








1 集合基础
1.1 集合体系
Java集合,也叫作容器,主要是由两大接口派生而来:一个是Collection接口,主要用于存放单值元素。另一个是Map接口,主要用于存放键值对。
对于Collection接口,下面又有三个主要的子接口:List、Set和Queue。List表示列表,存储的元素是有序的、可重复的。Set代表的是集合,存储的元素是无序的、不可重复的。Queue是按特定的排队规则来确定先后顺序,存储的元素是有序的、可重复的。每个接口都有一些具体的实现类,常用的有ArrayList、LinkedList、ArrayDeque、PriorityQueue、HashSet、LinkedHashSet、 TreeSet等等。
Map接口用于保存key-value数据,key不允许重复,通过指定的key,能够找到对应的value。Map接口的实现类主要有HashMap、LinkedHashMap和TreeMap。
1.2 容器和数组
如果没有容器,当我们需要保存一组类型相同的数据的时候,只能选择数组,数组的缺点是一旦声明之后,长度就不可变了。此外,集合还提供了数组无法提供的功能,比如数据的有序性,不重复性,映射关系等。
选择容器主要根据容器的特点来选用,比如我们需要根据键值获取到元素值时就选用Map接口下的集合,需要排序时选TreeMap,不需要排序时就选HashMap。当我们只需要存放元素的值时,就选择实现Collection接口的集合,需要保证元素唯一时选择实现Set 接口的集合比如TreeSet或HashSet,不需要就选择实现List接口的比如ArrayList或LinkedList。此外,如果需要保证线程安全的话,那么就可以选择Vector、Stack、HashTable、JUC包下集合。
1.3 集合遍历
单列集合遍历:for循环、增强for、迭代器
双列集合遍历:
- 使用迭代器(Iterator)EntrySet+ while…hasNext…next。
- 使用迭代器(Iterator)KeySet+ while…hasNext…next。
- 使用迭代器(Iterator)EntrySet+for循环。
- 使用迭代器(Iterator)KeySet+for循环。
- 使用Lambda表达式的方式进行遍历。
- 使用迭代器(Iterator)EntrySet+Streams API单线程的方式进行遍历。
- 使用迭代器(Iterator)EntrySet+Streams API多线程的方式进行遍历。
entrySet性能更好,因此遍历map对象时应该尽量使用entrySet。使用entrySet的性能更好是因为KeySet在循环时需要再使用map.get(key)查询key所对应的值。然而,EntrySet只遍历了一次map对象,之后通过代码“Entry<Integer, String> entry = iterator.next()”把对象的key和value值都放入到了Entry对象中,因此再获取key和value值时就无需再查询map对象,只需要从Entry对象中取值就可以了。所以,理论上遍历完整一次map对象,EntrySet的性能比KeySet的性能高出了一倍,因为KeySet相当于循环了两遍Map集合,而EntrySet只循环了一遍。
2 单列集合对比
2.1 Arraylist、Vector、LinkedList
- 线程安全性:Vector底层使用Object数组存储,线程安全的。ArrayList底层使用Object数组存储,适用于频繁的查找工作,不保证线程安全。LinkedList底层使用的是双向链表数据结构,不保证线程安全。
- 效率对比:ArrayList和Vector采用数组存储,随机插入与删除慢,但是查找快。LinkedList采用链表存储,所以随机插入与删除快,但是查找慢。
2.2 Deque和LinkedList
Deque是双端队列,在队列的两端均可以插入或删除元素:
- ArrayDeque和LinkedList都实现了Deque接口,两者都具有双端队列的功能。
- ArrayDeque是基于可变长的数组和双指针来实现,而LinkedList则通过链表来实现。
- ArrayDeque不支持存储NULL数据,但LinkedList支持。
- ArrayDeque插入时可能存在扩容过程,而LinkedList不需要扩容。
2.3 基于Deque实现栈与队列
栈顶是Deque的first端,也就是索引为0:
| 栈方法 | Deque方法 | 说明 | 备注 |
|---|---|---|---|
| push(e) | addFirst(e) | 入栈,失败则抛出异常 | |
| 无 | offerFirst(e) | 入栈,失败则返回false | 推荐 |
| pop() | removeFirst() | 获取并删除栈顶元素,失败则抛出异常 | |
| 无 | pollFirst() | 获取并删除栈顶元素,失败则返回false | 推荐 |
| peek() | getFirst() | 获取栈顶元素,失败则抛出异常 | |
| 无 | peekFirst() | 获取栈顶元素,失败则返回false | 推荐 |
队头是Deque的first端,也就是索引为0:
| 队列方法 | Deque方法 | 说明 | 备注 |
|---|---|---|---|
| add(e) | addLast(e) | 入队,失败则抛出异常 | |
| offer(e) | offerLast(e) | 入队,失败则返回false | 推荐 |
| remove() | removeFirst() | 获取并删除队首元素,失败则抛出异常 | |
| poll() | pollFirst() | 获取并删除队首元素,失败则返回false | 推荐 |
| element() | getFirst() | 获取队首元素,失败则抛出异常 | |
| peek() | peekFirst() | 获取队首元素,失败则返回false | 推荐 |
2.4 PriorityQueue
优先队列PriorityQueue与Queue的区别,在于PriorityQueue的元素的具有优先级,且优先级更高的先出队。PriorityQueue在面试中可能更多的会出现在手撕算法的时候,典型例题包括堆排序、求第K大的数、带权图的遍历等,所以需要熟练使用。
- PriorityQueue利用了二叉堆的数据结构来实现的,底层使用可变长的数组来存储数据
- PriorityQueue通过堆元素的上浮和下沉(元素堆化),实现了O(log n)的时间复杂度内插入元素和删除堆顶元素。
- PriorityQueue是非线程安全的,且不支持存储NULL和non-comparable的对象。
- PriorityQueue默认是小顶堆,有接收Comparator的构造参数,从而来自定义元素优先级的先后。
3 Map集合对比
3.1 HashSet
HashSet底层的实现其实是使用一个HashMap,只是将value固定了,把key作为HashSet的值。每次添加元素,使用的value都是同一个object对象。
3.2 TreeSet
TreeSet底层是红黑树,可以对对象元素进行排序,但是自定义类需要实现comparable接口,重写comparaTo()方法。TreeSet可以保证对象元素的唯一性(并不是一定保证唯一性,需要根据重写的comparaTo方法来确定)。
自定义类型的元素
public class Student implements Comparable{
private int age;
private String name;
@Override
public int compareTo(Object o) {
Student student = (Student)o;
return this.age - student.age;
}
}
3.3 HashMap和Hashtable
- HashMap是非线程安全的,Hashtable是线程安全的。因为Hashtable的方法基本都是同步方法,所以执行效率低一点。
- HashMap可以存储null的key和value,但null作为键只能有一个,null值可以有多个。Hashtable不允许有null键和null值,否则会抛出空指针异常。
- 容器初始容量:
- 创建时如果没给定初始值:Hashtable默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap默认的初始化大小为16,之后每次扩充,容量变为原来2倍。
- 创建时如果给定初始值:Hashtable会直接使用给定的大小,而HashMap会将其扩充为2的幂次方大小,也就是说HashMap总是使用2的幂作为哈希表的大小。
- 底层数据结构:HashMap的底层是数组+链表或者红黑树,Hashtable的底层是数组+链表。
3.4 HashMap、LinkedHashMap和TreeMap
- HashMap:
- JDK 7中,HashMap采用数组+链表。
- JDK 8中,HashMap采用数组+链表/红黑树。
- LinkedHashMap:LinkedHashMap继承自HashMap,所以它的底层仍然是基于数组和链表或红黑树组成。另外,LinkedHashMap在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。
- TreeMap:TreeMap底层是利用红黑树实现的Map结构,底层实现是一棵平衡的排序二叉树,由于红黑树的插入、删除、遍历时间复杂度都为O(logN),所以性能上低于哈希表。但是哈希表无法提供键值对的有序输出,红黑树可以按照键的值的大小有序输出。
4 ArrayList源码分析
4.1 ArrayList构造函数(默认大小为10)
private static final int DEFAULT_CAPACITY = 10; // 默认初始容量大小
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
// 默认构造函数,使用初始容量10构造一个空列表(无参数构造)
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {//初始容量大于0
//创建initialCapacity大小的数组
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {//初始容量等于0
//创建空数组
this.elementData = EMPTY_ELEMENTDATA;
} else {//初始容量小于0,抛出异常
throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity);
}
}
4.2 为什么elementData数组加上transient修饰
transient关键字的作用是被修饰的变量不参与序列化的过程。
ArrayList在进行序列化时会调用重写后的writeObject()方法,该方法直接将elementData数组大小和所有元素写入ObjectOutputStream。在进行反序列化时调用重写后的readObject()方法,从ObjectInputStream获取数组大小和所有元素,再写入到elementData数组中。
这样做的好处是:因为elementData是一个缓存数组,它通常会预留一些容量,等容量不足时再进行扩容。采用上诉的方式来序列化,只需要序列化实际存储的元素,从而节省空间和时间。
4.3 ArrayList扩容机制
每次扩容,新容量都会变为原来的1.5倍。然后检查新容量是否大于最小所需容量,若还是小于最小所需容量,那么就把最小需要容量当作数组的新容量。然后根据新容量创建一个新数组,最后将旧数组进行复制到新数组。具体过程为:
- 添加元素时需要调用add()和addAll()
- 在add()或addAll()方法中,会去调用ensureCapacityInternal()计算当前的最小所需容量(最小所需容量并不是简单地计算当前数组容量+新增元素的个数,而是还需要和ArrayList的默认初试容量DEFAULT_CAPACITY进行比较)
- 在ensureCapacityInternal()方法中,计算最小所需容量后,最后还会调用ensureExplicitCapacity比较最小所需容量和当前数组容量,来判断是否需要扩容
- 如果需要扩容就调用grow()进行扩容,在这个方法中,会将容量变为原来的1.5倍。如果此时,新容量还是小于最小所需容量,那么就会将新容量更新为最小所需容量。最后,将数组进行复制到一个新的扩容后的数组。
// 步骤1:添加元素时调用add()
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
// 步骤1:添加元素时调用addAll ()
public boolean addAll(int index, Collection<? extends E> c) {
…
ensureCapacityInternal(size + numNew); // Increments modCount
…
}
// 步骤2:调用ensureCapacityInternal()计算当前的最小所需容量
private void ensureCapacityInternal(int minCapacity) {
// calculateCapacity是去计算最小所需容量的
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
// 步骤3:调用ensureExplicitCapacity比较最小所需容量和当前数组容量,来判断是否需要扩容
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
if (minCapacity - elementData.length > 0)
grow(minCapacity); // 调用grow方法进行扩容,调用此方法代表已经开始扩容了
}
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
// 需要扩容就调用grow()进行扩容,在这个方法中,会将容量变为原来的1.5倍。
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
// 将新容量更新为旧容量的1.5倍,
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0) // 跟最小扩容量比较
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
4.4 迭代器Iterator和fail-fast快速失败机制
迭代器是用来获取之后实现集合的遍历的,特点是只能单向遍历,但是更加安全。因为它有一种称为快速失败fail-fast的机制,可以确保,在当前遍历的集合中有元素被更改的时候,就会抛出并发修改异常。
快速失败fail-fast的机制是一种错误检测机制,当线程1在遍历集合的时候,线程2修改了集合,这时就会产生fail-fast机制抛出并发修改异常。
实现原理:迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个modCount变量。集合在被遍历期间如果内容发生变化,就会改变modCount的值。每当迭代器使用hashNext()/next()遍历下一个元素之前,都会检测modCount变量是否为expectedmodCount值,是的话就返回遍历。否则抛出异常,终止遍历。
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
5 HashMap源码
5.1 HashMap
JDK 7采用的是拉链法,也就是说创建一个链表数组table,数组中每个元素都是一个链表,而链表的每一个元素是一个node对象。若遇到哈希冲突,则将冲突的值加到链表中即可。
JDK 8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认8)时,会调用 treeifyBin ()方法来决定是否转换为红黑树。只有当数组长度大于或者等于64的情况下,才会执行转换红黑树操作。否则,就是只是执行resize()方法对数组扩容。
5.2 HashMap扩容机制
扩容函数resize()主要是在调用put函数时调用到
- 首先判断数组table是否为null,如果是的话那么调用resize()创建Node数组。
- 否则根据key进行哈希运算得到插入的数组索引i:
- 如果table[i]为null,说明这个位置没有链表,那么直接新建节点添加,插入成功。
- 如果table[i]不为null,说明这个位置有链表或者红黑树了。
- 那么判断key是否存在,如果存在直接覆盖value。
- 如果key不存在的话,判断这个节点是否为红黑树节点,如果是红黑树,则直接在树中插入键值对。否则判断链表长度是否大于8,大于8的话会调用树化treeifyBin ()方法,在treeifyBin ()方法中,只有当数组长度大于或者等于64的情况下,才会执行转换红黑树操作。否则,就是只是执行resize()方法对数组扩容。如果链表长度小于8,直接进行链表的插入操作。
- 插入成功后,判断实际存在的键值对数量是否超多了最大容量(也就是数组长度*负载因子),如果超过,还需要进行扩容resize()。
5.3 resize()和rehash()
resize方法是在进行初始化或者hashmap中的键值对大于最大容量(也就是数组长度*负载因子)时,就调用resize方法进行扩容。resize方法每次对table数组进行扩展的时候,都是扩展2倍。resize方法调用后会伴随着一次rehash,也就是说会遍历所有的元素进行重新创建链表,扩展后节点要么在原位置,要么移动到原偏移量两倍的位置。因为进行rehash非常耗时,所以要尽量避免。如果提前预估存储的容量大小,可以设置大点的容量,这样可以少扩容几次,或者设计合理的加载因子,尽可能避免频繁的扩容。
5.4 HashMap哈希算法
- JDK 7实现:4次位运算,5次异或运算(9次扰动)。
- JDK 8实现:1次位运算和1次异或运算(2次扰动)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
- 为什么右移16位:如果哈希值的高位变化很大,低位变化很小,这样就很容易造成哈希冲突了。所以将哈希值右移16位再进行与运算是把哈希值的高低位都利用起来,从而解决这个问题。
- 1次位运算和1次异或运算(2次扰动):加大哈希值低位的随机性,使得分布更均匀,从而提高对应数组存储下标位置的随机性&均匀性,最终减少Hash冲突。
5.5 HashMap哈希冲突
- 使用2次扰动函数(hash函数)来降低哈希冲突的概率,使得数据分布更平均。
- 使用链地址法来链接拥有相同table数组索引的数据。
- 引入红黑树进一步降低遍历的时间复杂度,使得遍历更快。
5.6 HashMap的长度为什么是2的幂次方
这其实是一个数学计算上的优化,如果HashMap的长度是2的n次方,那么与key的hash值对长度取余的操作等价于key的hash值与长度减一的与操作,可以加快计算速度。
如果长度为2的幂次方,则长度减一转化为二进制必定是11111……的形式。如果长度不是2的次幂,比如为 15,则长度减一为14,对应的二进制为1110,在与key的hash值进行与操作时,最后一位都为 0,而 0001、0011、0101、1001、1011、0111和1101这几个位置永远都不能存放元素了,空间浪费相当大,同时会增加了碰撞的几率,使元素无法均匀分布。
5.7 HashMap、HashTable和ConcurrentHashMap
底层数据结构:
- JDK 7中,HashMap采用数组+链表。JDK 8中,HashMap采用数组+链表/红黑树。
- JDK 7中,ConcurrentHashMap采用分段的Segment数组+HashEntry链表实现。JDK 8中,ConcurrentHashMap采用数组+链表/红黑树。
- HashTable采用数组+链表。
其他:
- HashMap是非线程安全的。HashTable和ConcurrentHashMap是线程安全
- HashMap的键值对允许有null,但是HashTable和ConcurrentHashMap都不允许。
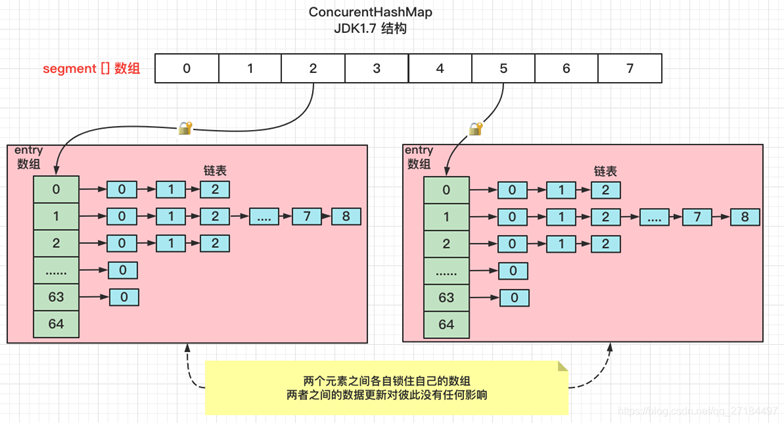
5.8 ConcurrentHashMap in JDK 7
ConcurrentHashMap里包含一个Segment数组,**一个Segment对象和HashMap类似,也是一种数组和链表结构。**一个Segment对象管理一个HashEntry 数组,每个HashEntry是一个链表节点,当对 HashEntry的数据进行修改时,必须首先获得对应的Segment的锁。
本质上,Segment继承了ReentrantLock,每个Segment管理一个HashEntry数组。所以,如果想对HashEntry数组的数据进行修改时,必须首先获得对应的Segment锁。
5.9 ConcurrentHashMap in JDK 8
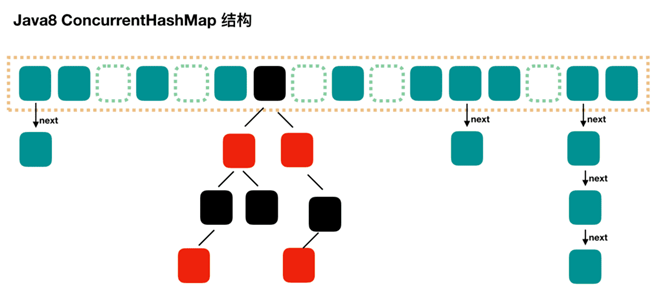
JDK 8中:放弃了Segment臃肿的设计,数据结构采用Node数组+链表+红黑树(在这一点上,结构又类似于HashMap了)。在并发控制上,ConcurrentHashMap采用CAS + Synchronized,synchronized只锁定当前链表或红黑二叉树的首节点,只要hash不冲突,就不会产生并发。
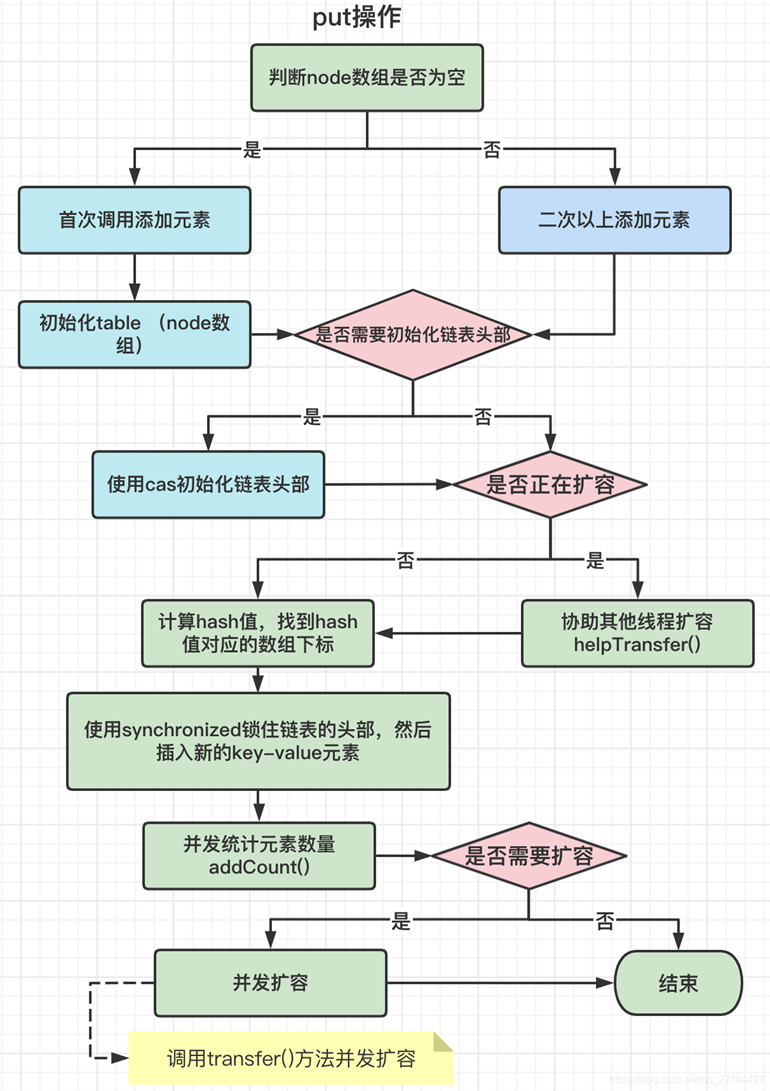
5.10 ConcurrentHashMap的put()
- 插入时首先需要判断是否是首次添加元素,也就是判断node数组是否为空,如果为空的话需要初始化node数组,其大小默认为16。初始化node数组时,是通过自旋和CAS操作完成的。根据sizeCtl是否为小于0,则让出CPU。否则对node进行初始化,默认数组大小为16。
- 如果不是首次添加元素,则判断链表头部是否为空,如果为空则使用CAS初始化链表头部,然后放入元素后直接break跳出方法。如果链表头部不为空,则判断其hash是否为-1,如果为-1表明正在扩容,此时会调用helpTransfer()协助扩容。
- 如果不需要扩容,那么直接加锁进行插入数据。如果链表长度大于阈值8并且数组长度大于64则需要调用treeifyBin将链表转化为为红黑树。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









