







说明:
1. 这个谷歌在udacity上开设的一门deeplearning免费课程,可以通过这个链接访问,笔记中所有的文字和图片都来自这门课,在此感谢这些大牛们的免费分享
2. 这是我自己的学习笔记,错误和遗漏之处肯定很多,还有一些细节没有解释。另外,有些地方直接把英文复制过来是因为理解很简单或者我自己理解不了。
3. 笔记目录:
- L1 Mechine Learning to DeepLearning
- L2 DEEP NEURAL NETWORK
- L3 CONVOLUTIONAL NEURAL NETWORKS
- L4 TEXT AND SEQUENCE MODEL
INTRODUCE
Deeplearning shines wherever there isi lots of data and complex problem to solve.
One of the nice things of deeplearning is that it’s really a family of techniques that adapts to all sorts of data and all sorts of problems, all using a common infrastructure and a common language to describe things.
What changed ?
Lots of data
and cheap and fast GPs
BASIC
SOFTMAX函数
one-hot encoding
cross entropy
梯度下降和随机梯度下降
APPLICATION
验证集越大,结果越精确
不要迷信训练速度,这和你的模型好坏并没有直接的关系
- 超参数设置
INITIAL LEARNING RATE
LEARNING RATE DECAY
MOMENTON
BATCH SIZE
WEIGHT INITIALIZATION
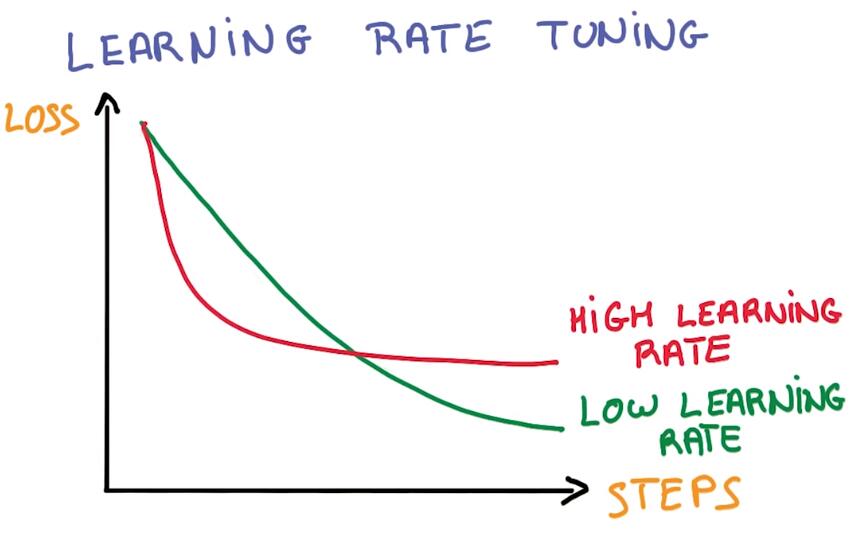
It’s that when things don’t work, always try to lower your learning rate first
当训练出现问题时,首先要进行的调整的降低学习率
AdaGrad that makes thing a little bit easier.
介绍一个对SGD进行优化的算法AdaGrad,AdaGrad使用动量来防止过拟合,且学习率自动衰减,可降低训练过程对超参数的敏感度,但准确率比使用动量的SGD要低一些。















 2117
2117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









