







说明:
1. 这个谷歌在udacity上开设的一门deeplearning免费课程,可以通过这个链接访问,笔记中所有的文字和图片都来自这门课,在此感谢这些大牛们的免费分享
2. 这是我自己的学习笔记,错误和遗漏之处肯定很多,还有一些细节没有解释。另外,有些地方直接把英文复制过来是因为理解很简单或者我自己理解不了。
3. 笔记目录:
- L1 Mechine Learning to DeepLearning
- L2 DEEP NEURAL NETWORK
- L3 CONVOLUTIONAL NEURAL NETWORKS
- L4 TEXT AND SEQUENCE MODEL
Linear operation
Numerically linear operations are very stable. Small changes in the input can never yield big changes in the output. The derivates are very nice too.
ReLU函数
y = max { 0, x }
ReLU have nice derivatives as well.
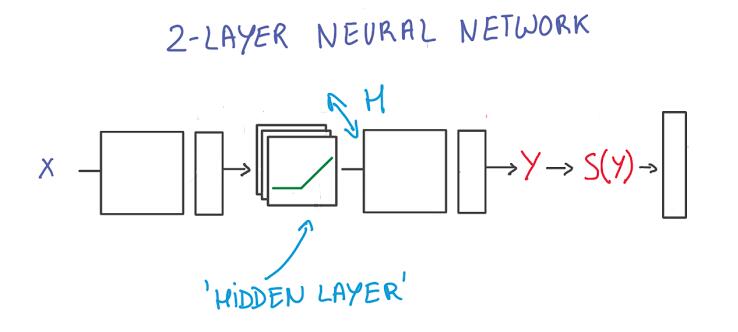
2 layers network
Chain Rule
[ g(f(x)) ]’ = g’(f(x)) * f’(x)
Back Propagation
BP Rules makes computing derivatives of complex function very efficient as long as the function is made up of simple blocks with simple derivatives.
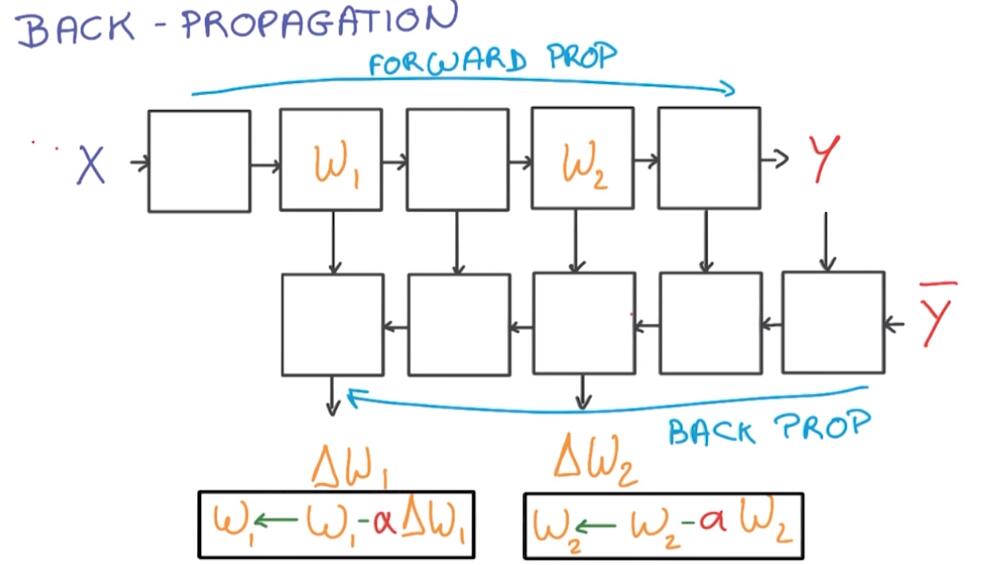
This diagran, it’s essentially the chain rule. In particular, each block of the back prop often takes about twice the memory that’s needed for forward prop and twice the compute.
相比于前向传播,反向求导的每一步都将花费两倍的运算和存储空间。
TRAIN A DEEP NN
Now you have a small nerual network. It’s not particulary deep, just two layers. You can make it bigger, more complex by increasing the size of that hidden layer in the middle. But it turns out that increasing this H is not particulary efficient in general.
仅仅增加隐层中单元的个数并非有效的办法。
You need to make it very , very big and then it gets really hard to train. This is where the central idea of deep learning comes into play.
Instead, you can also add more layers and make your model deeper. There are lots of good reasons to do that .
增加层数让网络更深:这么做有以下的原因:
One is parameter efficiency, you can typically get much more performance with fewer parameters by going deeper rather than wider.
Another one is that a lot of natural phenomena that you maight be insterested in, tends to have a hierarchical structure which deep models naturally capture.
比如:对于图片识别任务,层次结构取得了很好的表现,底层的能够识别线,边,高层的可以识别几何形状,在深的层可以识别人脸,事物等。
This is bery powerful because the model structure matches the kind of abstractions that you maight expect to see in your data.
REGULARIZATION
why need regularization?
The network that’s just the right size for your data is very hard to optimize. So in parctice, we always try networks that are too big for our data and then try our best to prevebt them form overfitting.
网络的设计一般会比数据小,符合数据大小的网络很难优化。在实践中的经验是:给一个网络更多的数据,然后我们再防止过拟合。(解释太生硬了,参考讲课的裤子的例子可以帮助理解)
The method for regularization
- early stop 早停
The first way we prevent overfitting is by looking at the performance under validation set, and stopping to train as soon as we stop improving.
早停是验证模型在验证集上的表现
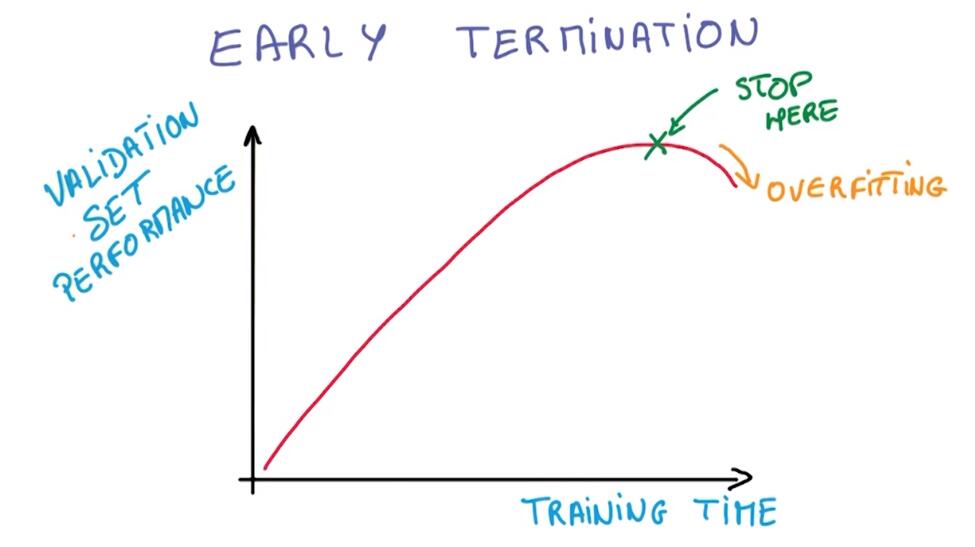
It’s called early termination, and it’s still the best way to prevent your network from over-optimizing on the training set.
- 正则化(L2正则化)
Another way is to apply regularization.
Regularizing means appling artificial constraints on your network that implicitly reduce the number of free parameters. While not making it more difficult to optimize.
正则化可以较少自由变量的参数数量
L2 regularization: The idea is to add another term to the loos, which penalizes large weights.
It’s typically achieved by adding the L2 norm of your weights to the loss multiplied by a small constant.
And yes, yet another hyper-parameter to tune
L2正则化的核心思想就是在LOSS函数中增加额外想以减少大权重的影响。
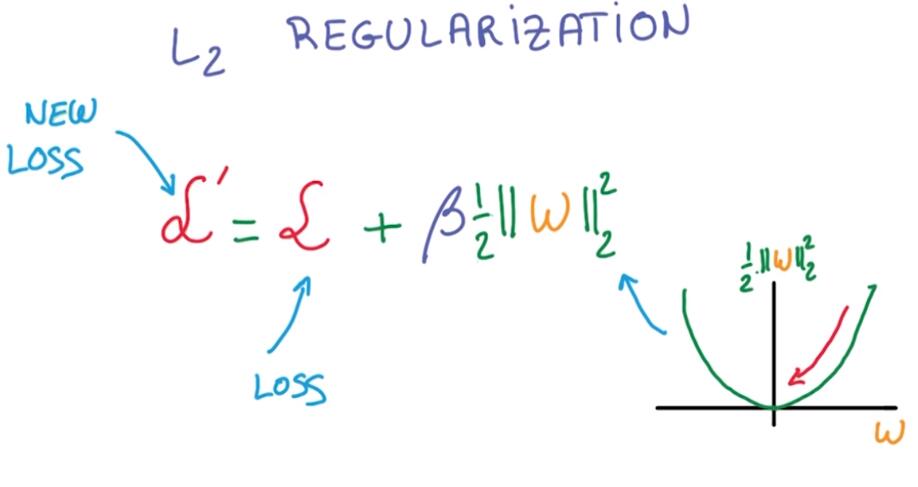
The nice thing about L2 regularization is that it’s very simple. Because you just add it to your loss, the structure of your network doesn’t have to change, You can even compute it’s derivative by hand.
L2最好的地方在于它很简单,且并没有改变网络结构
Remember that L2 norm stands for the sum of the squares of the individual elements in a vector.
- DropOut
Dropout的过程就不详细介绍了
Your network can never rely on any given activation to be present because they might be squashed at any given moment. So it is forced to learn a redundant representation for everything to make sure that at least some of the information remains.
Forcing your network to learn redundant representations might sound very inefficient. But in practice, it makes things more robust and prevents over fitting. It also makes your network act as if taking the consensus over an ensemble of networks. Which is always a good way to improve performance.
dropout 会让你的网络学习更过冗余的表达,但是在实际操作红,这会让你的网络更加具有鲁棒性而且可以防止过拟合,同时让你的网络变得像是一群网络的集成。
If dropout doesn’t work for you, you should probably be using a bigger network.
when you evaluate the network that’s been trained with dropout, you obviously no longer want this randomness. You want something deterministic.
Instead, you’re going to want to take the consensus over these redundant models. You get the consensus opinion by averaging the activations.
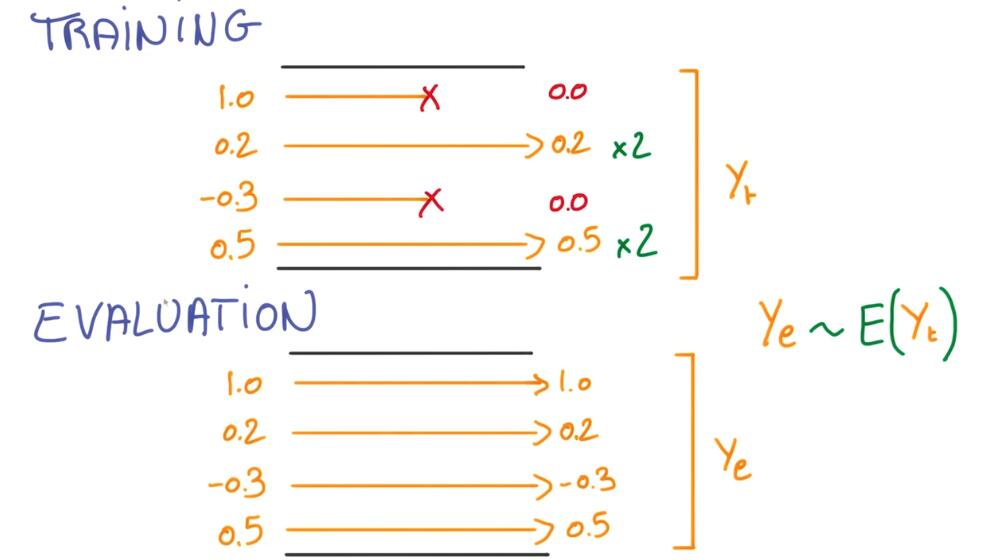
Here is a trick to make sure this a expectation holds: During training, not only do you use zero out so the activations that you dropout, but you also scale the remaining activations by a factor of 2.
This way, when it comes time to average them during evaluation, you just remove these dropouts and scaling operations from your neural net. And the result is an average of these activations that is properly scaled.















 926
926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









