









论文笔记:Interaction-and-Aggregation Network for Person Re-identification
论文:Interaction-and-Aggregation Network for Person Re-identification,cvpr,2019
链接:paper
代码:github
摘要
背景:人的再识别(reID)极大地受益于学习鲁棒特征嵌入的深度卷积神经网络(CNNs)。然而,CNNs由于其固定的几何结构,在建模人的姿态和尺度的巨大变化时具有固有的局限性。
贡献:本文提出了一种新的网络结构:交互-聚合(IA) 来增强CNNS的特征表达能力。首先,介绍了空间IA(SIA)模块。它对空间特征之间的相互依赖关系进行建模,然后对同一身体的相关特征进行聚合。它从固定的矩矩形区域中提取特征的cnn不同,SIA可以根据输入的姿势和比例来确定接收域。其次,文中引入了通道IA(CIA)模块,该模块有选择地聚集通道特征以增强特征表示,特别是对于小尺度视觉线索。此外,IA模块可以插入到CNNS中任意深度。我们验证了person ReID 模型的有效性。
引言
之前的一些方法对人体姿态和尺度变化不够鲁棒的一个重要原因是,它们都使用CNNs来提取行人特征。实际上,CNNs在建模大型几何变换时存在固有的局限性。这种限制源于CNNs模块固定的几何结构:一个在固定位置对输入特征图进行分离的卷积单元和一个按固定比例降低空间分辨率的池化层。缺乏处理身体姿势和尺度变化的内部机制。一方面,特征图的接受域是预先定义好的矩形,不能自适应地定位具有不同特征的非刚体部分。另一方面,同一CNN层中所有激活单元的接受域大小相同,这对于高级CNN层对不同尺度的身体部位进行语义编码是不可取的。
本文提出了一种新的网络结构——交互-聚合(IA),以提高CNNs的特征表示能力,特别是在存在身体姿态和尺度变化的情况下。AI包括两个模块:空间交互聚合(SIA)和通道交互聚合(CIA)。与提取固定几何结构特征的CNNs不同,SIA根据输入人图像的姿态和尺度自适应地确定接受域。SIA生成空间语义关系图以发现不同图像位置之间的两种类型的相互依赖关系:外观关系,其中具有相似特征表示的位置具有较高的相关性;以及位置关系,其中彼此靠近的位置往往具有较高的相关性。通过这种方式,具有各种姿势和比例的身体部位可以自适应地定位。在空间关系图的基础上,通过对不同位置上语义相关的特征进行聚合,实现对特征图的更新。与SIA原则相似,我们提出CIA进一步加强CNNs的表征能力。与CNNs不同,CIA显式地为通道间的语义依赖关系建模,而CNNs中不同通道的特征是独立假定的。特别是对于容易在cnn高级特征中消失的小尺度视觉线索(如bags),CIA可以有选择地将所有通道的视觉线索的语义相似特征进行聚合,以体现其特征表征。
这两个模块在计算上都是轻量级的,并且只略微增加了模型的复杂性。它们可以很容易地插入任何深度的深层CNNs 网络中。
网络结构
总体模型结构图如下:

1.SIA 模块
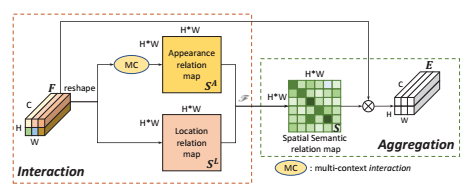
这里涉及到三个种相关性关系:Appearance Relations,Location Relations和semantic relations.
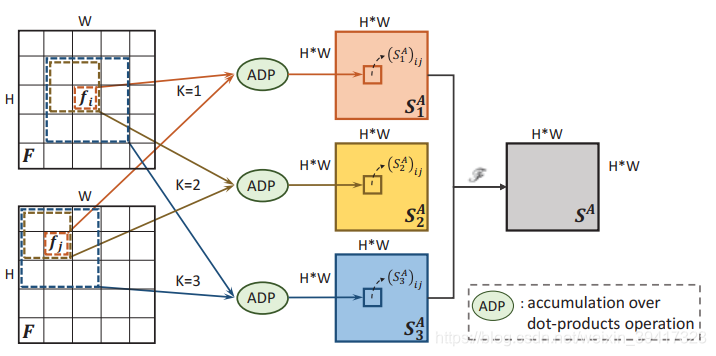
(1)外观关系部分,如上图所示,对每一张特征图,要计算出每一个点和其他点的相关程度,所以为了计算 f i 和 f j f_i 和 f_j fi和fj之间的外观相似性,首先分别提取像素点 i 和 j 周围的KxK 大小的patch 块,然后,通过累加相应位置的点积,作为特征图中的对应的点的值,然后使用softmax 对F 中的所有空间位置进行归一化,来获得外观相似性。公式如下:
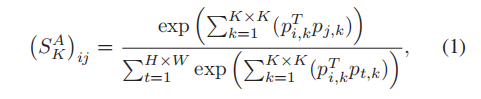
K的大小可以为1,2,…,因为当K=1时,仅仅计算一个点的视野有点狭小,所以文中使用了2x2的patch 块,图中黄色部分,和3x3的patch 块,图中蓝色部分。
文中将每个kxk 大小patch 得到的注意力图叫做单上下文关系图,通过融合单上下文关系图,得到多上下文关系图,融合公式如下:
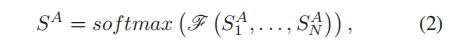
括号中是对得到的单上下文关系图进行对应位置点乘。括号中得到最后的feature mask,然后做softmax 得到 S A S^A SA。
(2)位置关系部分,来自邻近位置的特征具有更高的相关性。计算位置关系的公式如下:
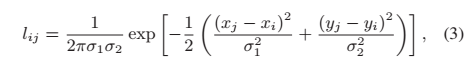
通过二维高斯函数计算的空间特征之间的位置关系,如果两个点的对应特征向量越相似,那么两个点之间,求二维高斯函数的响应就越大。其中xi,yi 和 xj,yj 分别表示 fi 和 fj 的位置坐标,然后我们对 l i j l_ij lij进行归一化.
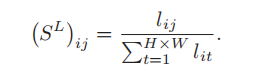
(3) 空间语义关系,表示为:
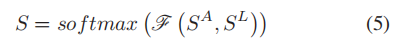
将 S A 和 S L S^A 和 S^L SA和SL 进行点乘,然后做softmax 操作进行归一化。
最后将原始图形F 和 注意力图S 进行聚类操作,(做矩阵乘法):
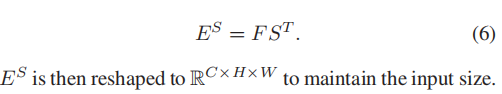
2.CIA模块
高层特征图的分辨率很小,有很多空间信息被压缩到channel中去了,因此就要从channel中去寻找这些信息,于是CIA产生

在两个不同的channe对语义相互依赖关系显式建模。有:
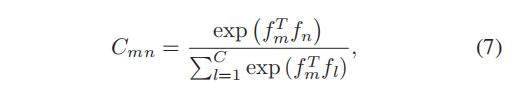
其中f m , f n ∈ R H W 表示F中第 m 个channel和第 n 个channel的特征。最终C m n 组成C ∈ R C ∗ C .然后:

这与SIA根据空间关系图聚集特征是互补的。
3.IA Block
SIA和CIA做成IA Block,这样就能插入到CNN的任意深度了。无论SIA还是CIA模块,IA Block定义为:
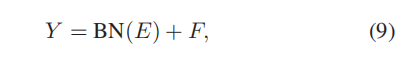
其中E是 E S 或 者 E C E^S或者E^C ES或者EC,并且还 + F 引入了残差结构。如下:

IA块可以插入网络的任何深度。考虑到计算的复杂性,我们只把它放在模型的瓶颈处,在那里进行特征图的下采样。位于不同层次瓶颈处的多个IA块可以用可忽略不计的参数逐步增强特征表示。
实验
1 实验细节

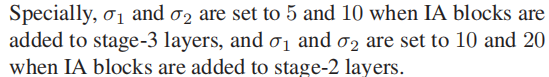
2 和SOTA比较

性能不算很高

3 消融

4 参数分析

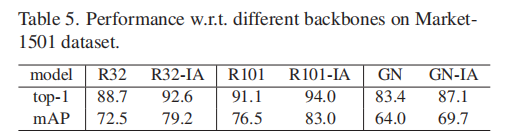
5. 不同backbone的影响
图6b中的stage1234可以是任意网络,称这个为backbone
6 .可视化示例

总结
论文中提出了一种IAnet 的网络框架,提升很大。但由于是使用全局特征进行ReID,效果不是特别好,与使用局部和全局相结合的特征表示还有一部分差距。不过文中的IANet 模块是对于ReID 有很大的帮助。















 2178
2178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









