







文本相似度算法
杰卡德相似度,指的是文本A与文本B中交集的字数除以并集的字数,公式非常简单:
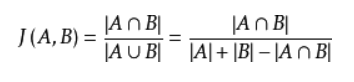
java代码
import java.util.HashSet;
import java.util.Scanner;
import java.util.Set;
public class StrJaccard {
public static void main(String[] args) {
System.out.println("请输入两个字符串");
Scanner sc = new Scanner(System.in);
String str1 = sc.nextLine();
String str2 = sc.nextLine();
Set<Character> s1 = new HashSet<>();//set元素不可重复
Set<Character> s2 = new HashSet<>();
for (int i = 0; i < str1.length(); i++) {
s1.add(str1.charAt(i));//将string里面的元素一个一个按索引放进set集合
}
for (int j = 0; j < str2.length(); j++) {
s2.add(str2.charAt(j));
}
float mergeNum = 0;//并集元素个数
float commonNum = 0;//相同元素个数(交集)
for(Character ch1:s1) {
for(Character ch2:s2) {
if(ch1.equals(ch2)) {
commonNum++;
}
}
}
mergeNum = s1.size()+s2.size()-commonNum;
float jaccard = commonNum/mergeNum;
System.out.println(jaccard);
}
}

















 1443
1443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











