








文章目录
1 JDBC操作数据库的步骤
- 注册数据库驱动:DriverManager.registerDriver(new com.mysql.jdbc.Driver());
- 建立数据库连接:DriverManager.getConnection(“jdbc:mysql://localhost:3306/xxx”, “root”, “root”);
- 创建一个Statement:statement = connection.createStatement();
- 执行SQL语句:resultSet = statement.executeQuery(“SELECT * FROM users”);
- 处理结果集:while (resultSet.next())
- 关闭数据库连接:connection.close();
2 Statement类
2.1 Statement类
Statement提供了三个方法来执行SQL语句:
- executeQuery()
- executeUpdate()
- execute():几乎可以执行任何SQL语句,但它执行SQL语句时比较麻烦,通常没有必要使用execute()来执行SQL语句,使用executeQuery()或executeUpdate()更简单。使用execute()执行SQL语句的返回值只是boolean值,表明执行该SQL语句是否返回了ResultSet对象。Statement提供了如下两个方法来获取执行结果:
- getResultSet():获取该Statement执行查询语句所返回的ResultSet对象。
- getUpdateCount():获取该Statement()执行DML语句所影响的记录行数。
2.2 PreparedStatement类
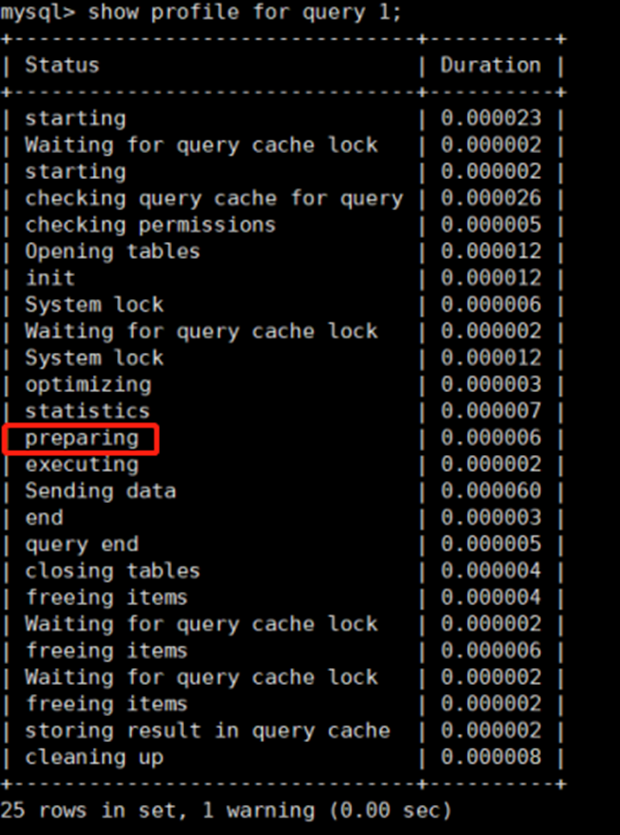
2.2.1 执行一条SQL的过程
一个SQL语句执行过程中,将经历这么几个步骤:
- 客户端发送SQL到MySQL服务端,服务端会对用户名和密码进行校验。
- MySQL服务端首先判断是否命中缓存,再对SQL语句进行权限校验(checking query cache, checking permissions)。
- 最关键的一步,MySQL服务端对SQL语句进行词法解析并创建语法树、进行优化、生成执行计划、并选择最佳执行计划(optimizing、statistics)。
- 然后预处理SQL语句,即缓存执行计划(preparing)。
- execute执行计划(executing)。
其中,第3步是非常耗时的。为了提高性能,数据库会缓存执行语句以及其执行计划,称之为SQL Statement Cache, SSC。在SSC中,key为SQL语句,value为对应的执行计划。当相同的SQL语句被发送过来时,数据库会使用缓存中的执行计划以节省执行时间。SSC相关参数:
STMT_CACHE:是否开启SSC
STMT_CACHE_HITS :在SQL语句完全缓冲之前执行的SQL语句的次数
STMT_CACHE_SIZE 512000:SSC的大小
STMT_CACHE_NOLIMIT 0:是否可以增加SSC的大小
STMT_CACHE_NUMPOOL 12:SSC的个数
因此,PreparedStatement类的本质就是缓存执行计划,跳过SQL语句的编译过程并重用执行计划,以达到减轻数据库的负担、提高访问数据库的速度的目的。
2.2.2 验证PreparedStatement
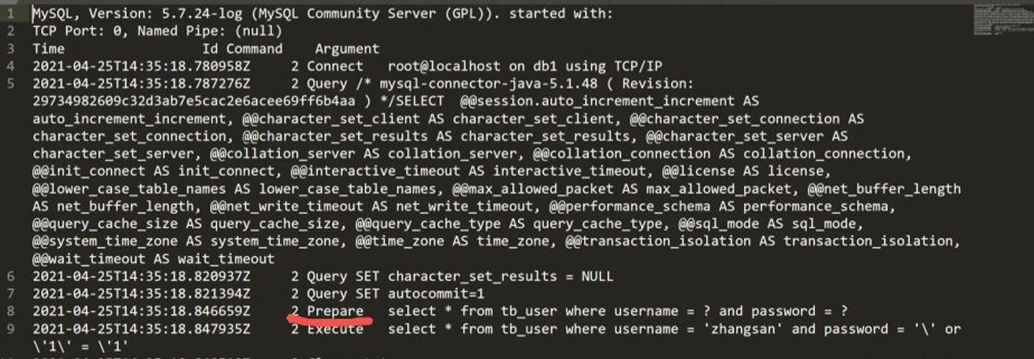
以一段代码为例:
String sql = "SELECT * FROM user WHERE username = ? AND password = ?";
PreparedStatement stmt = conn.prepareStatement(sql);
第一次执行时,数据库会产生这样的日志:
而在第二次执行时:可以明显看出跳过prepare步骤,直接执行了execute命令:
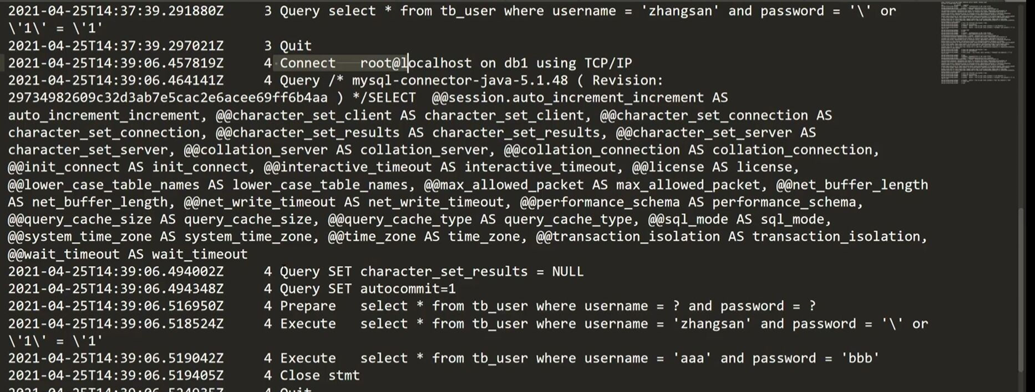
那为什么它这样处理就能预防SQL注入提高安全性呢?其实是因为SQL语句在程序运行前已经进行了预编译,在程序运行时第一次操作数据库之前,SQL语句已经被数据库解析、优化和编译,对应的执行计划也会缓存下来并允许数据库以参数化的形式进行查询,当运行时动态地把参数传给PreprareStatement时,即使参数里有敏感字符如or '1=1’也会被数据库作为一个字段的属性值来处理而不会作为一个SQL指令。如此,就起到了SQL注入的作用了!
2.3 CallableStatement类
2.3.1 存储过程
在大多数实际场景中,操作并非都是使用一条SQL语句就可以完成的了。一个操作可能会涉及到连续执行三四条SQL语句以上,例如:
- 为了处理订单,需要核对以保证库存中有相应的物品。
- 如果库存有物品,这些物品需要预定以便不将它们再卖给别的人,并且要减少可用的物品数量以反映正确的库存量。
- 库存中没有的物品需要订购,这需要与供应商进行某种交互。
- 关于哪些物品入库(并且可以立即发货)和哪些物品退订,需要通知相应的客户。
对于这种场景,就可以使用存储过程进行优化了。存储过程的英文是Stored Procedure。它的思想很简单,就是一组经过预先编译的SQL语句的封装。存储过程预先存储在MySQL服务器上,需要执行的时候,客户端只需要向服务器端发出调用存储过程的命令,服务器端就可以把预先存储好的这一系列SQL语句全部执行。
- 提高了SQL语句的重用性
- 减少操作过程中的失误,提高效率
- 减少网络传输量(客户端不需要把所有的SQL语句通过网络发给服务器)
- 减少了SQL语句暴露在网上的风险,也提高了数据查询的安全性
值得一提的是,存储过程是不具有事务性的。要保证一个存储过程中的全部SQL语句具有事务性,可以在存储过程中开启事务。
2.3.2 使用CallableStatement
首先,在MySQL中定义如下存储过程:
mysql> delimiter //
mysql> create procedure getNameById(IN u_id int, OUT u_name varchar(255))
-> begin
-> select name into u_name
-> from user
-> where id = u_id;
-> end //
Query OK, 0 rows affected (0.01 sec)
然后,在Java程序中使用存储过程:
@Test
public void testInOutParam() throws Exception {
Connection conn = null;
CallableStatement cs = null;
try {
// 1. 获取数据库连接
conn = JDBCUtils.getConnection();
// 2. 调用存储过程的SQL语句
String sql = "call getNameById(?, ?)";
// 3. 创建CallableStatement对象
cs = conn.prepareCall(sql);
// 4. 填充参数
cs.setInt(1, 1);
cs.registerOutParameter(2, Types.VARCHAR);
// 5. 执行SQL语句
cs.executeUpdate();
// 6. 获取传出参数
String name = cs.getString(2);
System.out.println("传出参数name = " + name);
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(conn, cs, null);
}
}
2.3.3 PreparedStatement类和CallableStatement类
- PreparedStatement是预编译的SQL语句,效率高于Statement。
- PreparedStatement支持?操作符,相对于Statement更加灵活。
- PreparedStatement可以防止SQL注入,安全性高于Statement。
- CallableStatement适用于执行存储过程,以提高SQL语句的重用性,同样也可以提高多条SQL语句的执行效率。
3 ResultSet
JDBC是通过ResultSet来管理结果集,操作ResultSet可以通过移动其指针来指向不同的行记录,然后取出当前记录即可。并且ResultSet可以完成更新记录,还提供了ResultSetMetaData来获得对象相关信息。
4 数据库连接池
4.1 连接池技术
连接池用于创建和管理数据库连接的缓冲技术,缓冲池中的连接可以被任何需要他们的线程使用。当一个线程需要使用JDBC对一个数据库操作时,将从池中请求一个连接。当这个链接使用完毕后,将返回连接池中,等待为其他的线程服务。
- 减少数据库连接的创建次数和时间。连接池中的连接是已准备好的,可以重复使用的,获取后可以直接访问数据库,因此减少了连接创建的次数和时间。
- 简化编程模式。当使用连接池时,每一个单独的线程能够像创建自己的JDBC连接一样操作,允许用户直接使用JDBC编程技术。
- 控制资源的使用。如果不使用连接池,每次访问数据库都需要创建一个连接,这样系统的稳定性受系统的连接需求影响很大,很容易产生资源浪费和高负载异常。
4.2 开源技术
- DBCP:Apache提供的数据库连接池,Tomcat自带,速度比C3P0快。
- C3P0:速度相对慢,稳定性还可以。
- Proxool: 是sourceforge下的一个开源项目数据库连接池,有监控连接池状态的功能,稳定性较c3p0差一点。
- BoneCP :是一个开源组织提供的数据库连接池,速度快。
- Druid 是阿里提供的数据库连接池,据说是集DBCP 、C3P0 、Proxool 优点于一身的数据库连接池,使用率最高。
4.3 Druid连接池
| 配置 | 缺省 | 说明 |
|---|---|---|
| name | 如果没有配置,默认格式是:”DataSource-” + System.identityHashCode(this) | |
| url | 连接数据库的url | |
| username | 连接数据库的用户名 | |
| password | 连接数据库的密码 | |
| driverClassName | 这一项可配可不配,如果不配置Druid会根据url自动识别dbType,然后选择相应的driverClassName | |
| initialSize | 0 | 初始化时建立物理连接的个数,初始化发生在显式调用init方法,或者第一次getConnection时 |
| maxActive | 8 | 最大连接池数量 |
| maxIdle | 8 | 已经不再使用,配置了也没效果 |
| minIdle | ||
| maxWait | 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 | |
| poolPreparedStatements | false | 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。 |
| maxOpenPreparedStatements | -1 | 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100 |
| validationQuery | 用来检测连接是否有效的sql,要求是一个查询语句。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会其作用。 | |
| testOnBorrow | true | 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testOnReturn | false | 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能 |
| testWhileIdle | false | 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 |
| timeBetweenEvictionRunsMillis | 1)Destroy线程会检测连接的间隔时间 2)testWhileIdle的判断依据,详细看testWhileIdle属性的说明 | |
| numTestsPerEvictionRun | ||
| minEvictableIdleTimeMillis | ||
| connectionInitSqls | 物理连接初始化的时候执行的sql | |
| exceptionSorter | 根据dbType自动识别 当数据库抛出一些不可恢复的异常时,抛弃连接 | |
| filters | 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat日志用的filter:log4j防御sql注入的filter:wall | |
| proxyFilters | 类型是List,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系 |















 127
127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









