






1.介绍
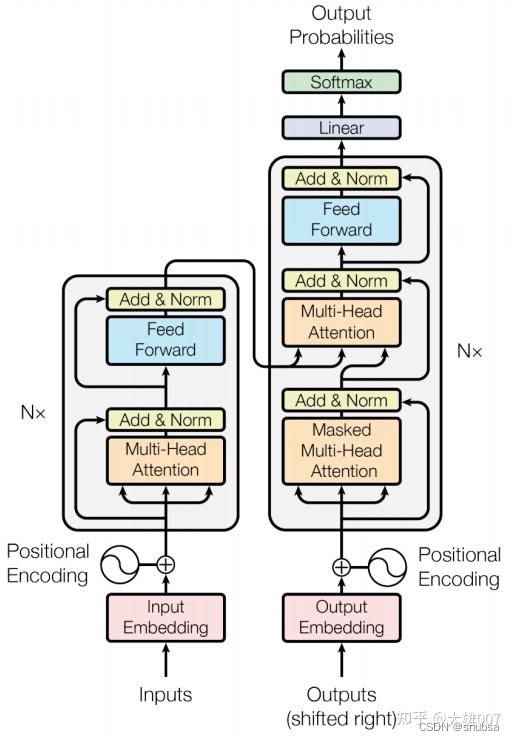
Transformer 网络架构架构由 Ashish Vaswani 等人在 Attention Is All You Need一文中提出,并用于机器翻译任务,和以往网络架构有所区别的是,该网络架构中,编码器和解码器没有采用 RNN 或 CNN 等网络架构,而是采用完全依赖于注意力机制的架构。网络架构如下所示:
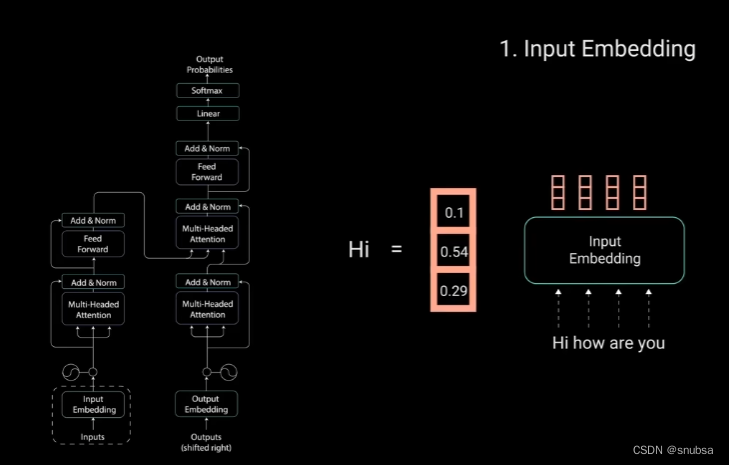
2. Input Embedding
如下图,将句子分成词,再将单词放入Input Embedding 变成词向量
3. Positional Encoding
这层的作用是将位置信息注入到输入嵌入层中,通过奇偶位置信息+正余弦函数实现,如下图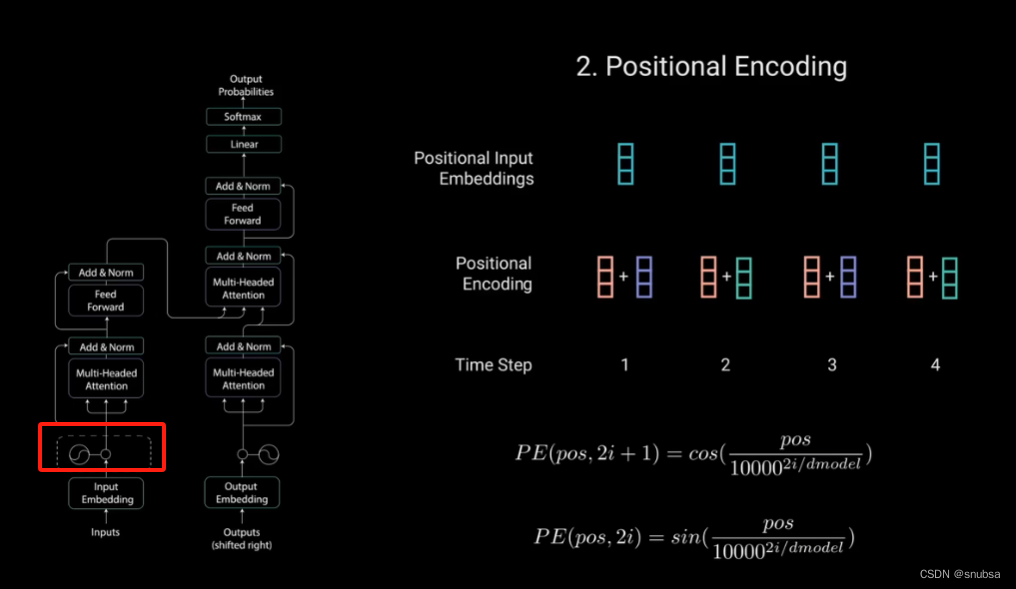
通过以上步骤后,我们得到了输入序列
4 Encoder Layer
编码器层包括两个子模块,多头注意力层和一个全连接网络。这两个子模块周围还有残差连接,后面跟着层标准化。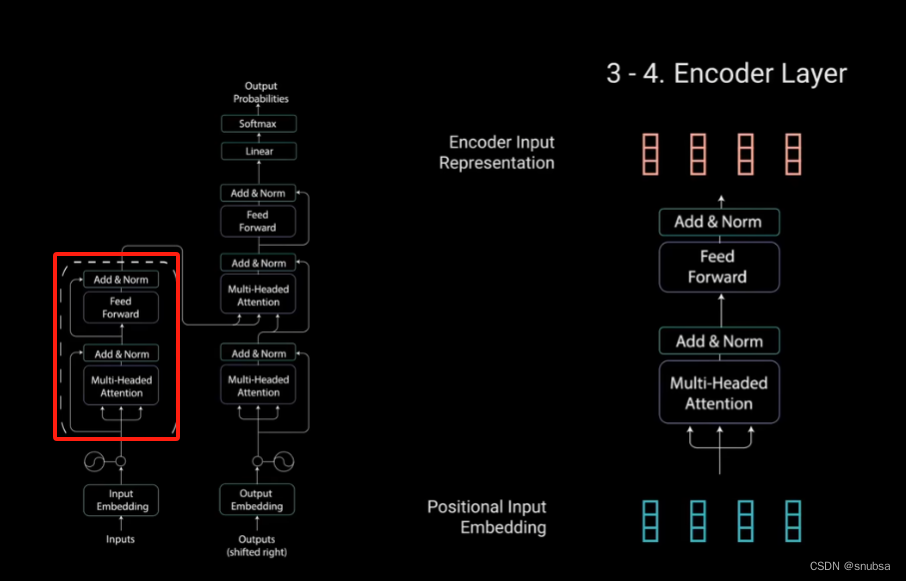
4.1 Self-Attention
自注意力机制
为了实现自注意力,我们将输入分别送入三个不同的全连接层,以创建查询向量、键向量和值向量
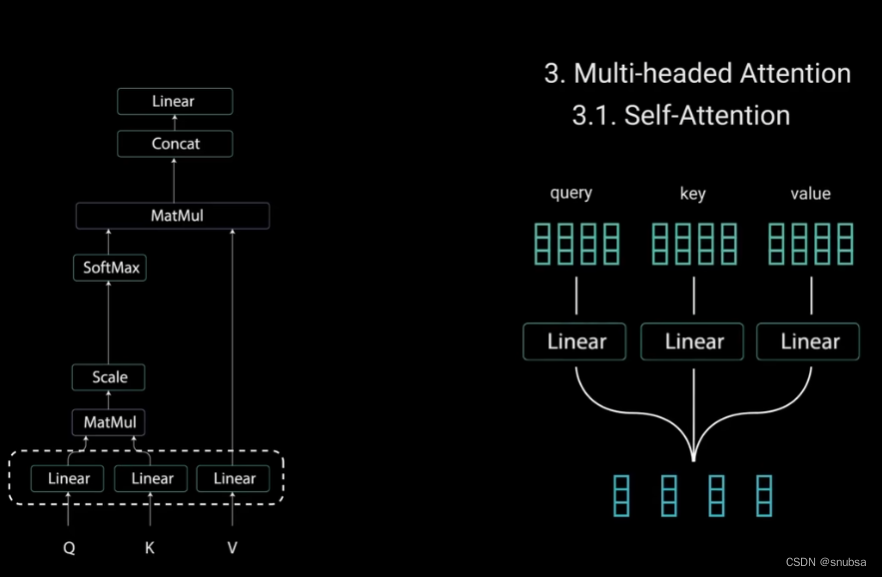
查询和键经过点积矩阵乘法产生一个分数矩阵。分数矩阵确定一个单词对其他单词的注意力分数。
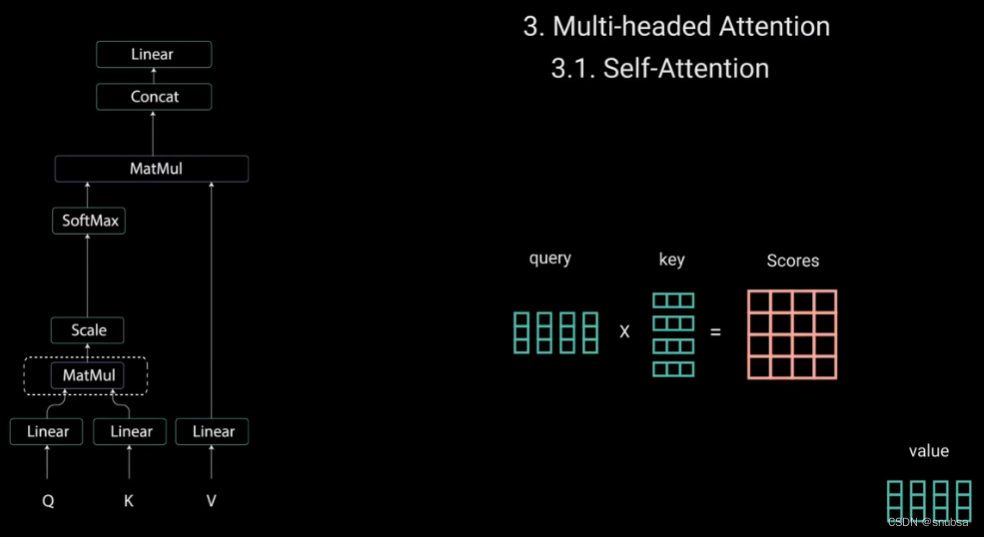

每个单词都会有一个与时间步长中其他单词对应的分数,分数越高,关注度越高。这就是Q矩阵如何映射到K矩阵的。
接下来就是对Q、K矩阵维度开平方来将得分缩放,让梯度更稳定。
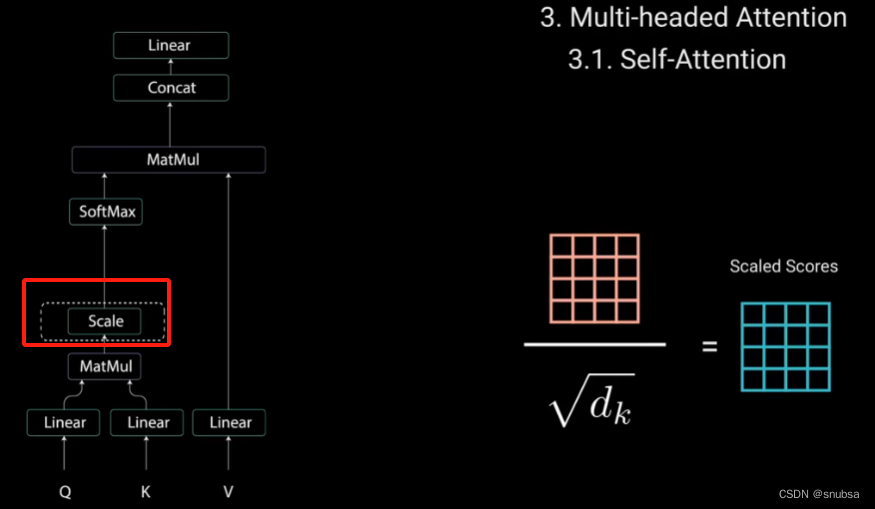
然后对缩放后的得分矩阵进行softmax计算,得到注意力权重,从而获得0~1之间的概率值
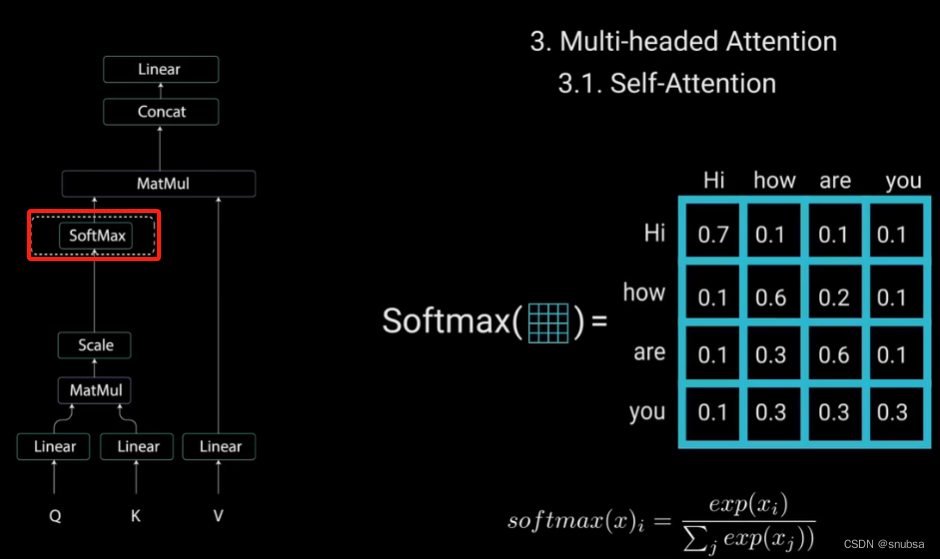
接着,将注意力权重与值向量相乘,得到输出向量。
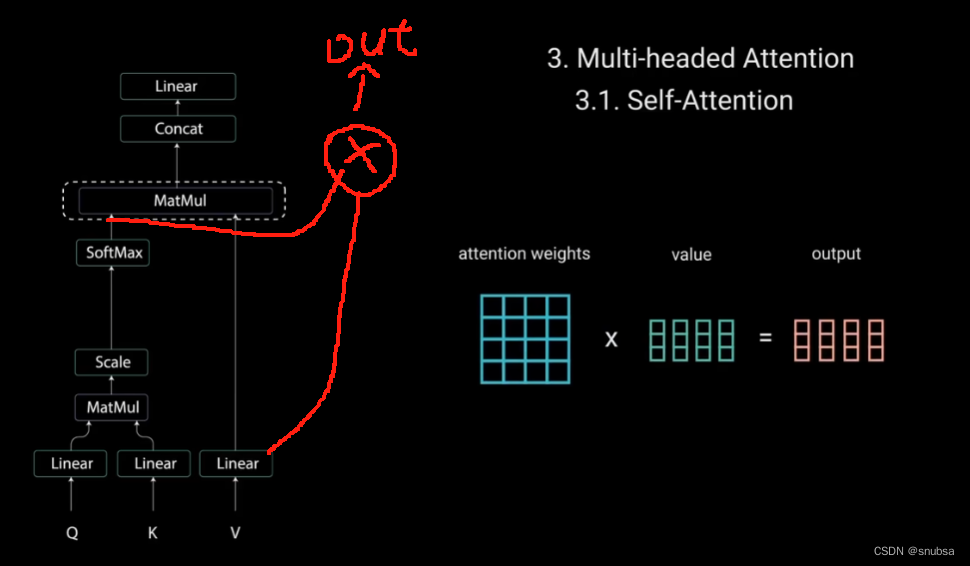
最后将输出的向量输入线性层进行处理。
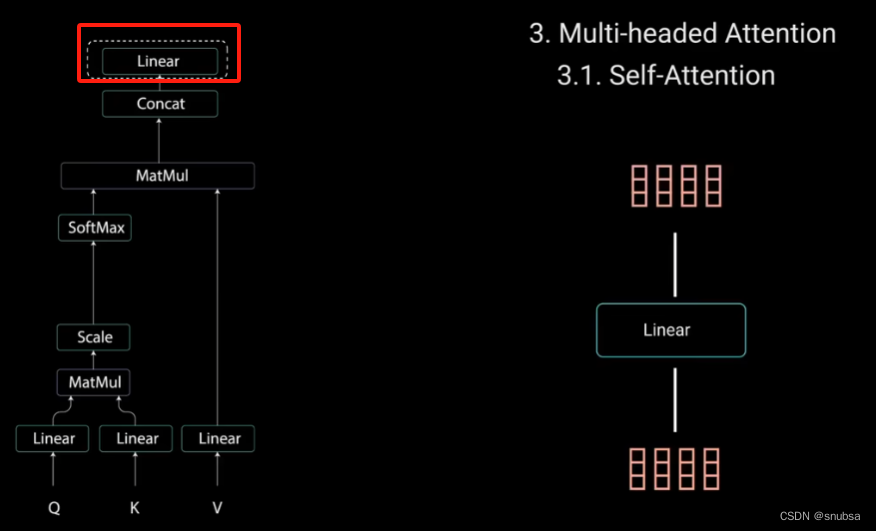
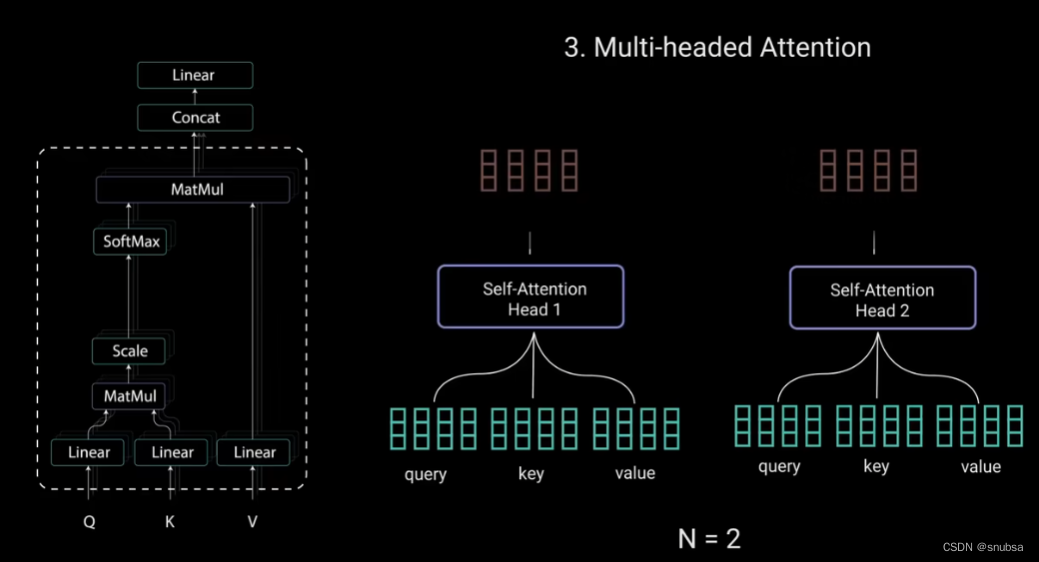
4.2 Multi-headed Attention
多头注意力
每个注意力过程称为一个头。每个头都会产生一个输出向量。
 这些向量在经过最后的线性层之前被拼成一个向量,假设下面的红短向量就是每个头的输出向量,经过拼接变成红长向量
这些向量在经过最后的线性层之前被拼成一个向量,假设下面的红短向量就是每个头的输出向量,经过拼接变成红长向量
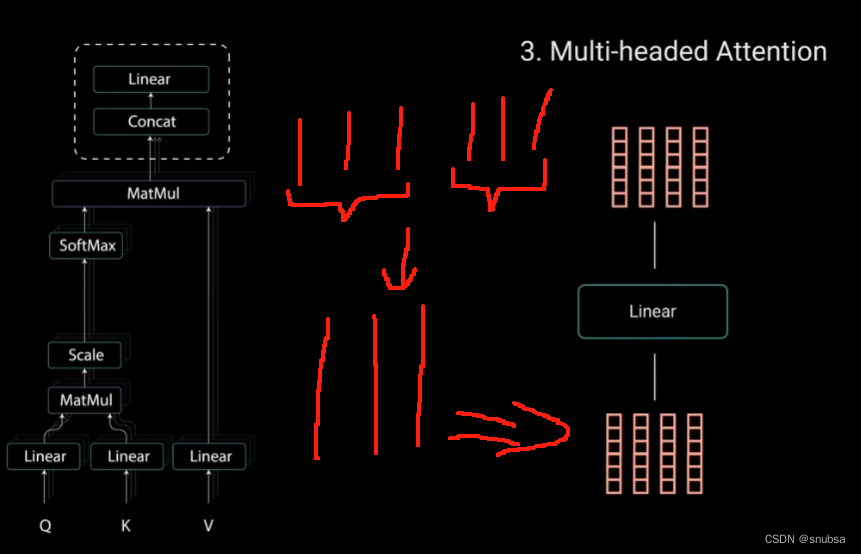
理论上,每个头都会学到不同的东西,从而为编码器模型提供更多的表达能力,这就是多头注意力。
4.3 Residual Connection,Layer Normalization&Pointwise Feed Forward
接下来,将多头注意力输出向量加到原始输入上,这是残差连接。
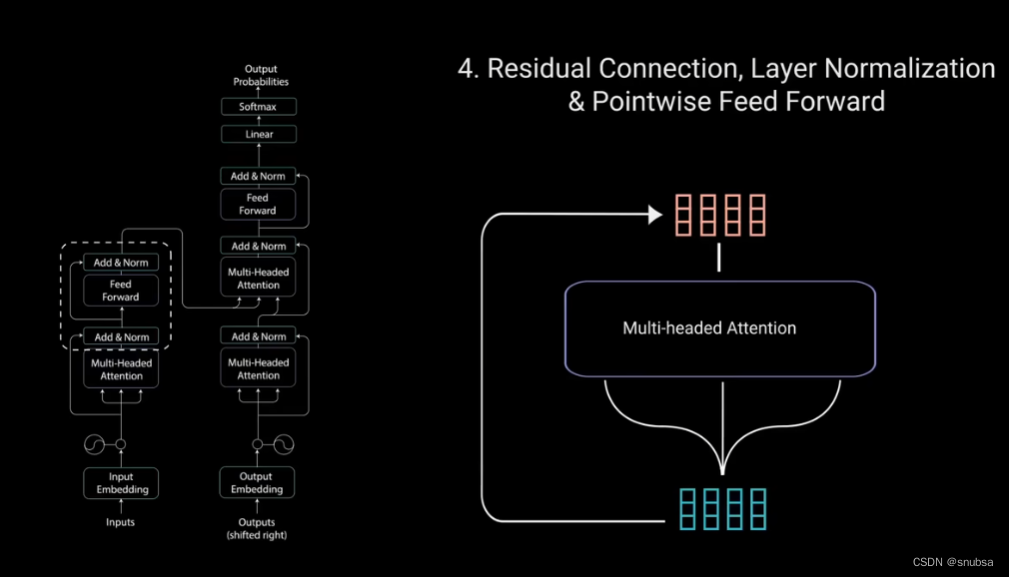
残差连接的输出经过层归一化,归一化后的残差输出送入点对点前馈网络进行处理。
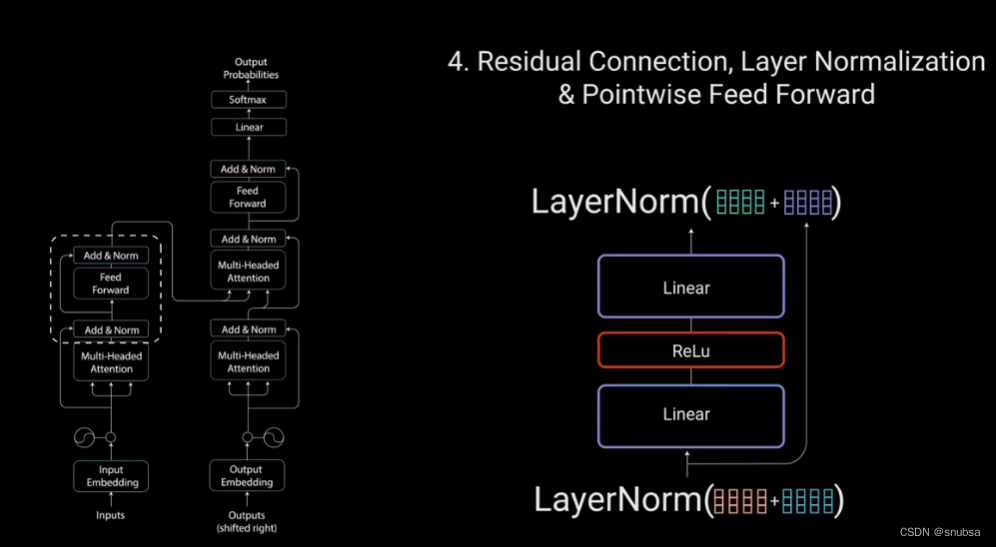
层归一化来稳定网络,减少所需的训练时间。
这就是编码层,所以的操作都是为了将输入编码为连续表示,带有注意力信息,帮助解码器在解码过程中关注输入中的适当词汇。
可以将解码器堆叠N次,每一层都能学到不同的注意力表示,从而提高Transformer网络的预测能力
5 Decoder
解码器的任务是生成文本序列,解码器具有与编码器相似的子层。两个多头注意力层、一个点对点前馈层、以及每层之后的残差连接和层归一化,最后由一个线性层和softmax来得到单词的概率。
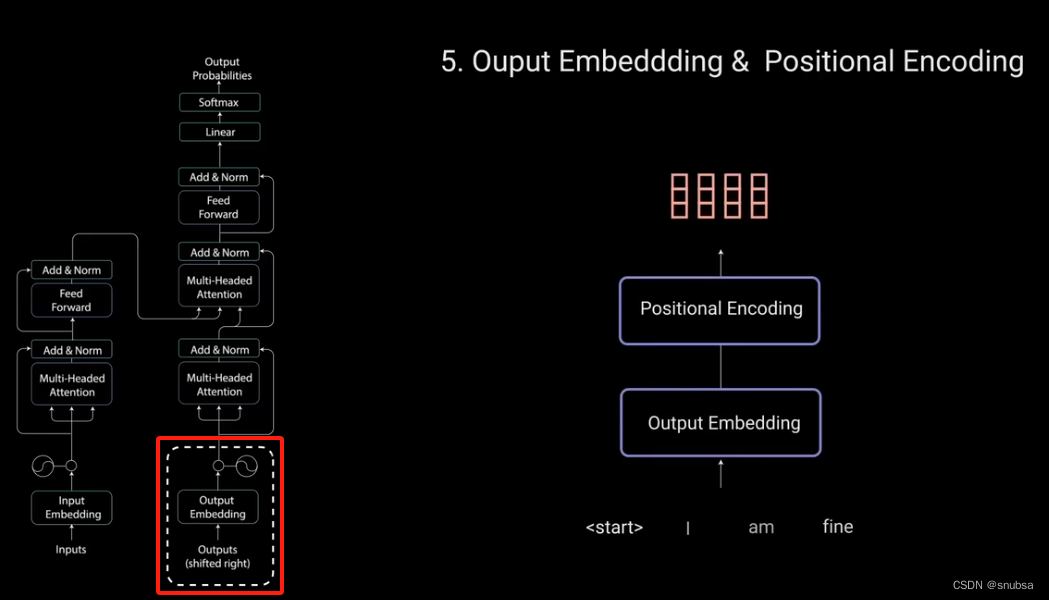
5.1 Output Embedding & Posititional Encoding
输入通过嵌入层和位置编码层,得到位置嵌入。位置嵌入被送到第一个多头注意力层,计算解码器输入的注意力得分。
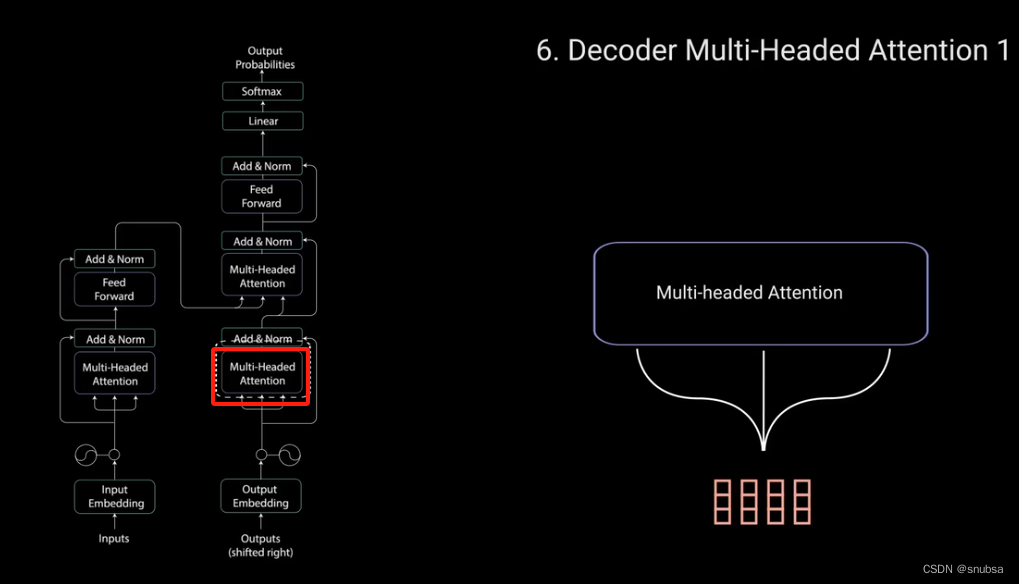
5.2 Decoder Multi-Headed Attention 1
解码器的多头注意力与编码器的稍有不同。因为解码器是自回归的,并且逐词生成序列,你需要防止它对未来的标记进行条件处理
例如,在计算“am”的注意力得分时,不应该访问单词“find”,因为那个单词是在am这个单词生成后得到的,未来词。应该只访问它自己和它之前的单词。

对于所有其他单词,它们只能关注之前的单词。我们需要一种方法来防止计算未来单词的注意力得分。
为了防止解码器查看未来的标记,我们需要应用一个前瞻性的Mask。在计算softmax和缩放得分后,Mask被添加。

用一个右上三角为负无穷大的矩阵其他位置为0,进行相加,得到带有右上角负无穷大的得分矩阵。这样做的目的是,一旦对Mask得分矩阵进行softmax后,负无穷大的值会变为0,从而为未来的标记留下0的注意力得分。
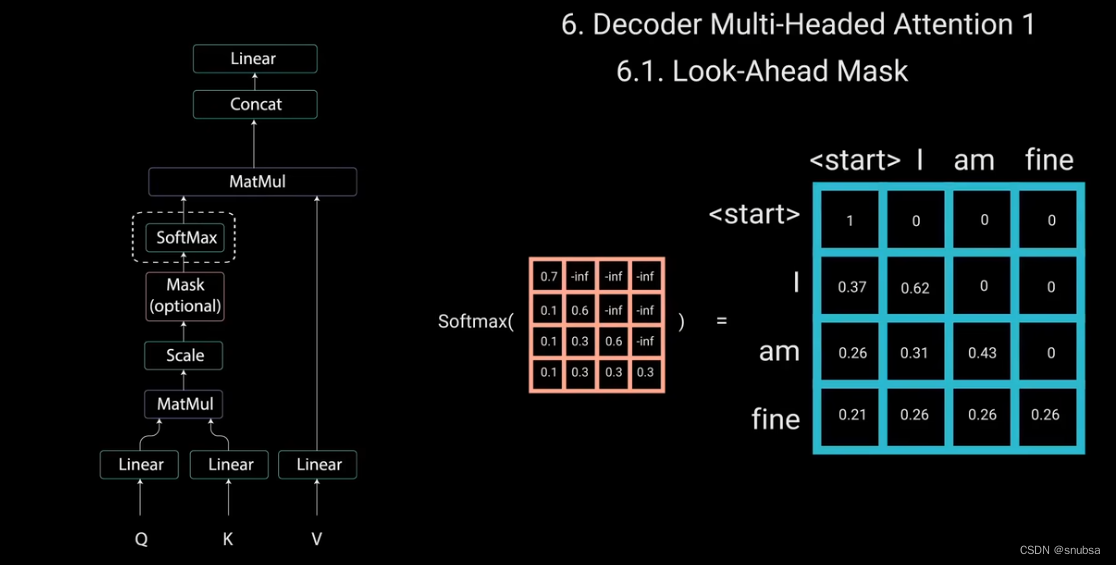
这样的话,对应单词am来说,它的注意力得分对于它自己和它之前的所有其他单词都有值,但对于‘find’则为零,这实质上是告诉模型不要去关注这些未来的单词。
这一个Mask是解码器与编码器自注意力的唯一区别。
解码器第一个多头注意力层输出的是一个带有掩码的输出向量,其中包括有关模型如何关注解码器输入信息。
5.3 Decoder Multi-Headed Attention 2
对应这层,编码器的输出是Q(查询)和K(键),而第一个多头注意力的输出是V(值);这三部分组陈解码器第二个多头注意力层的输入。
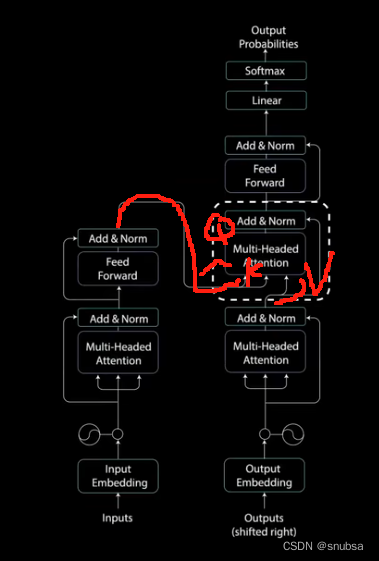
这个过程,将编码器输入与解码器输入进行匹配,允许解码器决定哪个编码器输入是相关的焦点。
第二个多头注意力的输出通过一个点对点前馈层进行进一步处理
5.4 Linear Classifier
最后,前馈层的输出经过一个最后的线性层,改层充当分类器。分类器的大小与你拥有的类别数相同。
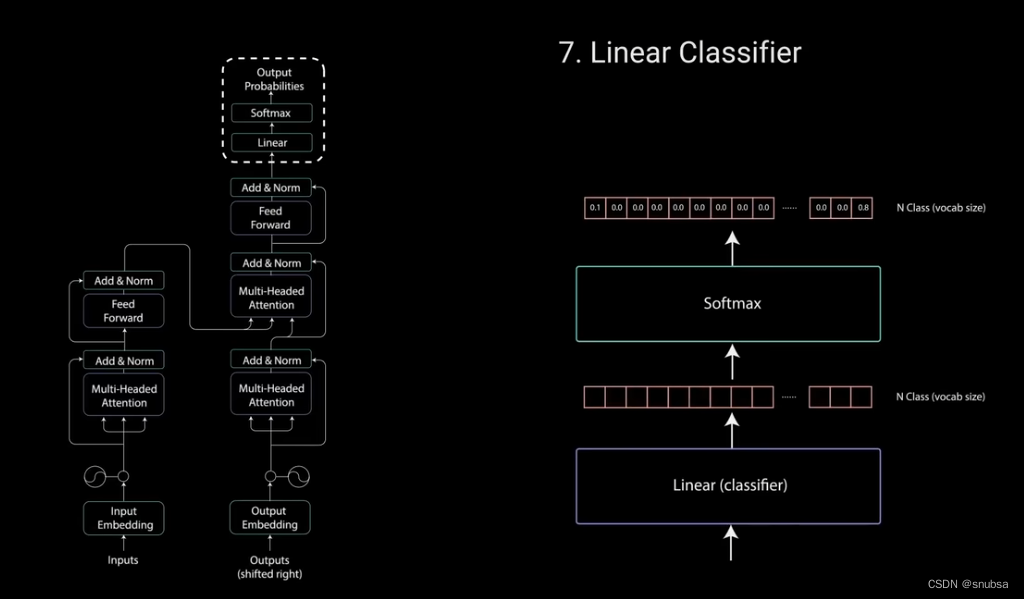
例如,如果你有10000个类别,表示10000个单词,那么分类器的输出大小将是10000。分类器的输出结果,将被送入到一个softmax层,用来为每个类别生成0~1之间的得分。去得分最高的索引,等于我们预测的单词。
然后,解码器将输出添加到解码器的输入列表中,并继续解码,直到预测出结束标记。
最后
解码器可以堆叠n层高,每层可以从编码器和其前面的层中获取输入
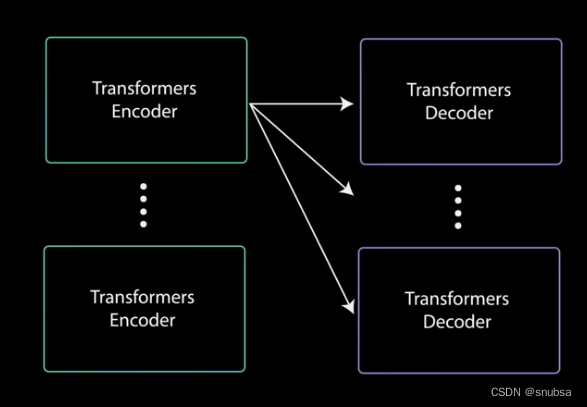
通过对叠层,模型可以学会从注意力头提取并关注不同的注意力组合,从而有可能提高预测能力。
这就是Transformer,变形金刚qaq!
更多信息可以从下面这个连接得到
https://www.bilibili.com/video/BV1ih4y1J7rx/?spm_id_from=333.337.search-card.all.click&vd_source=f7e3134a34316e151e59e4577ea75678















 1534
1534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









