






 本文探讨了深度学习在视觉应用中的算法评估,包括精确率、召回率和精度等指标,重点介绍了目标检测方法YOLO和风格迁移技术。同时,文章还涵盖了循环神经网络在自然语言处理中的应用,如序列模型、文本预处理和RNN模型的误差反传。
本文探讨了深度学习在视觉应用中的算法评估,包括精确率、召回率和精度等指标,重点介绍了目标检测方法YOLO和风格迁移技术。同时,文章还涵盖了循环神经网络在自然语言处理中的应用,如序列模型、文本预处理和RNN模型的误差反传。
一、深度学习视觉应用
1、算法评估
算法评估相关概念
TP: 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数
FP: 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数
FN:被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数
TN: 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数
P(精确率):𝑇𝑃/(𝑇𝑃+𝐹𝑃), 标识“挑剔”的程度
R(召回率): 𝑇𝑃/(𝑇𝑃+𝐹𝑁)。召回率越高,准确度越低 标识“通过”的程度
精度(Accuracy): (𝑇𝑃+𝑇𝑁)/(𝑇𝑃+𝐹𝑃+𝑇𝑁+𝐹𝑁)
2、目标检测与YOLO
目标检测问题 目标检测是在给定的图片中精确找到物体所在位置,并标注出物体的类别。
 语义分割:
语义分割:
FCN是目前广泛使用的基本语义分割网络
3.风格迁移:
使用卷积神经网络自动将某图像中的样式应用在 另一图像之上,即风格迁移。
方法
⚫ 首先,我们初始化合成图像,例如将其初始化成内容图像。该合成图 像是样式迁移过程中唯一需要更新的变量,即样式迁移所需迭代的模 型参数。
⚫ 然后,我们选择一个预训练的卷积神经网络来抽取图像的特征,其中 的模型参数在训练中无须更新。深度卷积神经网络凭借多个层逐级抽 取图像的特征。我们可以选择其中某些层的输出作为内容特征或样式特征
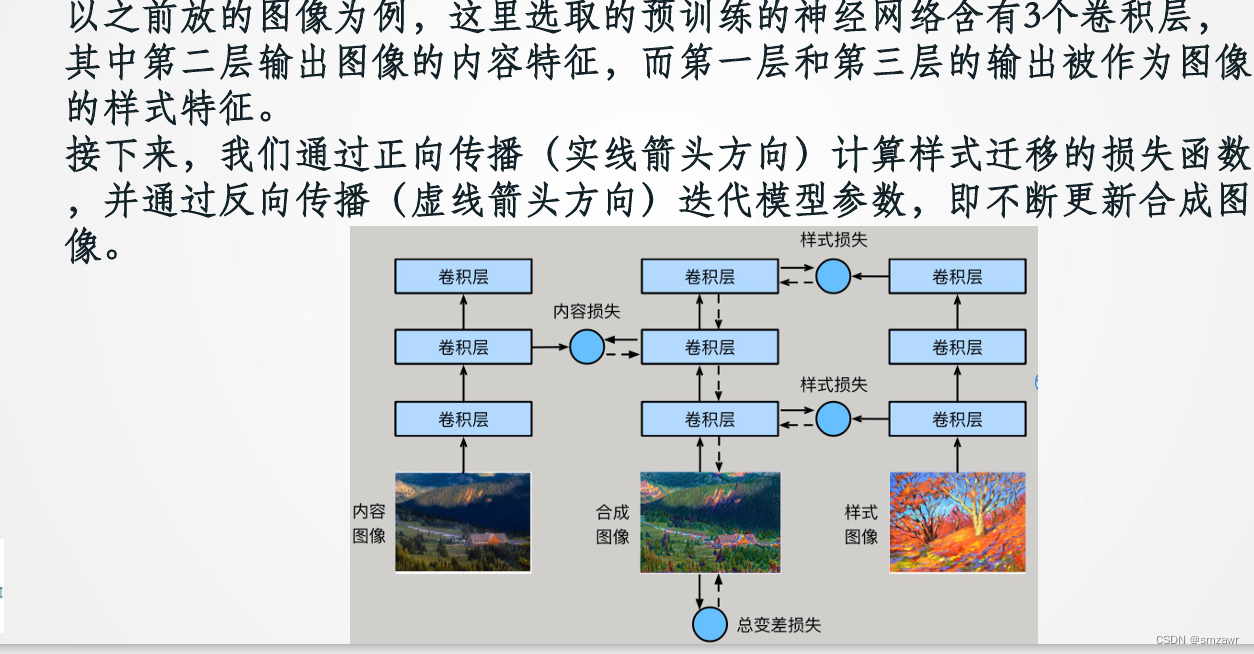
样式迁移常用的损失函数由3部分组成:
⚫ 内容损失(content loss)使合成图像与内容图像在内容特征上接近
⚫ 样式损失(style loss)令合成图像与样式图像在样式特征上接近
⚫ 总变差损失(total variation loss)则有助于减少合成图像中的噪点。 最后,当模型训练结束时,我们输出样式迁移的模型参数,即得到最终的合成图像。
二、循环神经网络与NLP
1、序列模型
⚫ 图像分类:当前输入−>当前输出
⚫ 时间序列预测:当前+过去输入−>当前输出
2、文本预处理
一篇文章可以被简单地看作一串单词序列,甚至是一串字符序列。 我们将 解析文本的常见预处理步骤。 这些步骤通常包括: 1.将文本作为字符串加载到内存中。
2.将字符串切分为词元(如单词和字符)。
3.建立一个字典,将拆分的词元映射到数字索引。
4.将文本转换为数字索引序列,方便模型操作。
3、RNN模型
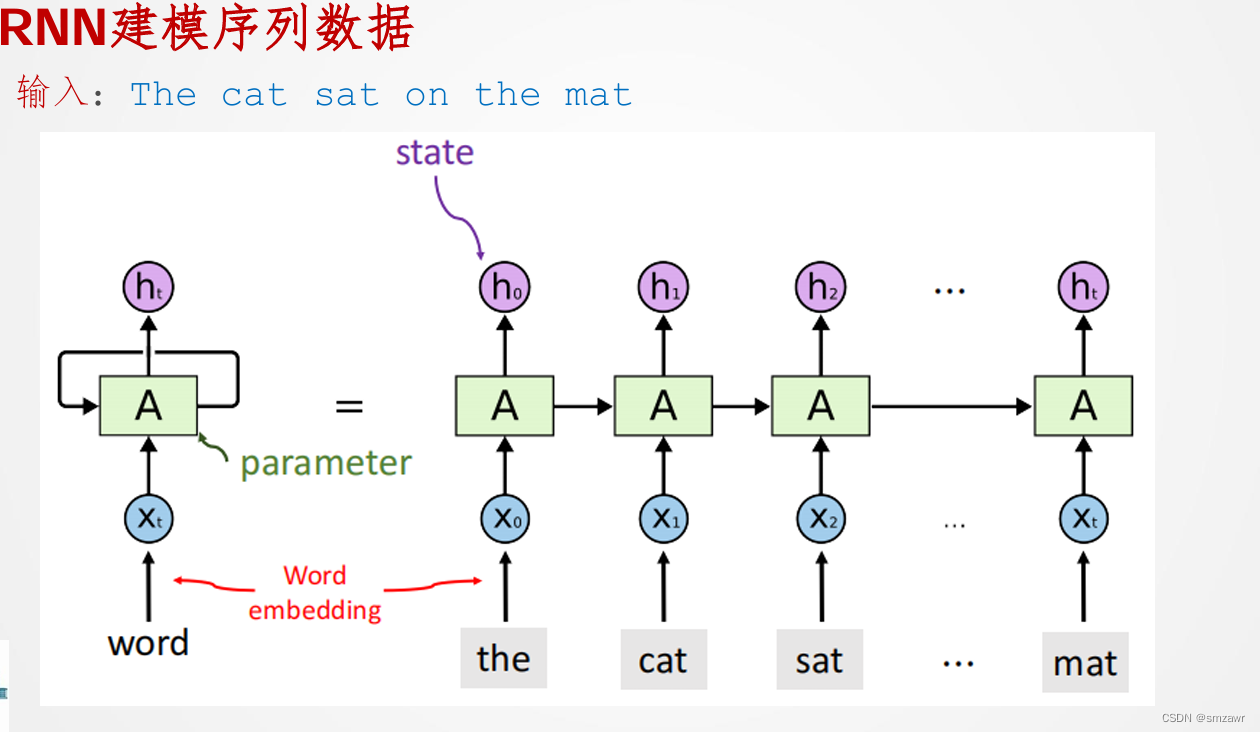
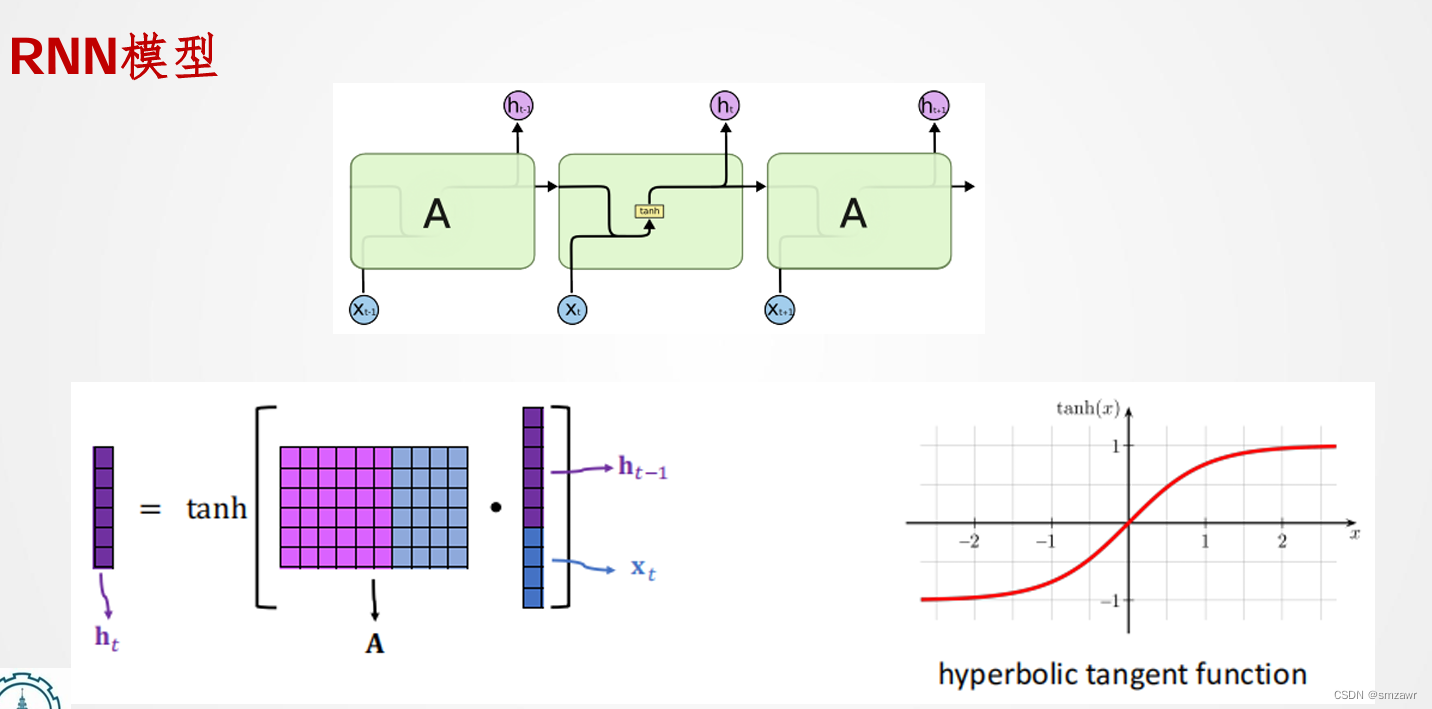
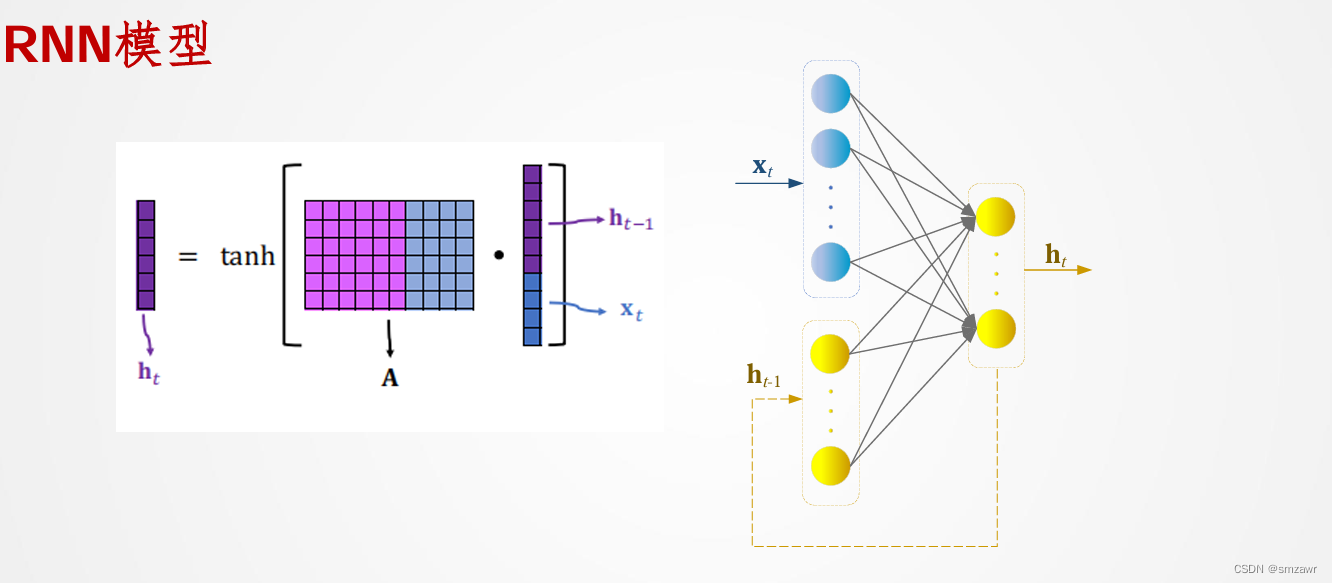
4、RNN误差反传

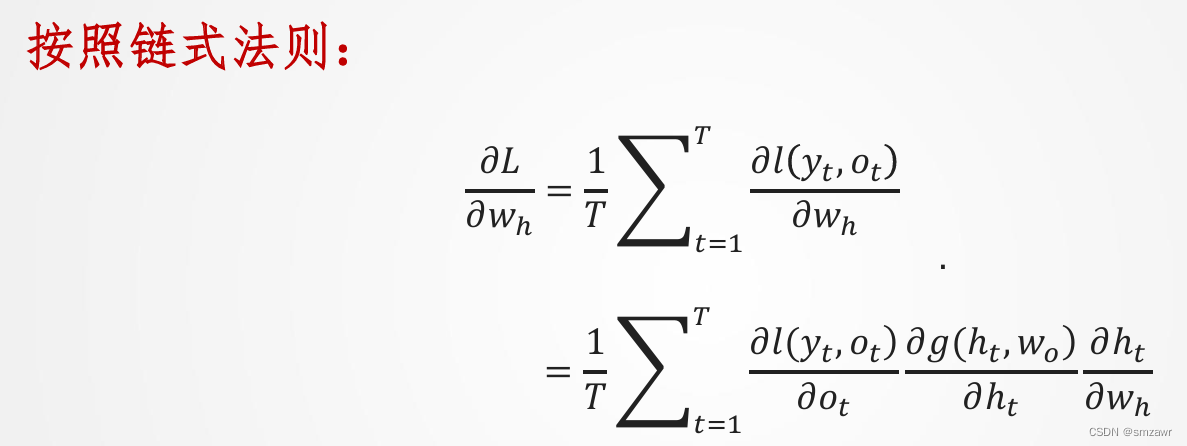
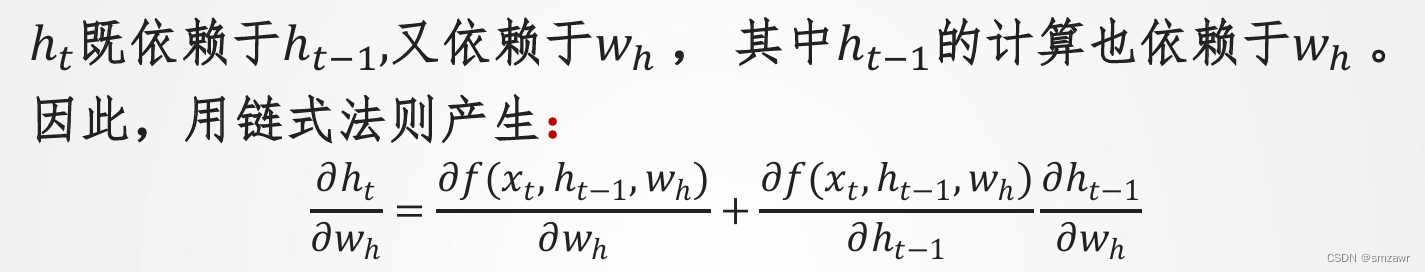
















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









