







说明:
1. 这个谷歌在udacity上开设的一门deeplearning免费课程,可以通过这个链接访问,笔记中所有的文字和图片都来自这门课,在此感谢这些大牛们的免费分享
2. 这是我自己的学习笔记,错误和遗漏之处肯定很多,还有一些细节没有解释。另外,有些地方直接把英文复制过来是因为理解很简单或者我自己理解不了。
3. 笔记目录:
- L1 Mechine Learning to DeepLearning
- L2 DEEP NEURAL NETWORK
- L3 CONVOLUTIONAL NEURAL NETWORKS
- L4 TEXT AND SEQUENCE MODEL
WORD2VEC
In fact, the ones that you rarely see,, tends to be the most important one.
在文本分析中,一些不常用的词(如医学专用名词)在文本中出现的概率很低,但是却与文本分析却很重要。
深度学习处理文本中有两个问题
Rare events 比如那些罕见的词,因为深度学习的训练需要大量的样本
Another problem is that we often use different words to mean almost the same thing. 对于同一个事物有不同的表达方法
So, First, We’d like to see those important words often enough to be able to learn the meanings automatically.
And, we’d also like to learn how words related to each other so that we can share parameters between then.
But that would mean collecting a lot of label data. In fact, it would require way to much label data for any task.
所以,一方面我们希望这些“关键词”能够频繁出现以便自动学习。另一方面,希望知道单词与单词之间的关系,但这需要大量的标签数据。
So to solve that problem, we’re going to turn to unsupervised learning.
这两个问题都会用到非监督学习。
The hope is that a model that’s good at predicting a word’s context will have treat “cat” and “kitty” similarly, and will trend to bring them closer together.
我们的目的是构建一个能够预测上下文的模型,能够将“cat”和“kitty”的距离拉近。
The beauty of this approach is that you don’t have to worry about what the words actually mean, giving further meaning directly by the company they keep.
这种方法的好处在于不必在乎单词的真实意思,而是直接给出进一步的意义。
There are many way to use this idea that similar words occur in similar contexts.
We’re going to use it to map words to small vectors called embeddings which are going to be close to each other.
我们使用词嵌入模型来计算与其他词的距离。
Embedding solves of the sparsity problem.
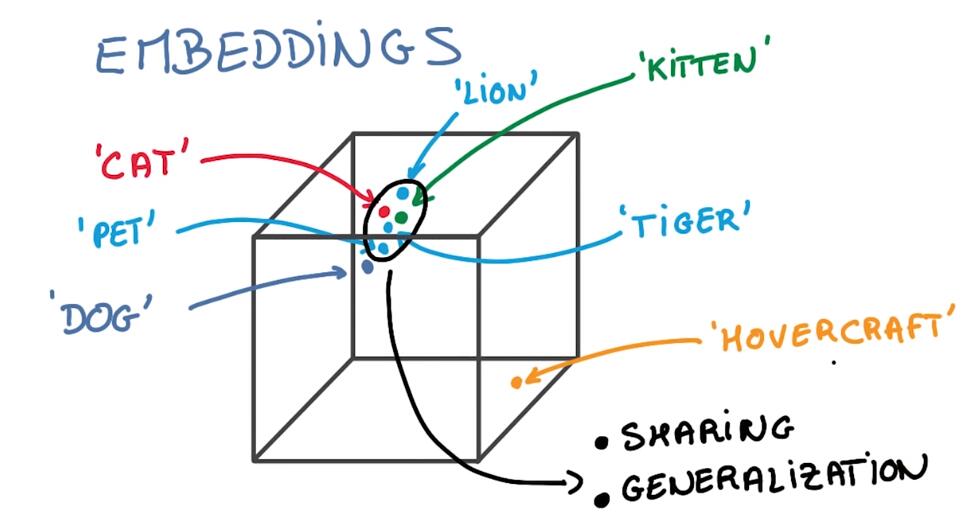
Once you have embedded your word into this small vector, now you have a word representation where all the catlike things like cats, kitties, kittens, pets, lions, are all represented by vectors that are very similar.
一旦词变为向量,那么这些词就有了表示特征。
Method
Word2Vec is a surprisingly simple model that works very well.
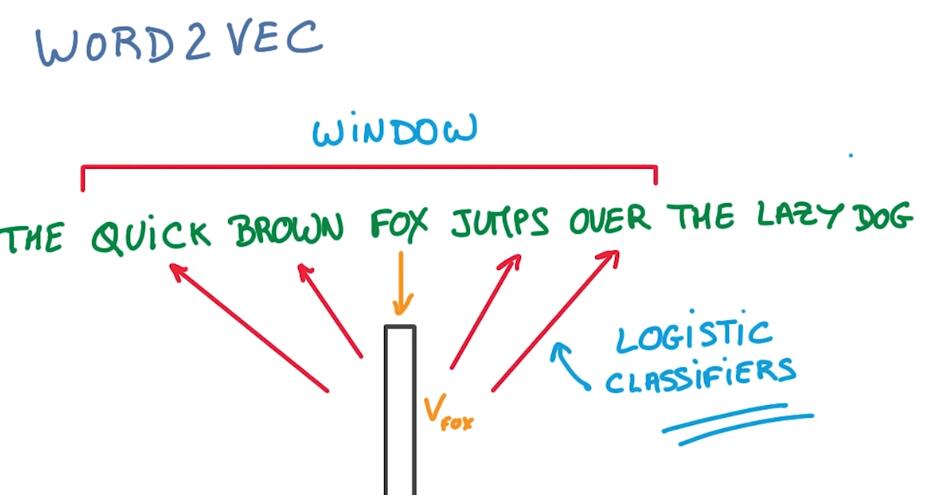
Imagine you had a corpus of text with a sentence say, the quick brown fox jumps over the lazy dog. For each word in this sentence, we’re going to map it to an embedding.
使用word2vec将一句话中的每一个词映射到一个向量中。
Initially a random one. And then we’re going to use that embedding to try and predict the context of the word.
In this model, the context is simply the words that are nearby. Pick a random word in a window around the original word, and that’s your target.
用训练好的词嵌入模型来预测词的上下文,我们随机从词附近挑选一个作为预测目标。
Then train your model exactly as if it were a supervised problem. The model you’re going to use to predict this nearby word is a simple logistic regression. Nothing deep about it, just a simple linear model.
然后训练模型,预测的方法是简单的逻辑回归。
得到每个词的向量表示之后,我们可以对这些词进行聚类。
One way to see it, is by doing a nearest neighbor lookup of the words that are closest
to any given word.
Another way is to try to reduce the dimensionality of the embedding space down to two dimensions, and to plug the two dimensional representation.
If you do that the native way, for example using PCA, you basically get a mush. You lose too much information in the process.
使用这个模型,我们可以找出离指定词距离最近的词,进一步可以做聚类。
另外,我们可以进行来进行降维,一般使用的PCA会在降维过程中损失很多信息。
What you need is a way of projecting that preserves the neighborhood structure of your data. Things that are close in the embedding space should remain close to the ends, things that are far should be far away from each other. One very effective technique that does exactly that is called t-SNE.
降维之后的结构不能变,即词与词之间的距离关系不能变,一个有效的方法-“t-SNE”
WORD2VEC的两个技术细节
First, because of the way embeddings are trained, it’s often better to measure the closeness using a cosine distance instead of L2, for example.
That’s because the length of the embedding vector is not relevant to the classification.
首先,使用cosine距离更好,因为词嵌入向量的长度与分类无关
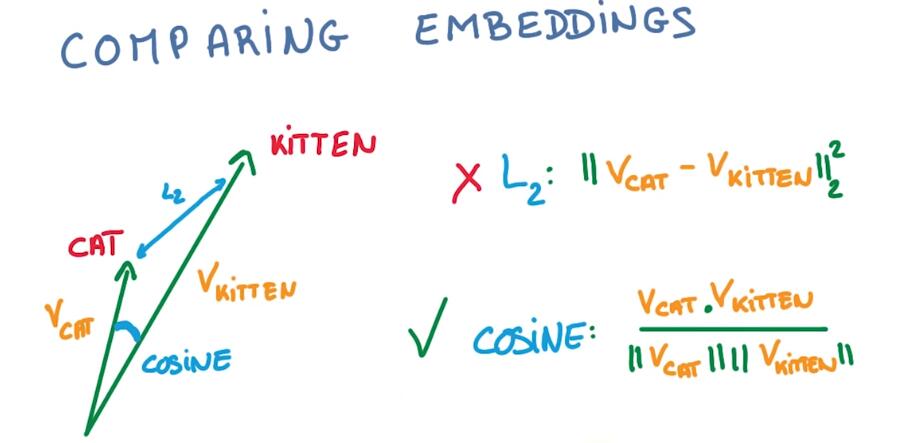
In fact, it’s often better to normalize all embedding vectors to simply have unit norm.
Second, we have the issue of trying to predict words, and there are lots of them.
So in Word 2 Vec we have this set up, we have a word that we’re going to embed into a small vector, then feed that into a simple linear model with weights and biases and that outputs a softmax probability. This is then compared to the target which is another word in the context of the input word.
The problem of course is that there might be many, many words in our vocabulary. And computing the softmax function of all those words can be very inefficient. But you can use a trick. Instead of treating the softmax as if the label had probability of 1, and every other word had probability of 0, you can sample the words that are not the targets, pick only a handful of them and act as if the other words were not there. This idea of sampling the negative targets for each example is often called sampled softmax. And it makes things faster at no cost in performance.
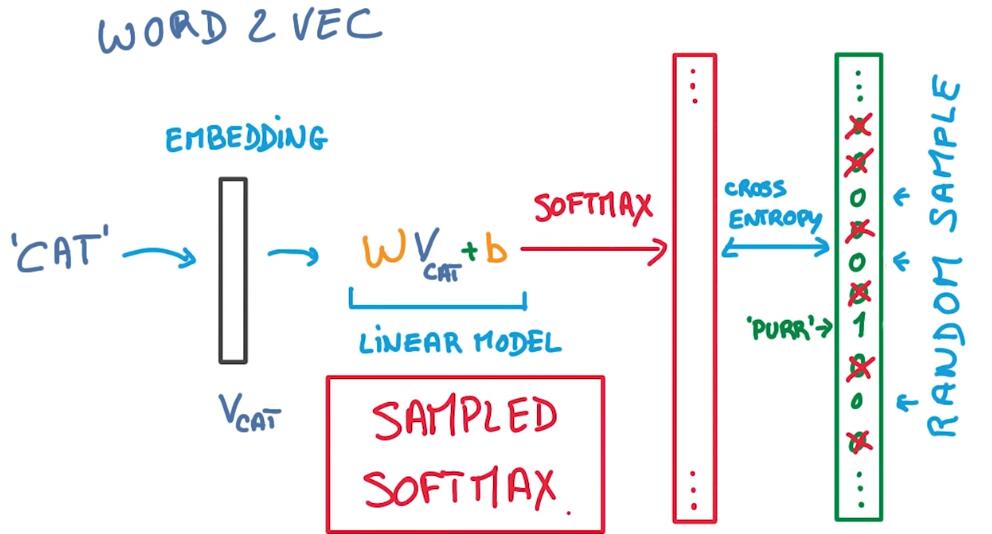
word2vec的流程,对一个计算词向量的单词,进行线性运算,然后产生一个softmax概率,然后与上下文中的某个词(target)相比较,问题在于词库中有很多词,计算所有的softmax效率很低,但是有一个技巧,不用one-hot做每一个单词的编码,对非目标单词进行采样,只挑选其中的一部分,这种方法叫做sample-softmax。
WORD ANALOGIES
- SEMANTIC ANALOGY
- SYNTACTIC ANALOGY
这个暂时还是不了解,就不解释了
RNN - RECURRENT NETWORKs
INTORDUCE
RNN同样是用共享参数提出特征,与卷积网络不同的是,卷积用在空间,而RNN用在时间上。
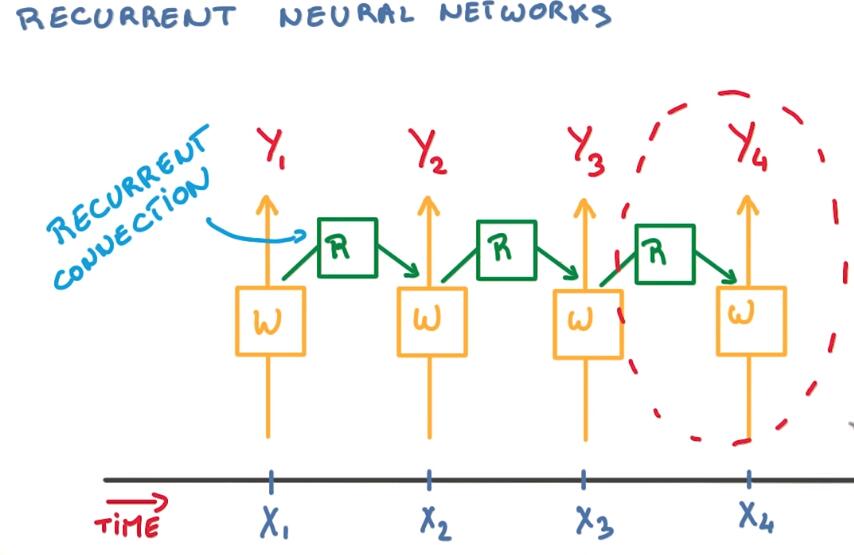
Since this is a sequence, you also want to take into account the past. Everything that happened before that point.
One natural thing to do here is to use the state of the previous classifier as a summary of what happened before, recursively. Now, you would need a very deep neural network to remember far in the past. Imagine that this sequence could have hundreds, thousands of steps. It would basically mean to have a deep network with hundreds or thousands of layers.
But instead, we’re going to use tying again and have a single model responsible for summarizing the past and providing that information to your classifier.
What you end up with is a network with a relatively simple repeating pattern with part of your classifier connecting to the input at each time step and another part called the recurrent connection connecting you to the past at each step.
BPTT
For RNN, we need to backpropagate the derivative through time, all the way to the beginning of the sequence. Or in practice, more often, for as many steps as we can afford. All these derivatives are going to be applied to the same parameters. That’s a lot of correlated updates all at once, for the same weights. This is bad for stochastic gradient descent.
SGD偏好于无关联的参数更新,对于相关联的参数更新可能会引起梯度爆炸或者梯度消失。
Vanishing Exploding Gradients
梯度爆炸
One using a very simple hack, and the other one with a very elegant but slightly complicated change to the model. The simple hack is called gradient clipping.
In order to prevent the gradients from growing inbounded, you can compute their norm and shrink their step, when the norm grows too big.
It’s hacky, but it’s cheap and effective.
对于梯度爆炸,使用的方法很简单,就是在模增至过大时,缩小学习步长。
梯度消失
对于梯度消失,没有好的方法,只能从模型上改进,因此有了LSTM
LSTM
LSTM is a recurrent neural network consists of a repetition of simple little units like this, which take as an input the past, a new inputs, and produces a new prediction and connects to the future.
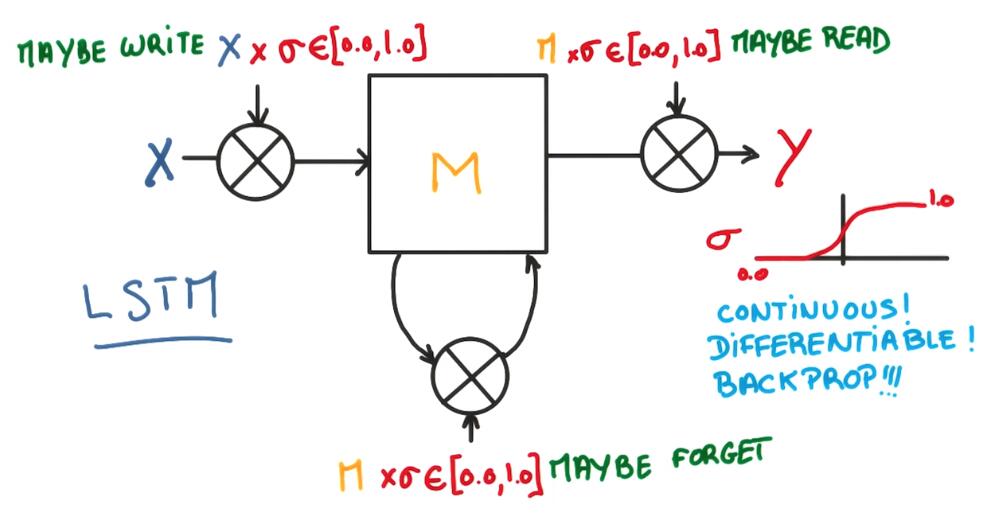
The gating values for each gate get controlled by a tiny logistic regression on the input parameters. Each of them has its own set of shared parameters.
每一个门的阈值由一组基于输入参数的逻辑回归控制,每一种门共享他们的参数。
And these functions are well-behaved, continues, and differentiable all the way, which means we can optimize those parameters very easily.
每一个函数连续可导,因此优化很简单。
So why do LSTMs work?
Without going into too many details, all these little gates help the model keep its memory longer when it needs to, and ignore things when it should.
As a result, the optimization is much easier, and the gradient vanishing, vanishes.
regularization
- You can always use L2, that works.
- Dropout works well on your LSTMs as well, as long as you use it on the inputs or on the outputs, not on the recurrent connections.
Beam Search
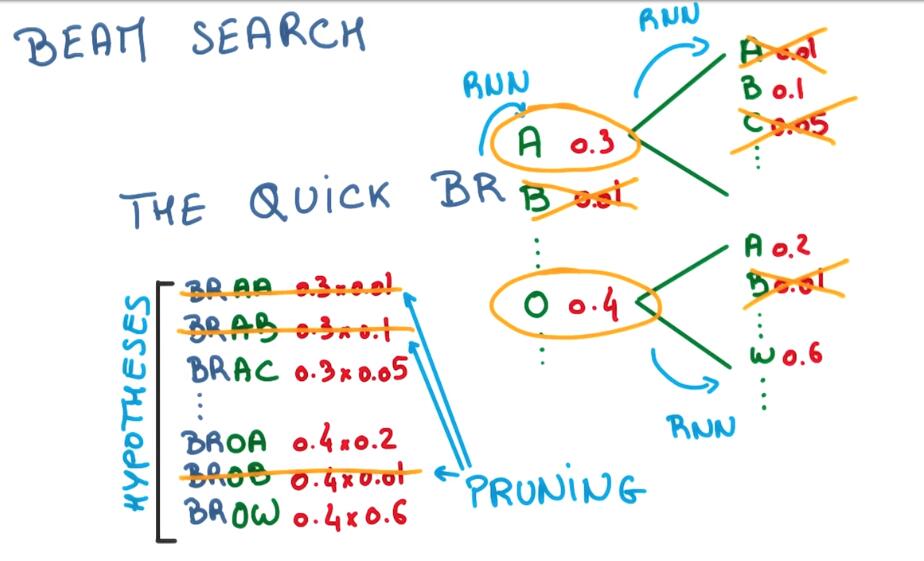
RNN的应用
- 生成序列:例如根据已有文本生成文本
- 机器翻译
- 语音识别
- 图像描述 一个数据库http://mscoco.org















 2341
2341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









