






Why sigmoid + quadratic cost function learning slow?
The quadratic cost function is given by
where a is the neuron’s output.
where I have substituted x=1 and y=0 .
Recall the shape of the σ function:
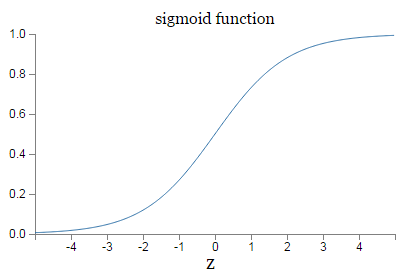
We can see from this graph that when the neuron’s output is close to 1, the curve gets very flat, and so σ′(z) gets very small. Equations (2) and (3) then tell us that ∂C/∂w and ∂C/∂b get very small.
Using the quadratic cost when we have linear neurons in the output layer. Suppose that we have a many-layer multi-neuron network. Suppose all the neurons in the final layer are linear neurons, meaning that the sigmoid activation function is not applied, and the outputs are simply aLj=zLj . Show that if we use the quadratic cost function then the output error δL for a single training example x is given by
δL=aL−y
Similarly to the previous problem, use this expression to show that the partial derivatives with respect to the weights and biases in the output layer are given by
∂C∂wLjk∂C∂bLj==1n∑xaL−1k(aLj−yj)1n∑x(aLj−yj).
This shows that if the output neurons are linear neurons then the quadratic cost will not give rise to any problems with a learning slowdown. In this case the quadratic cost is, in fact, an appropriate cost function to use.
sigmoid + cross-entropy cost function
The cross-entropy cost function
where n is the total number of items of training data, the sum is over all training inputs,
The partial derivative of the cross-entropy cost with respect to the weights. We substitute
Putting everything over a common denominator and simplifying this becomes:
Using the definition of the sigmoid function, σ(z)=1/(1+e−z) , and a little algebra we can show that σ′(z)=σ(z)(1−σ(z)) .
We see that the σ′(z) and σ(z)(1−σ(z)) terms cancel in the equation just above, and it simplifies to become:
This is a beautiful expression. It tells us that the rate at which the weight learns is controlled by σ(z)−y , i.e., by the error in the output. The larger the error, the faster the neuron will learn. In particular, it avoids the learning slowdown caused by the σ'(z) term in the analogous equation for the quadratic cost, Equation (2).
In a similar way, we can compute the partial derivative for the bias.
It’s easy to generalize the cross-entropy to many-neuron multi-layer networks. In particular, suppose
y=y1,y2,...
are the desired values at the output neurons, i.e., the neurons in the final layer, while
aL1,aL2,...
are the actual output values. Then we define the cross-entropy by
Softmax + log-likelihood cost
In a softmax layer we apply the so-called
softmaxfunction
to the
zLj
. According to this function, the activation
aLj
of the
j
th output neuron is
where in the denominator we sum over all the output neurons.
The log-likelihood cost:
The partial derivative:
These expressions ensure that we will not encounter a learning slowdown. In fact, it’s useful to think of a softmax output layer with log-likelihood cost as being quite similar to a sigmoid output layer with cross-entropy cost.
Given this similarity, should you use a sigmoid output layer and cross-entropy, or a softmax output layer and log-likelihood? In fact, in many situations both approaches work well. As a more general point of principle, softmax plus log-likelihood is worth using whenever you want to interpret the output activations as probabilities. That’s not always a concern, but can be useful with classification problems (like MNIST) involving disjoint classes.
overfitting
In general, one of the best ways of reducing overfitting is to increase the size of the training data. With enough training data it is difficult for even a very large network to overfit.














 6525
6525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









