







文章目录
一、DeepSpeed 简介
本部分内容主要转载自:大模型训练框架 DeepSpeed 详解
DeepSpeed 是一个由微软研究院开发的深度学习优化库,它主要针对大规模分布式训练进行了优化,尤其是在使用大量 GPU 进行训练时可以显著提高效率。DeepSpeed 旨在降低模型并行和数据并行的通信开销,同时提供了一系列工具来帮助研究人员和开发者更容易地训练大型模型。
DeepSpeed 的主要特性包括:
- ZeRO (Zero Redundancy Optimizer):这是一种减少内存使用的优化器,通过将模型状态分布在多个 GPU 上来减少内存占用。
- 混合精度训练:支持 FP16 和 BF16 训练以减少内存使用并加速计算。
- 流水线并行性:允许在不同的 GPU 上进行模型层的分割,从而有效地利用硬件资源。
- 动态梯度累积:根据可用的 GPU 内存自动调整梯度累积步骤。
- 集成支持:对流行的深度学习框架如 PyTorch 提供了很好的支持。
1.1 核心特性
1.1.1 ZeRO (Zero Redundancy Optimizer)
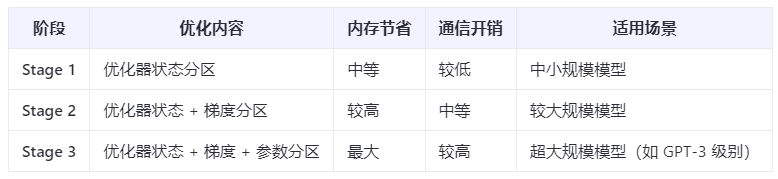
ZeRO 是 DeepSpeed 中的一个核心组件,它通过减少内存占用和优化通信来提高模型训练的效率。ZeRO 提供了三个不同的级别(stage)来控制冗余和通信的减少程度:
ZeRO Stage 1: 优化器状态分区
- 实现:在传统的数据并行训练中,每个 GPU 都会保存模型参数、梯度以及优化器状态(如动量、方差等)的完整副本。这些优化器状态通常占用了大量显存。ZeRO Stage 1 将优化器状态分布在多个 GPU 上,每个 GPU 只存储部分优化器状态,而不需要存储完整的副本。
- 目标:减少优化器状态的内存占用。
ZeRO Stage 2: 梯度分区
- 实现:在 Stage 1 的基础上,ZeRO Stage 2 不仅对优化器状态进行分区,还对梯度进行分区。每个 GPU 只存储部分梯度,而不是完整的梯度。 在反向传播完成后,各 GPU 之间通过通信操作聚合梯度,以完成优化器更新。
- 目标:进一步减少梯度的内存占用。
ZeRO Stage 3: 参数分区
- 实现:在 Stage 2 的基础上,ZeRO Stage 3 将模型参数也分布在多个 GPU 上。每个 GPU 只存储部分模型参数、部分梯度和部分优化器状态。 在前向传播和反向传播过程中,GPU 需要动态地从其他 GPU 获取所需的参数。这需要高效的通信机制来保证性能。
- 目标:完全消除冗余,将模型参数也进行分区。
总结对比如下:
1.1.2 混合精度训练
DeepSpeed 支持 FP16 和 BF16 等低精度格式进行训练,这有助于减少内存消耗和加速计算过程。混合精度训练通常涉及以下几个方面:
- FP16/BF16 计算:模型中的大多数计算使用 FP16(推理时候经常使用) 或 BF16(训练时候经常用) 进行,以减少内存使用和加速计算。
- 动态损失缩放:由于 FP16 的数值范围较小,可能遇到下溢问题。DeepSpeed 自动调整损失缩放因子来避免下溢。
- 混合精度优化:DeepSpeed 会自动管理 FP32 和 FP16 之间的转换,以保证训练的准确性和效率。
1.1.3 流水线并行性
对于非常大的模型,单个 GPU 的内存不足以容纳整个模型。DeepSpeed 的流水线并行性允许将模型的不同层分配到不同的 GPU 上,这样可以有效地利用更多的 GPU 资源。流水线并行性的关键点包括:
- 模型切分:将模型划分为多个部分,并将它们放置在不同的 GPU 上。
- 序列化执行:不同 GPU 上的模型部分按顺序执行,并通过管道传递数据。
- 流水线调度:DeepSpeed 会自动调度这些模型部分的执行顺序,以最大化效率。
1.1.4 动态梯度累积
梯度累积是在有限的 GPU 内存下进行训练的一种方法,通过累积多个小批量的梯度然后更新权重。DeepSpeed 支持动态梯度累积,这意味着它可以根据当前 GPU 内存的情况自动调整梯度累积的次数。
1.1.5 集成支持
DeepSpeed 支持多种深度学习框架,例如 PyTorch,并且提供了易于使用的接口来集成现有的训练流程。这意味着用户可以在几乎不修改现有代码的情况下引入 DeepSpeed 的优化功能。
1.2 应用示例
我们将使用 PyTorch 和 DeepSpeed 来训练一个简单的模型。假设我们要训练一个简单的多层感知器(MLP)模型,并使用 DeepSpeed 的各种特性来优化训练过程。以下是具体的步骤和代码示例。
首先需要安装 DeepSpeed
确保你的环境中已经安装了 NVIDIA CUDA 和 cuDNN。你可以使用 pip 或 conda 安装 DeepSpeed:
pip install deepspeed
步骤 1: 导入必要的库
import torch
import deepspeed
from torch.nn import functional as F
from torch.utils.data import DataLoader, TensorDataset
from torch import nn, optim
步骤 2: 定义模型
这里我们定义一个简单的 MLP 模型,包含两个隐藏层。
class SimpleMLP(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(SimpleMLP, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
步骤 3: 配置 DeepSpeed
我们将配置 DeepSpeed 来使用 FP16 混合精度训练、ZeRO 以及动态梯度累积。
ds_config = {
"fp16": {
"enabled": True, # 启用 FP16 训练
"initial_scale_power": 8
},
"zero_optimization": { # ZeRO 配置
"stage": 2, # 使用 ZeRO 第二阶段
"allgather_partitions": True,
"allgather_bucket_size": 5e8,
"reduce_scatter": True,
"reduce_bucket_size": 5e8
},
"gradient_accumulation_steps": 2, # 动态梯度累积步数
"steps_per_print": 2000, # 打印间隔
"wall_clock_breakdown": False # 是否显示每个操作的时间分解
}
步骤 4: 初始化模型、优化器和数据加载器
# 初始化模型
input_dim = 100
hidden_dim = 50
output_dim = 10
model = SimpleMLP(input_dim, hidden_dim, output_dim)
# 初始化优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 构建数据集
x_train = torch.randn(1000, input_dim)
y_train = torch.randint(0, output_dim, (1000,))
dataset = TensorDataset(x_train, y_train)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# 初始化 DeepSpeed
model_engine, optimizer, _, _ = deepspeed.initialize(
model=model,
optimizer=optimizer,
config=ds_config
)
步骤 5: 训练循环
现在我们可以编写训练循环来训练模型了。
# 训练循环
num_epochs = 10
for epoch in range(num_epochs):
for batch_idx, (data, target) in enumerate(dataloader):
data, target = data.cuda(), target.cuda()
# 前向传播
output = model_engine(data)
loss = F.cross_entropy(output, target)
# 使用 DeepSpeed 进行反向传播和优化
model_engine.backward(loss)
model_engine.step()
if batch_idx % 10 == 0:
print(f'Epoch: [{epoch+1}/{num_epochs}], '
f'Batch: [{batch_idx+1}/{len(dataloader)}], '
f'Loss: {loss.item():.6f}')
说明
- 模型定义 (
SimpleMLP): 我们定义了一个简单的多层感知器模型。 - 配置 DeepSpeed (
ds_config): 配置文件指定了 FP16 混合精度训练、ZeRO 的第二阶段以及梯度累积步数。 - 初始化 DeepSpeed (
deepspeed.initialize()) : 使用提供的配置初始化模型和优化器。 - 训练循环 (
for epoch in range(num_epochs)): 在每个批次中,我们执行前向传播、计算损失、使用 DeepSpeed 进行反向传播和梯度更新。
这个例子展示了如何使用 DeepSpeed 的关键特性来优化模型训练过程。请注意,为了运行这段代码,你需要有一个支持 CUDA 的环境,并且确保你已经正确安装了 DeepSpeed 和其他依赖项。此外,对于分布式训练,还需要额外配置启动脚本以使用多 GPU 或多节点。
二、分布式训练原理
本部分内容主要参考:
做分布式训练,要么是单节点显存不够,要么是算力不够。算力主要是各种矩阵运算啦,GPU硬件本身就是为这种计算定制的,软件层面无法明显优化,所以分布式系统主要优化的就是显存的占用啦!
2.1 单机单卡/多卡训练显存
(1)先看看单机单卡训练时的显存占用,假设模型的参数量是m:
- 参数本身存储需要显存,用FP32和FP16混合精度存放,需要6m显存
- 梯度保存:用FP16存放,需要2m显存
- optimizer优化器:以adam为例,梯度下降的时候要存梯度和梯度平方,每个参数要存2个状态,需要8m显存

在不考虑存放训练数据的前提下,pre-train至少需要6m+2m+8m=16m的显存(1B参数占用1GB显存),所以后续的重点就是怎么优化这三部分显存占用啦!
(2)先来看看最简单的一种情况:data parallel,简称DP。假设有N个显卡:
- 就是把训练数据均分成N份,然后N个显卡同时做forward和backward;N块显卡网络的初始参数都是一样的
- 产生的gradient都发送给某个特定的显卡(这里用0号显卡表示)
- 0号显卡根据gradient更新自己网络的参数,然后把新的参数广播发送给其他所有显卡,让所有显卡的网络参数保持一致
- 除了0号显卡,其他显卡的作用就是计算loss和梯度

这种DP方式的缺陷很明显:0号显卡要收集其他所有显卡梯度,更新参数后要把新的参数广播给所有显卡,显卡之间的通信量很大,具体同步的数据量和显卡数据是线性正比的关系!
(3)DP的改进版:distributed data parallel,简称DDP;和DP比,每块卡单独生成一个进程;
- 数据照样均分成,N个显卡同时做forward和backward;N快显卡网络的初始参数都是一样的
- 因为每张卡的数据不同,所以loss和梯度肯定不同,此时通过Ring-allReduce同步梯度,让每张卡的梯度保持一致
- 每张卡根据梯度更新自己的网络参数;因为每张卡的loss和梯度是要通过Ring-allReduce互相同步的,并且网络的初始状态也是一样的,所以每张卡的optomizer和网络状态始终是一样的!

显卡集群总的数据传送量:因为使用了Ring-allReduce传输数据(每个结点只给下一个结点传输数据,并不是整个集群广播),所以总的传入传出总量是固定的,不会因为显卡集群扩大导致数据传输大增!

Ring-allReduce 原理:显卡之间通信,涉及到参数传递的,会让显卡组成虚拟环,环内每个显卡的每个维度都依次给下一个显卡发送数据,直到每个显卡的参数都一样位置,这期间的经历称为
scatter-reduce和all-gather。
scatter-reduce:单个维度向下扩散依次累加;这里一看到reduce,就想起了10多年前因大数据爆火的map-reduce框架;这里的reduce功能和map-reduce的功能原理上一模一样,没本质区别!
all-gather:单个完成的维度往下扩散,确保其他显卡该维度的数据是正确的!
注意:
在Ring-allReduce中,每块显卡都在发送和接受数据,可以最大程度利用每块显卡的上下行带宽(并不是漫无目的的无脑广播)!


2.2 ZeRO技术
上述的DP和DDP,通过分布式增加了算力,但缺陷还是很明显的:并未节约显存!所以由此产生了ZeRO技术!
2.2.1 ZeRO-1:optimizer
预训练时,optimizer占用8倍参数量的显存空间,是最耗费显存的,所以肯定先从这种“大户”下手啦!
前面的DP和DDP,每块显卡都保存了完整的optimizer,互相都有冗余,能不能消除这个冗余了?比如集群有3块显卡,每块显卡只存1/3的optimizer状态?
这就是ZeRO-1的思路!举个栗子:transformer不论decoer还是encoder,不是由一个个block上下叠加组成的么?比如有12个block、3块显卡,那么每块显卡存储4个block的optimizer,不就ok啦?
- 数据照样均分成,N个显卡同时做forward和backward;N快显卡网络的初始参数都是一样的
- foward时所有显卡可以并行(因为都存储和FP16的网络参数),然后各自计算loss和梯度
- 最关键的就是BP了:现在每块显卡只存了部分optimizer,怎么做BP更新参数了?
- 因为每块显卡都有完整的FP16网络参数,所以每块显卡都可以并且需要根据loss计算梯度
- 最后4个block的optimizer是GPU2负责,所以GPU0和1并不更新这4个block的参数。但是更新参数涉及梯度啊,GPU2的loss和梯度信息不完整,这时就需要GPU0和1把自己计算的梯度信息发送给GPU2,整合后计算mean,用于更新最后4个block的参数!
- 同理,中间4个block的梯度由GPU0和2发送给CPU1,GPU1整合后计算mean,用于更新中间4个block的参数!最前面4个block的梯度由GPU1和1发给GPU0,GPU0整合后计算mean再更新网络参数!
- 3块显卡更新了各自负责block的网络参数,然后互相广播,至此:每块GPU的网络参数都是最新的了!

通信量分析:和DDP是一样的,但是每块显卡节约了显存!最核心的就是每块显卡都把不属于自己负责那段网络的梯度发送给指定负责的网卡,并未盲目全体广播,此处节约了带宽!但因为每块显卡要广播更新后的网络参数,所以网络通信相比DDP并未减少!

2.2.2 ZeRO-2:optimizer+梯度
既然每块GPU只负责更新部分参数,那是不是只保存对应的梯度也行了?这就是ZeRO-2的思路!
- 数据照样均分成,N个显卡同时做forward和backward;N快显卡网络的初始参数都是一样的
- foward时所有显卡可以并行(因为都存储和FP16的网络参数),然后各自计算loss和梯度
- 做BP时:
- GPU0和GPU1计算出最后4个block的梯度后发给GPU2,让GPU2更新optimizer和网络参数,这部分的梯度自己都丢弃,完全不存;
- 其他两个block的参数做法类似,不再赘述
- 最后3块显卡再互相广播更新后的网络参数

2.2.3 ZeRO-3:optimizer+梯度+参数
既然optimizer和梯度都可以只存部分,那参数是不是也可以了?这就是ZeRO-3的思路了!
但这次的情况又有点不同:网络参数都不完整,怎么forward?这就只能依靠广播了,需要用到的时候让其他GPU发过来!
- 数据均分成N份,同时做forward;但因为每块显卡的参数都不全,所以涉及到自己的时候要让其他显卡发过来;比如最前面4个block做forward,GPU0有,但是GPU1和2没有,就让GPU0广播;其他block同理,用的时候广播,用完就丢弃不存储!
- BP计算loss和梯度也要网络参数啊,咋办?同样还是广播的方式补全!

这种思路本质是需要用到的时候让其他GPU配合发送过来,用完就删除不存储!用显卡之间的带宽换显存的空间!通行量如下:

通行量是DDP的1.5倍,但是显存占用比DDP小了接近60倍!最后,来自ZeRO官方论文的总结对比:分别是DDP、ZeRO1/2/3阶段的显存消耗:
- baseline:(model param half) 2 + (model gradient half)2 + (optimizer master weight )4 + (optimizer Adam momentum)4 + (optimizer variance)4 = 16倍,所以7.5*16=120G
- 其他可以按比例缩放:比如deepseek 671B参数,使用zero-2全量参数微调,需要 (671/7.5)* 16.6 =1.5TB的显存!

2.3 ZeRO总结
ZeRO整体的思路就是:每块显卡不存放全部所需的数据,缺的数据在需要用到的时候由其他显卡提供!
实战中,一般采用ZeRO-2: 没有增加通信量,但是极大减少了显存的占用!官方也是首推ZeRO-2!
本质是用传输、内存等换显存的空间:总的计算量、存储量完全没少,不过是分散到不同的显存、内存了!

















 1045
1045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









