









DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
现有的针对CTR预估问题的解决方案,普遍对不同阶的交叉特征有着偏好,或者需要专家级特征工程。文章提出了DeepFM模型,能够实现端到端训练,不需要额外的特征工程,并且可以自动地提取交叉特征。
CTR预估中,一个很重要的内容就是去挖掘点击背后隐藏的特征交互(interaction),这些交互有时候可以从现象去挖掘。例如基于用户经常在饭点点击订餐相关的app,说明“app类别 x 时间”这个二阶交叉特征能用于CTR预估,再比如男孩子很喜欢打射击类和RPG游戏,说明“app类别 x 性别 x 年龄”这个三阶交叉特征可用。一般来说这些交叉特征可以让专家去挖掘,但是某些交叉特征是人意想不到的,只能从数据中挖掘出来,例如在超市购买啤酒的人多会购买尿布的那个故事,而且可能存在更高阶的有用的交叉特征,人工暴力枚举是不现实的,我们需要高效地构造交叉特征。
现有的一些模型都不能很好地解决这个问题。基于FTRL的LR,线性模型无法实现交叉。FM,理论上可以实现任意阶交叉,但出于复杂度考虑往往只做到二阶交叉。CNN,只适合相邻特征之间关联程度大的数据。RNN,只适合具有时间依赖性的数据。FNN和PNN,专注高阶交叉,缺乏低阶交叉。Wide&Deep,仍然部分依赖与人工特征工程。
DeepFM
假设训练数据集 (X,y) ( X , y ) 大小是 n n ,有 m m 个field,这其中可能包含类别型 categorical field 和连续型 continuous field,其中categorical field 一般是onehot编码过的特征,continuous field就是特征本身或者先量化再onehot。每一个样本 是很稀疏的,表示为 x=[xfield1,xfield2,⋯,xfieldm] x = [ x f i e l d 1 , x f i e l d 2 , ⋯ , x f i e l d m ] ,每一个 xfieldi=[xi1,xi2,⋯] x f i e l d i = [ x i 1 , x i 2 , ⋯ ] 都是一个稀疏向量,因为是onehot过的,所以可能只有1个特征取1,其他特征都是0,下面就直接称这个为1的特征位 xi x i 。
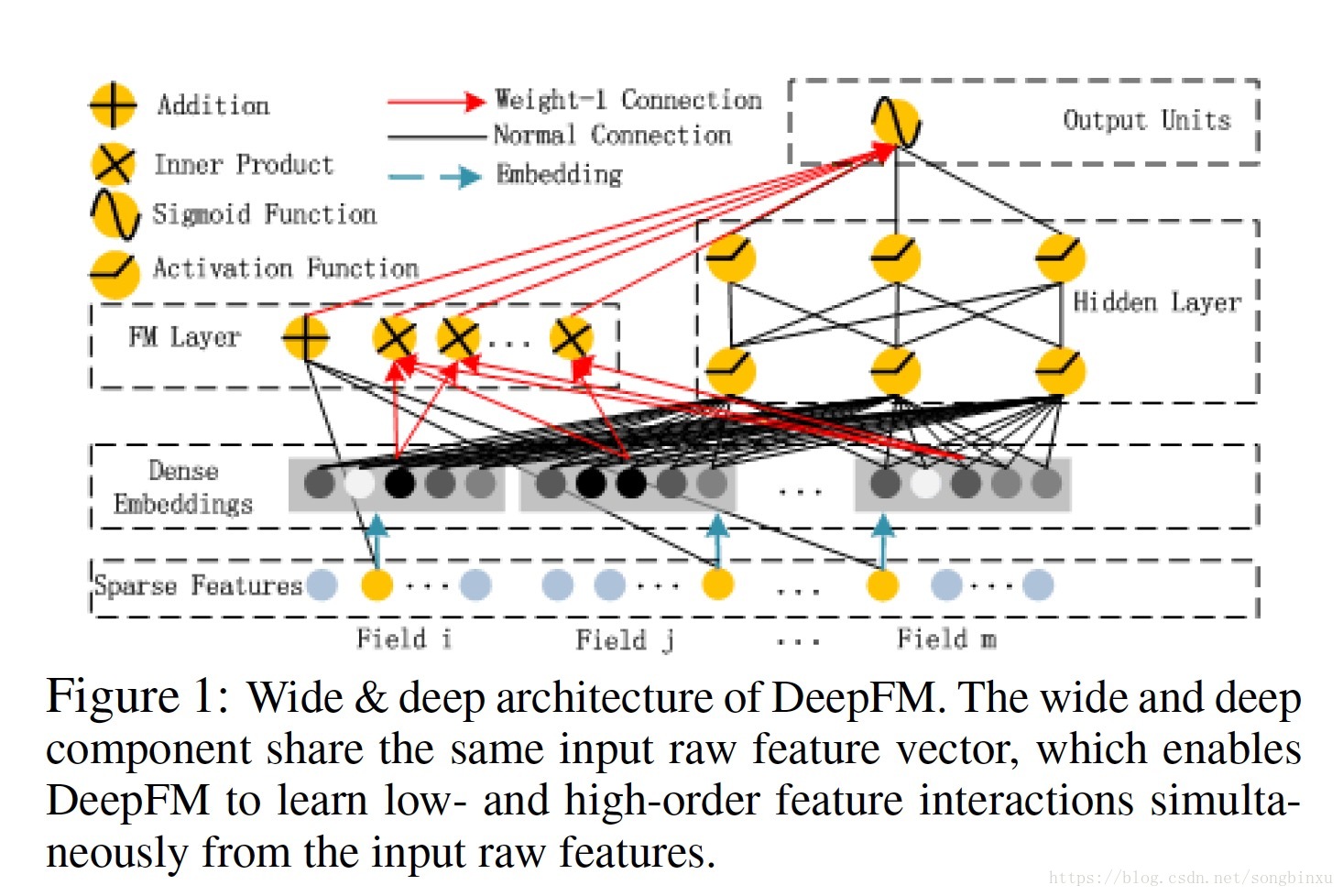
如图,DeepFM由两部分组成:FM component + deep component,两者共享同一个输入。每个特征
xi
x
i
,有一个权重
wi
w
i
(标量)用于FM一次项计算,一个
k
k
维的 latent vector 用于FM二次项计算,Embedding之后还会输入到 deep component。所有参数,包括FM的参数和神经网络的参数,是联合训练的(joint training):
FM Component
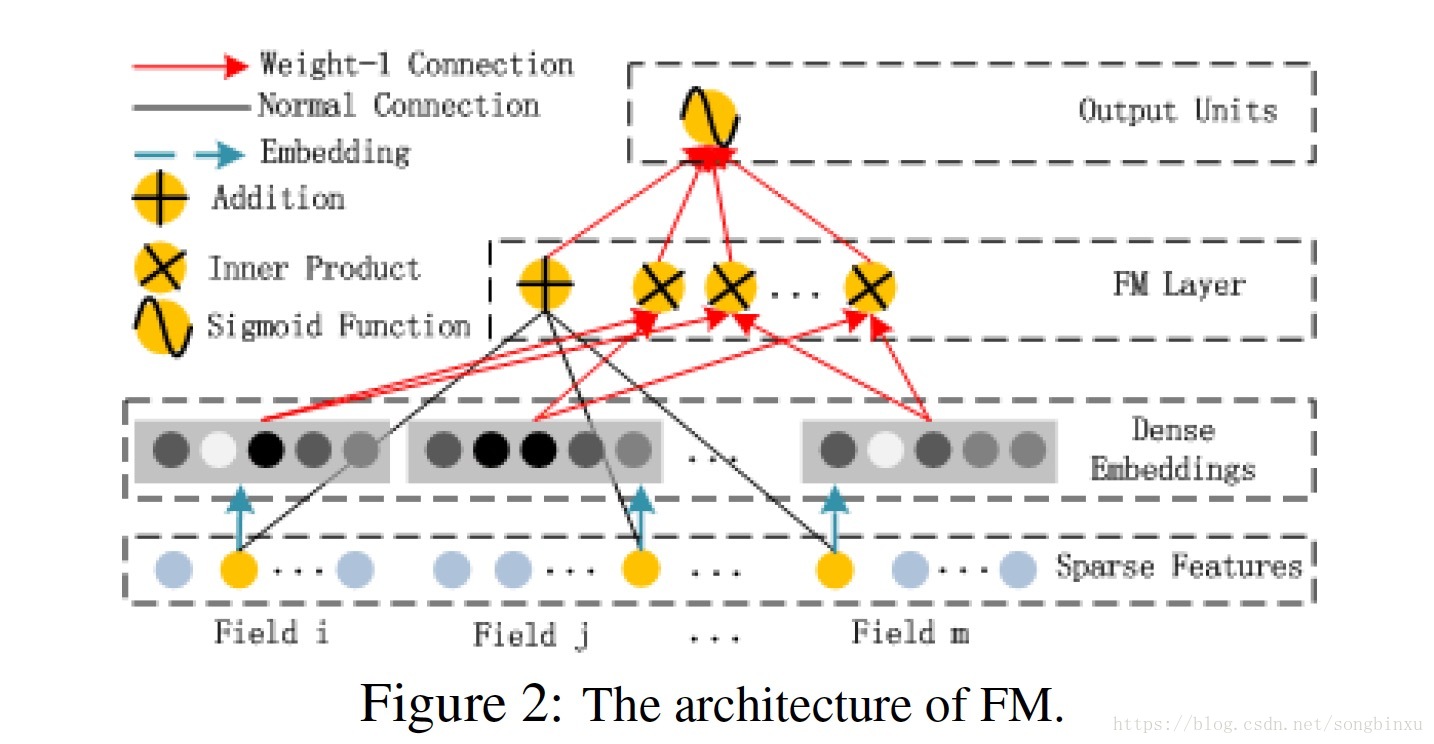
FM component 就是个简单的FM,在我的另一篇博客里有详细描述。FM能高效地提取二阶交叉特征,尤其是当数据非常稀疏的时候。
Deep Component
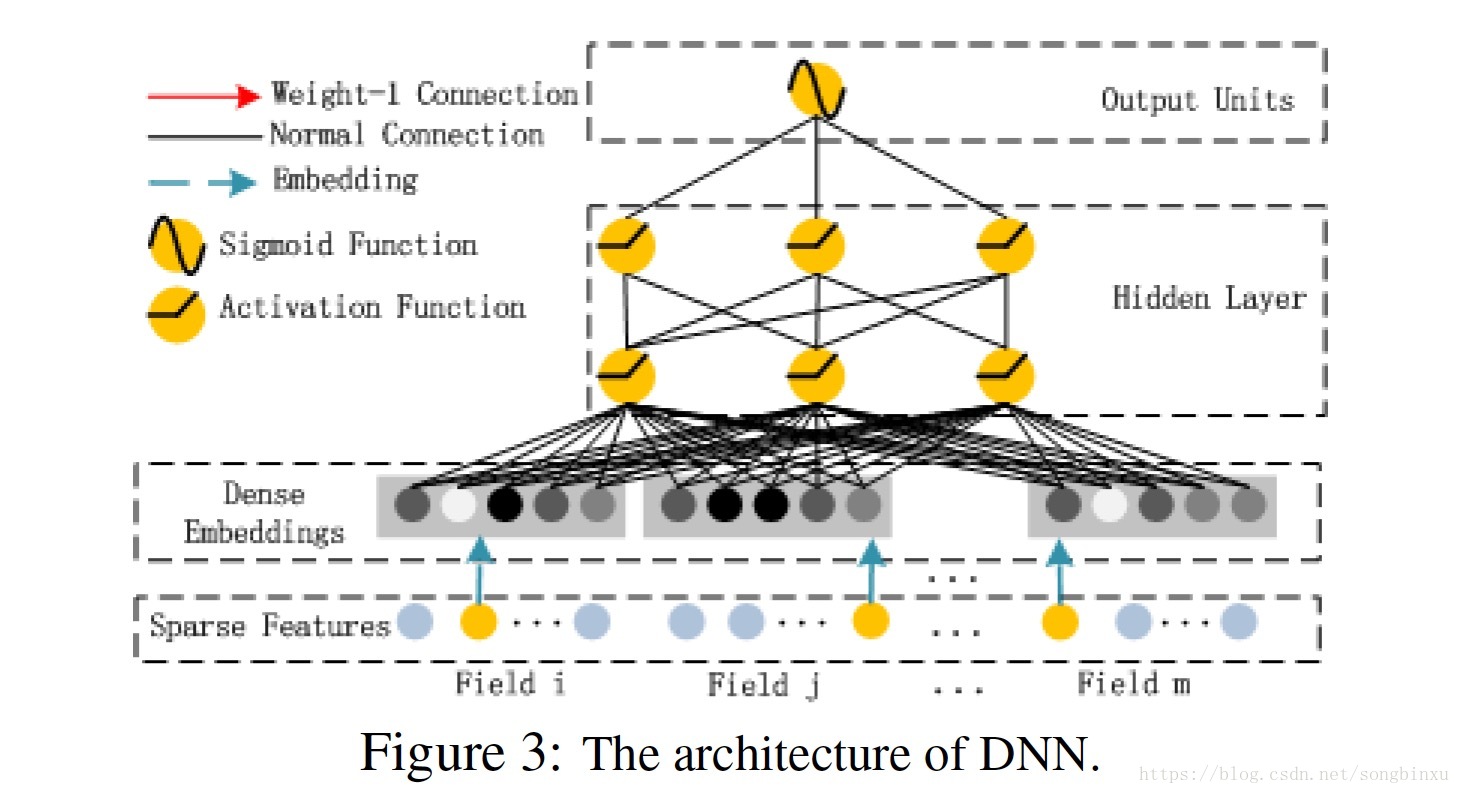
Deep component 是一个前向NN,用于学习更高阶的交叉特征。原始的高维稀疏特征向量被Embedding层压缩成低维稠密特征向量,然后再送入NN的hidden layer。
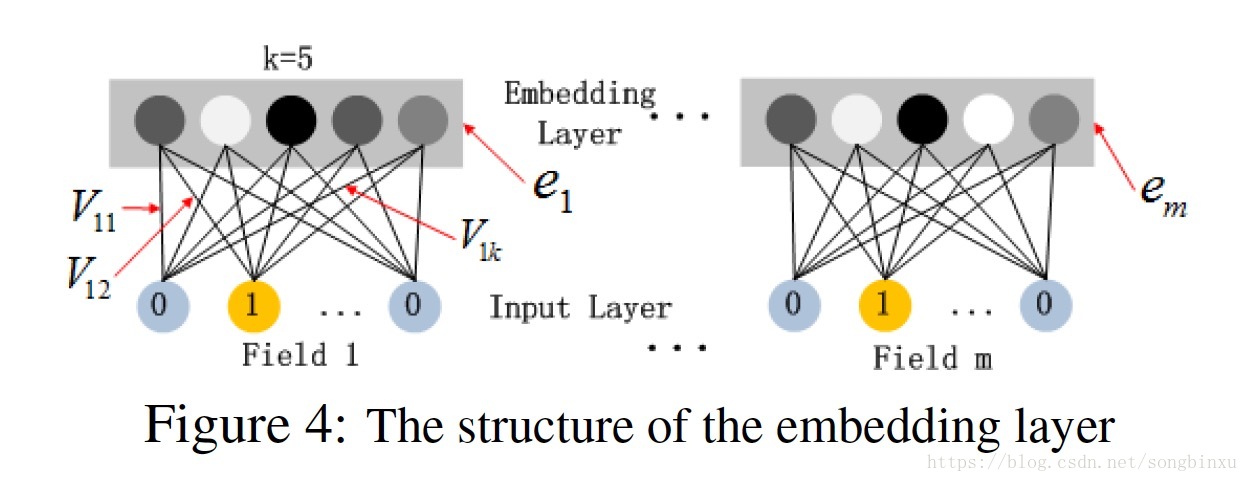
Embedding是对每一个field做的,虽然field vector长短不一,但经过Embedding之后,会变成定长
k
k
。一个field里的每个特征对应一个
k
k
维的,比如上图第一个特征
x1
x
1
对应
V1=[V11,V12,⋯,V1k]
V
1
=
[
V
11
,
V
12
,
⋯
,
V
1
k
]
,只是在这条样本中
x1=0
x
1
=
0
,所以
V1
V
1
得不到训练,
x2=1
x
2
=
1
所以
V2
V
2
能得到训练。
Embedding层的输出是一个
m×k
m
×
k
维向量,可以表示为
a=[e1,e2,⋯,em]
a
=
[
e
1
,
e
2
,
⋯
,
e
m
]
,
ei
e
i
表示 field i 的 Embedding。这个向量将作为DNN的第一层输入,之后每一层和前一层的关系都可表示为下式,最终DNN的输出是
yDNN=RELU(W(H)a(H−1)+bias(H−1))
y
D
N
N
=
R
E
L
U
(
W
(
H
)
a
(
H
−
1
)
+
b
i
a
s
(
H
−
1
)
)
(假设总共有H层隐层)
在早前一些方法中(例如FNN),这个Embedding层的参数 V V <script type="math/tex" id="MathJax-Element-3759">V</script>是要预训练一个FM得到的,而本文不这么干,FM就是整体结构的一部分,跟着DNN一起训练。
DeepFM和其他神经网络的关系
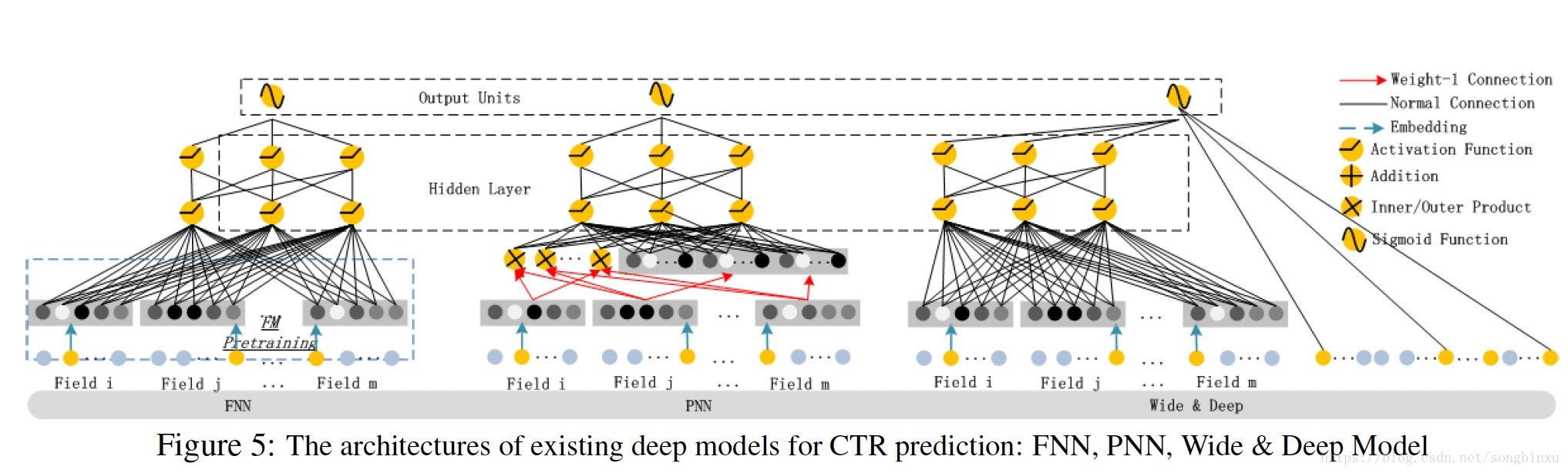
上图给出了几种比较著名的NN相关的CTR预估模型。
FNN是用预训练的FM初始化的DNN,它有三个缺点:受制于FM参数,需要预训练很耗时,仅提取高阶交叉特征。
PNN在Embedding层和NN之间插入一个乘积层(Product Layer),根据乘法的不同,又可以划分为 IPNN(内积),OPNN(外积)和PNN*(内外都有)。外积损失信息太大而导致不可信,内积时间复杂度太高。另外,PNN也仅提取高阶交叉特征。
Wide&Deep能同时提取低阶和高阶交叉特征,但是在Wide part需要人工特征工程。
下面给出一个对比表格。
| - | 不需要预训练 | 高阶交叉 | 低阶交叉 | 不需要特征工程 |
|---|---|---|---|---|
| FNN | 否 | 是 | 否 | 是 |
| PNN | 是 | 是 | 否 | 是 |
| Wide&Deep | 是 | 是 | 是 | 否 |
| DeepFM | 是 | 是 | 是 | 是 |
超参数选择
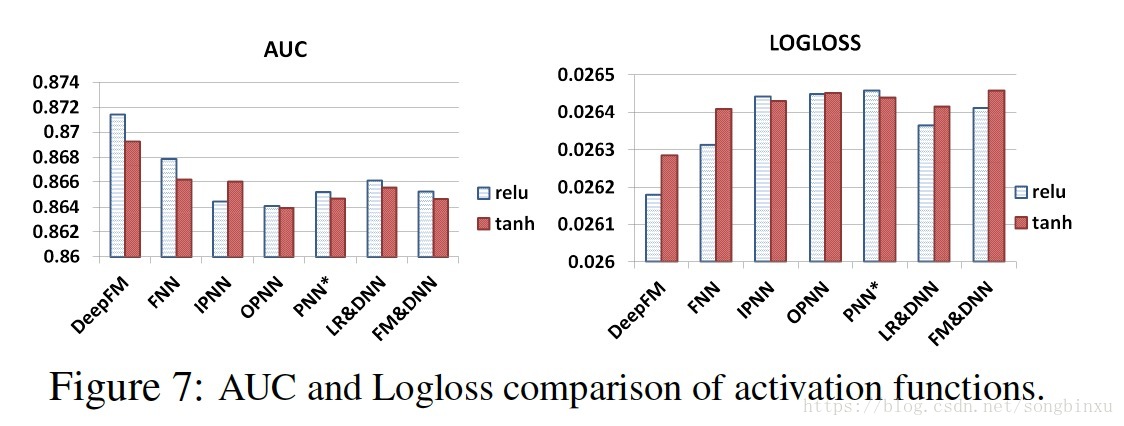
激活函数
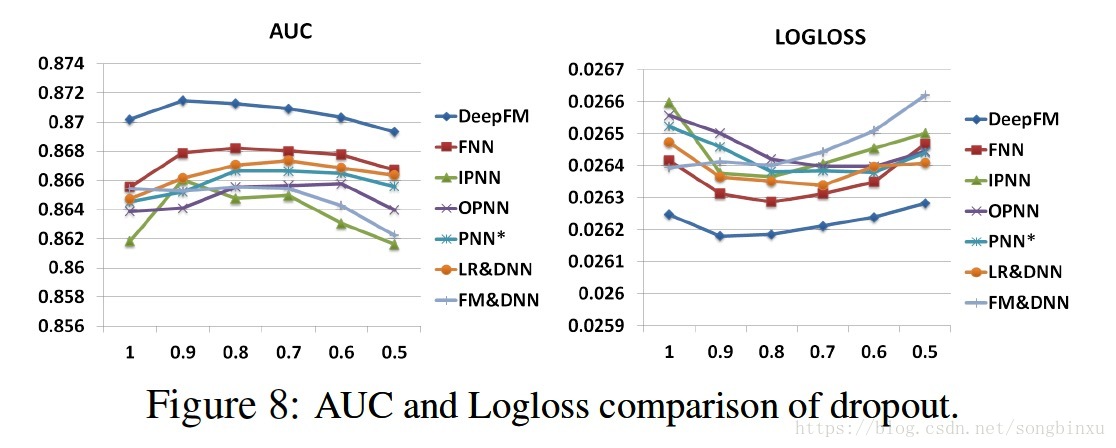
dropout概率
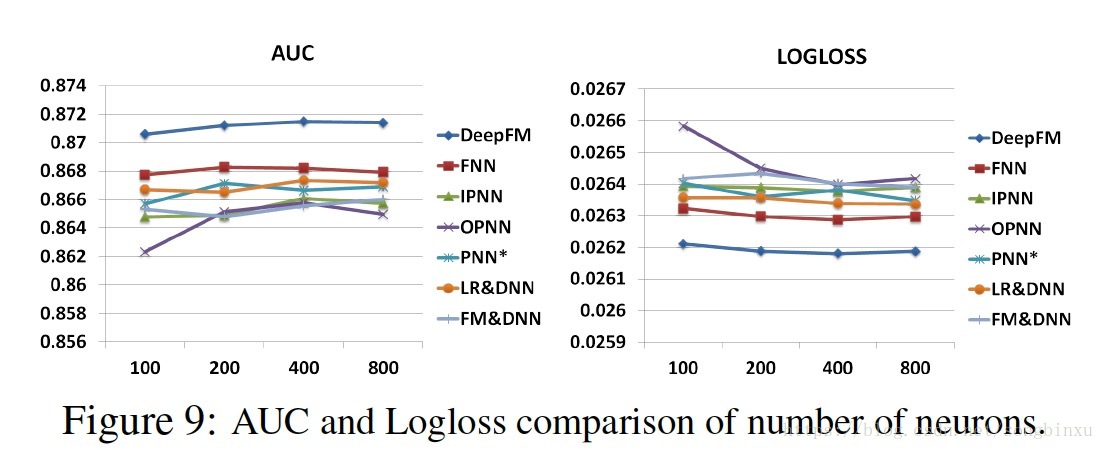
神经元个数
隐层层数
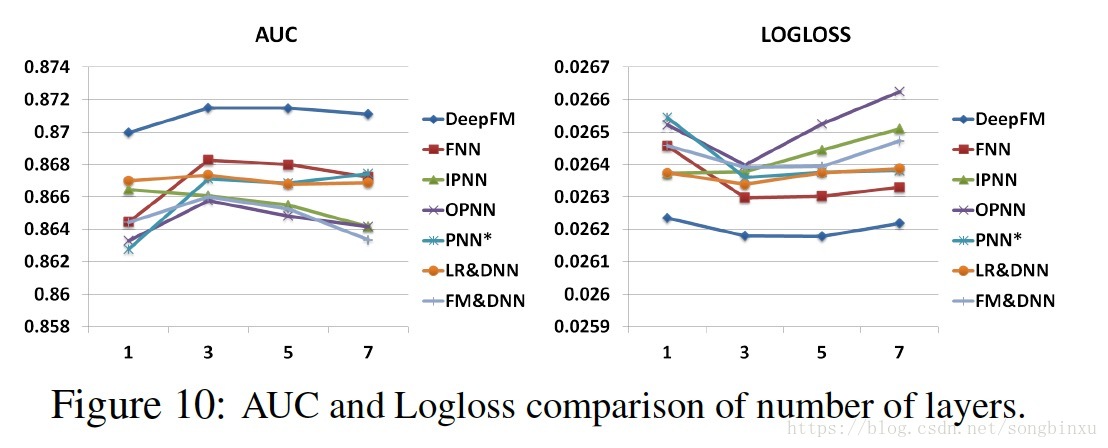
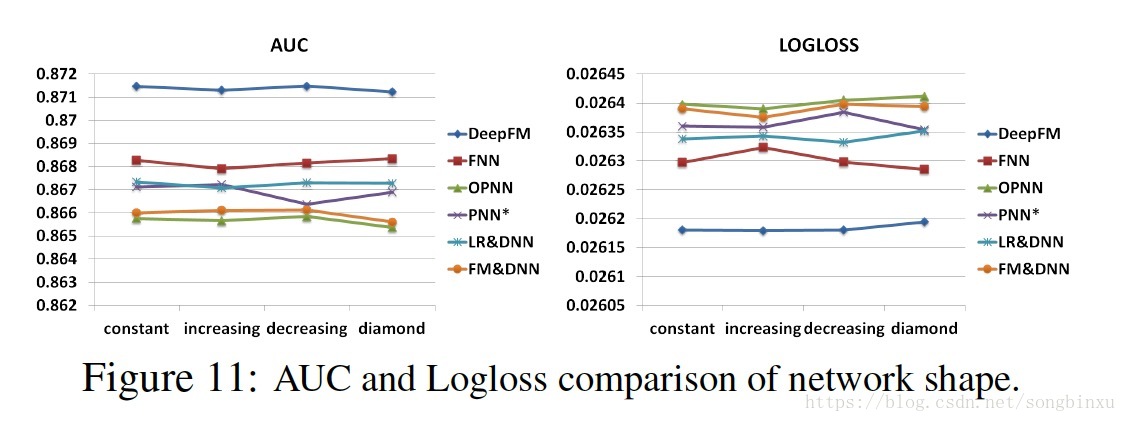
网络形状
constant (200-200-200), increasing (100-200-300), decreasing (300-200-100), and diamond (150-300-150).















 481
481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









