







 本文深入探讨AlphaGoZero的棋盘编码器和树搜索算法,包括神经网络的集成、搜索策略及训练过程。通过共享卷积层的网络结构,AlphaGoZero在不需要人类棋谱的情况下,通过自我对弈不断强化学习,实现围棋AI的超越。
本文深入探讨AlphaGoZero的棋盘编码器和树搜索算法,包括神经网络的集成、搜索策略及训练过程。通过共享卷积层的网络结构,AlphaGoZero在不需要人类棋谱的情况下,通过自我对弈不断强化学习,实现围棋AI的超越。
AlphaGoZero 原理讲解
前言
前面我们了解了AlphaGo的原理,它通过结合监督学习和强化学习,并且基于蒙特卡洛树搜索展现出了非凡的围棋能力,不仅很好的继承了人类的下棋策略,甚至创造出了很多人们不曾使用过的新动作。而2017年发布的AlphaGoZero则更让人意外,它不仅没有使用任何人类的棋局数据进行初始化训练,而且也不需要在进行蒙特卡洛推演。AlphaGoZero从最开始就将树搜索与强化学习集成到了一起,它使用了更少的代码却比原先的AlphaGo更加强大,它是如何做到的呢?本篇文章就和大家一起探索AlphaGoZero背后的原理。(在阅读本篇博客之前,建议读者先阅读之前介绍AlphaGo实现原理的博客:AlphaGo原理讲解 )
一、AlphaGoZero 棋盘编码器
和之前介绍AlphaGo一样,我们首先来了解一下AlphaGoZero的棋盘编码器。与AlphaGo不同,AlphaGoZero最新版本的棋盘编码器也做了很大的调整,使用的是一个19×19×17的张量,其中当前黑色棋子的位置用一个平面来表示,前七次黑色棋子的位置用另外七个平面来表示;类似地,用另外八个平面表示白色棋子最近八步的位置信息。最后,还有一个平面用来表示当前执子方,如果该下黑色棋子了,该平面的值全为1;如果该下白子了,该平面的值则全为0。事实上,棋盘编码器的特征内容并不是固定不变的,我们完全可以尝试其他的平面组合,比如可以引进贴目的概念等。
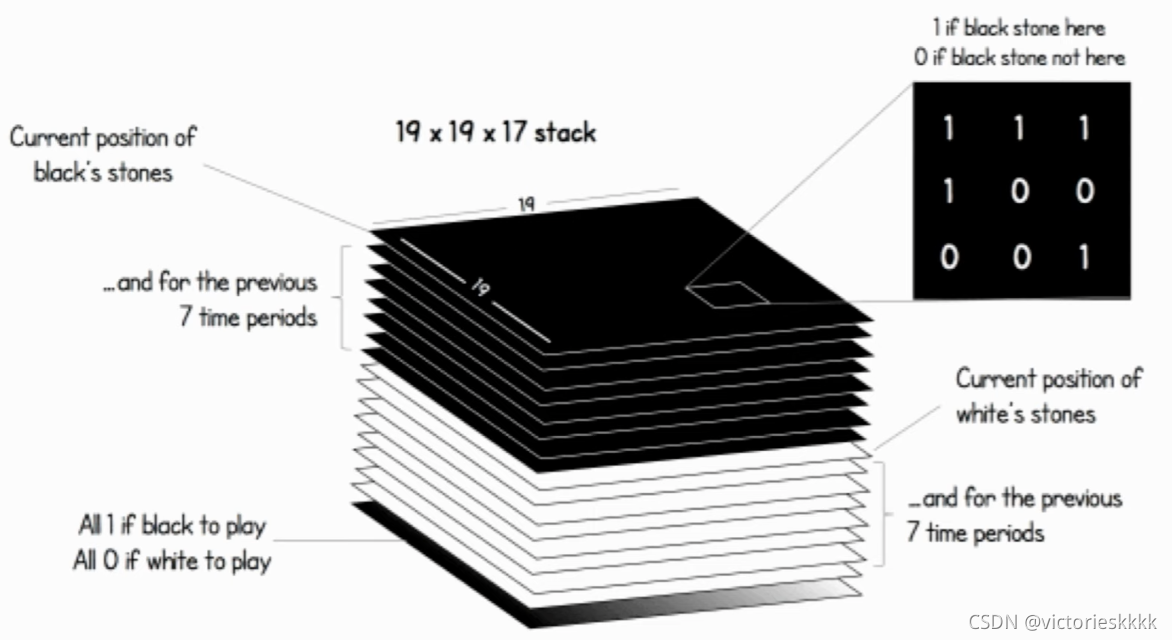
除此之外,在AlphaGo中实现模拟两个AI进行自我对弈的代码时,我们直接把跳过回合的逻辑显示地写了出来;而在AlphaGoZero中,由于自我对弈采用了树搜索的算法,我们可以把跳过回合看作与其他落子动作一样作为一个动作选项,因此网络的输出尺寸就变成了19×19+1=362。相应的,我们要把之前在AlphaGo中实现的向量元素索引和棋盘交叉点坐标相互转换的函数进行略微的调整,如下所示:
def encode_move(self, move):
if move.is_play:
return (self.board_size * (move.point.row - 1) +
(move.point.col - 1))
# add the pass as the 361th move
elif move.is_pass:
return self.board_size * self.board_size
raise ValueError('Cannot encode resign move')
def decode_move_index(self, index):
# check whether the move is pass first
if index == self.board_size * self.board_size:
return Move.pass_turn()
row = index // self.board_size
col = index % self.board_size
return Move.play(Point(row=row + 1, col=col + 1))
二、AlphaGoZero树搜索算法
从算法层面来讲,AlphaGoZero与AlphaGo最大的不同在于:无论AlphaGo是先用人类的棋谱对策略网络进行预训练,还是让预训练好的策略网络进行自我对弈,并使用生成的对弈棋谱训练策略网络和价值网络,需要注意的是,当将这些网络用于改进MCTS的时候,这些网络已经是训练好的了,在使用过程中是不能够再次训练的。而AlphaGoZero却与之相反,其先将神经网络融入到树搜索之中,指导树搜索,然后用这些对弈生成的棋谱再训练神经网络。从功能方面来讲,AlphaGoZero中神经网络的作用是指导树搜索,而不是直接选择或评估动作。接下来,我们将详细地讲解这一过程。
1. 树节点及其动作分支
虽然不同的树搜索算法都有其各自的不同之处,但是核心思想都是在棋盘游戏中找到一个能产生最佳结果的动作。通常情况下,我们通过对选定动作进行推演来判断动作的好坏。但是由于要探索动作的深度和广度太大,导致时间复杂度过高,因此选择探索那个最合适的分支就成了树搜索算法要解决的核心问题。
和MCTS一样,AlphaGoZero的树搜索算法也会运行固定的轮次,每一轮都会向搜索树添加一个新的节点,这颗搜索树的每个节点都代表一个可能的棋局。与AlphaGo不同的是,每个节点不仅要储存下一个子节点,还要储存以该节点为当前状态,所有合法的下棋动作,无论这些动作是否被访问过,都会以该动作创建一个分支类,该分支类储存有以下信息:
[ 1 ] [1] [1] 先验概率:表示对于当前状态,该动作的好坏;
[ 2 ] [2] [2] 访问次数:表示在树搜索的过程中访问这个分支的次数,其初始化为0;
[ 3 ] [3] [3] 经过这个分支的所有访问的期望值:这个值是所有经过该分支的访问的平均值(每访问一次该分支,就会产生一个期望值)。
除了要储存所有动作的分支外,树节点还要出巡当前状态,上一步动作等信息。动作分支和树节点的代码表示如下(由于代码较为简单,这里将不做讲解):
class Branch:
def __init__(self, prior):
self.prior = prior
self.visit_num = 0
self.total_value = 0.0
class TreeNode:
def __init__(self, board_state, state_value, priors, parent, last_move):
self.board_state = board_state
self.state_value = state_value
self.parent = parent
self.last_move = last_move
self.total_visit_count = 1
self.branches = {
}
for move, prob in priors.items():
if board_state.is_valid_move(move):
self.branches[move] = Branch(prob)
self.children = {
}
def get_moves(self):
return self.branches.keys()
def add_child(self, move, child_node):
self.children[move] = child_node
def has_child(self, move):
return move in self.children
def get_child(self, move):
return self.children[move]
def get_move_expected_value(self, move):
branch = self.branches[move]
if branch.visit_num == 0:
return 0.0
else:
return branch.total_value / branch.visit_num
def get_move_prior(self, move):
return self.branches[move].prior
def get_move_visit_num(self, move):
if move in self.branches:
return self.branches[move].visit_num
else:
return 0
def record_visit(self, move, value):
self.total_visit_count += 1
self.branches[move].visit_num += 1
self.branches[move].total_value += value
2. 选择要探索的动作分支
那么,我们该如何选择要探索的分支呢?在AlphaGoZero树搜索中,首先同样需要平衡深入挖掘(Exploitation)和广泛探索(Exploration)这两个目标。具体来说,我们既可以在几个最好的分支中选择一个进行更加深入的探索,进一步提高其估计的准确性;又可以深入探索那些访问次数少,但有可能对未来棋局具有良好影响的分支,来改善他们的估计水平。在之前介绍AlphaGo的时候我们知道,MCTS算法通过使用搜索树最大置信上界(UCT)来平衡这两个目标,而在AlphaGoZero中,我们使用如下公式对动作分支进行评估:
a ′ = a r g m a x a [ Q ( a ) &#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1085
1085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









