 可 拆 成 ( K , K , 1 ) 和 ( 1 , 1 , C ) , 图 1 ( b ) 为 d e p t h w i s e 卷 积 也 就 是 ( K , K , 1 ) , 图 1 ( c ) 为 p o i n t w i s e 卷 积 ( 1 , 1 , C ) 。 图1(a)为传统卷积(K,K,C)操作可拆成(K,K,1)和(1,1,C),\\图1(b)为depthwise卷积也就是(K,K,1),\\图1(c)为pointwise卷积(1,1,C)。 图1(a)为传统卷积(K,K,C)操作可拆成(K,K,1)和(1,1,C),图1(b)为depthwise卷积也就是(K,K,1),图1(c)为pointwise卷积(1,1,C)。
参数量和计算量对比
假如输入特征图大小为 ( H 1 , W 1 , C 1 ) (H_1,W_1,C_1) (H1,W1,C1),输出大小为 ( H 2 , W 2 , C 2 ) (H_2,W_2,C_2) (H2,W2,C2)。
- 使用带
C
2
C_2
C2个标准卷积大小
(
K
,
K
)
(K,K)
(K,K),并且卷积核输入时有
C
1
C_1
C1个:
- 计算量为: ( K ∗ K ∗ C 2 ) ∗ ( C 1 ∗ H 1 ∗ W 1 ) (K*K*C_2)*(C_1*H_1*W_1) (K∗K∗C2)∗(C1∗H1∗W1)
- 参数量为: K ∗ K ∗ C 2 ∗ C 1 + C 2 K*K*C_2*C_1+C_2 K∗K∗C2∗C1+C2
- 深度级可分离卷积,可拆分成
(
K
,
K
,
1
)
(K,K,1)
(K,K,1)和
(
1
,
1
,
C
2
)
(1,1,C_2)
(1,1,C2):
- depthwise计算量: ( K ∗ K ∗ 1 ) ∗ ( H 1 ∗ W 1 ∗ C 1 ) (K*K*1)*(H_1*W_1*C_1) (K∗K∗1)∗(H1∗W1∗C1),参数量: K ∗ K ∗ 1 ∗ C 1 + 1 K*K*1*C_1+1 K∗K∗1∗C1+1。
- pointwise计算量: ( 1 ∗ 1 ∗ C 2 ) ∗ ( H 1 ∗ W 1 ∗ C 1 ) (1*1*C_2)*(H_1*W_1*C_1) (1∗1∗C2)∗(H1∗W1∗C1),参数量: 1 ∗ 1 ∗ C 2 ∗ C 1 + C 2 1*1*C_2*C_1+C_2 1∗1∗C2∗C1+C2。
- 总计算量为: ( K ∗ K ∗ 1 ) ∗ ( H 1 ∗ W 1 ∗ C 1 ) + ( 1 ∗ 1 ∗ C 2 ) ∗ ( H 1 ∗ W 1 ∗ C 1 ) = ( K 2 + C 2 ) ∗ ( H 1 ∗ W 1 ∗ C 1 ) (K*K*1)*(H_1*W_1*C_1)+(1*1*C_2)*(H_1*W_1*C_1)=(K^2+C_2)*(H_1*W_1*C_1) (K∗K∗1)∗(H1∗W1∗C1)+(1∗1∗C2)∗(H1∗W1∗C1)=(K2+C2)∗(H1∗W1∗C1)
- 总参数量为: K ∗ K ∗ 1 ∗ C 1 + 1 + 1 ∗ 1 ∗ C 2 ∗ C 1 + C 2 = C 2 ∗ C 1 + K 2 C 1 + C 2 + 1 K*K*1*C_1+1+1*1*C_2*C_1+C_2=C_2*C_1+K^2C_1+C_2+1 K∗K∗1∗C1+1+1∗1∗C2∗C1+C2=C2∗C1+K2C1+C2+1
- 计算量占比: ( K 2 + C 2 ) ∗ ( H 1 ∗ W 1 ∗ C 1 ) ( K ∗ K ∗ C 2 ) ∗ ( C 1 ∗ H 1 ∗ W 1 ) = 1 C 2 + 1 K 2 \frac{(K^2+C_2)*(H_1*W_1*C_1)}{(K*K*C_2)*(C_1*H_1*W_1)}=\frac{1}{C_2}+\frac{1}{K^2} (K∗K∗C2)∗(C1∗H1∗W1)(K2+C2)∗(H1∗W1∗C1)=C21+K21
- 参数量占比,忽略加号: C 2 ∗ C 1 + K 2 C 1 K ∗ K ∗ C 2 ∗ C 1 = 1 K 2 + 1 C 2 \frac{C_2*C_1+K^2C_1}{K*K*C_2*C_1}=\frac{1}{K^2}+\frac{1}{C_2} K∗K∗C2∗C1C2∗C1+K2C1=K21+C21
因此,我们通常所使用的是3×3的卷积核,也就是会下降到原来的九分之一到八分之一。
1*1卷积核
1x1 卷积核作用:
- 激活函数搭配,增加网络的非线性,加深网络。
- 可用于减少特征图的通道数,以便后续卷积减少计算量和参数量。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











