







摘要
在当今互联网工业界中,有许多预测任务需要用到大量的类别特征。要想将这些类别特征送入到模型中,就必须得将其onehot。但这样一来,就会产生大量的稀疏特征,要想从这些稀疏特征中充分学习到有用的信息,必须要考虑特征之间的相互作用。
FM算法是一种常用的解决方案,因为它充分考虑了二阶特征之间的相互作用。然而FM有一个缺点,就是它仅仅以线性的方式组合了特征,并不能考虑到特征之间的非线性关系。
本文提出了一个称为Neural Factorization Machine (NFM)的模型,来解决上述问题。NFM充分结合了FM提取的二阶线性特征与神经网络提取的高阶非线性特征。总得来说,FM可以被看作一个没有隐含层的NFM,故NFM肯定比FM更具表现力。实验证明,NFM效果不错。
模型
1.FM
假设我们有一个特征向量
x∈Rn
x
∈
R
n
,FM算法是通过对每一对特征之间做相乘来提取二阶线性特征,公式如下:
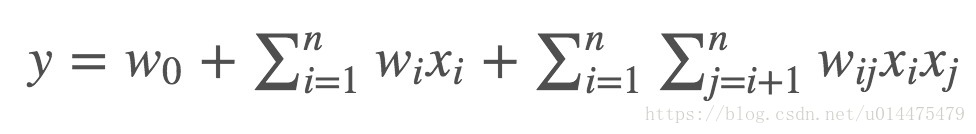
其中
w0
w
0
为全局的
bias
b
i
a
s
,
wi
w
i
则是控制每一个特征
xi
x
i
对预测结果影响的权重。
wij
w
i
j
为二次项的权重。
但这样会造成一个问题,由上式可知,二次项的个数为
n(n−1)2
n
(
n
−
1
)
2
个,并且
xi
x
i
xj
x
j
都是极度稀疏的向量,要有大量能满足
xi
x
i
xj
x
j
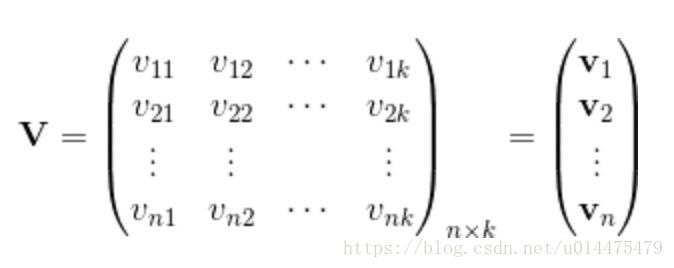
同时不为零的样本才能够对上式进行训练(因为一旦有一个为0则相乘为0),这对数据的要求过于苛刻。又由于所有的
wij
w
i
j
可以组成一个对称矩阵
W
W
,而我们可以将矩阵 分解为
W=VTV
W
=
V
T
V
,故我们可以通过下式来求一个近似解:
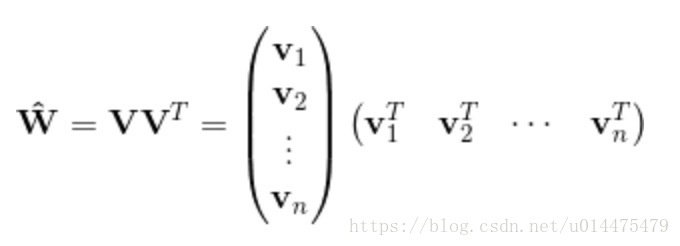
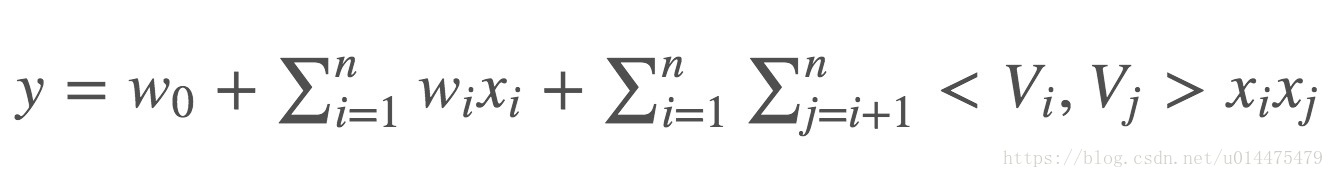
2.NFM
假设我们有特征向量输入
x∈Rn
x
∈
R
n
其中
xi=0
x
i
=
0
代表该样本没有第
i
i
个特征。NFM的目标函数可以由下式表示:
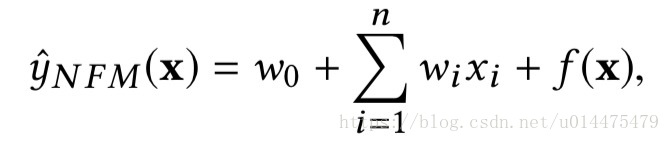
其中第1项与第2项是与FM相似的线性回归部分,第3项是NFM的核心部分,它由一个如下图所示的网络结构组成:
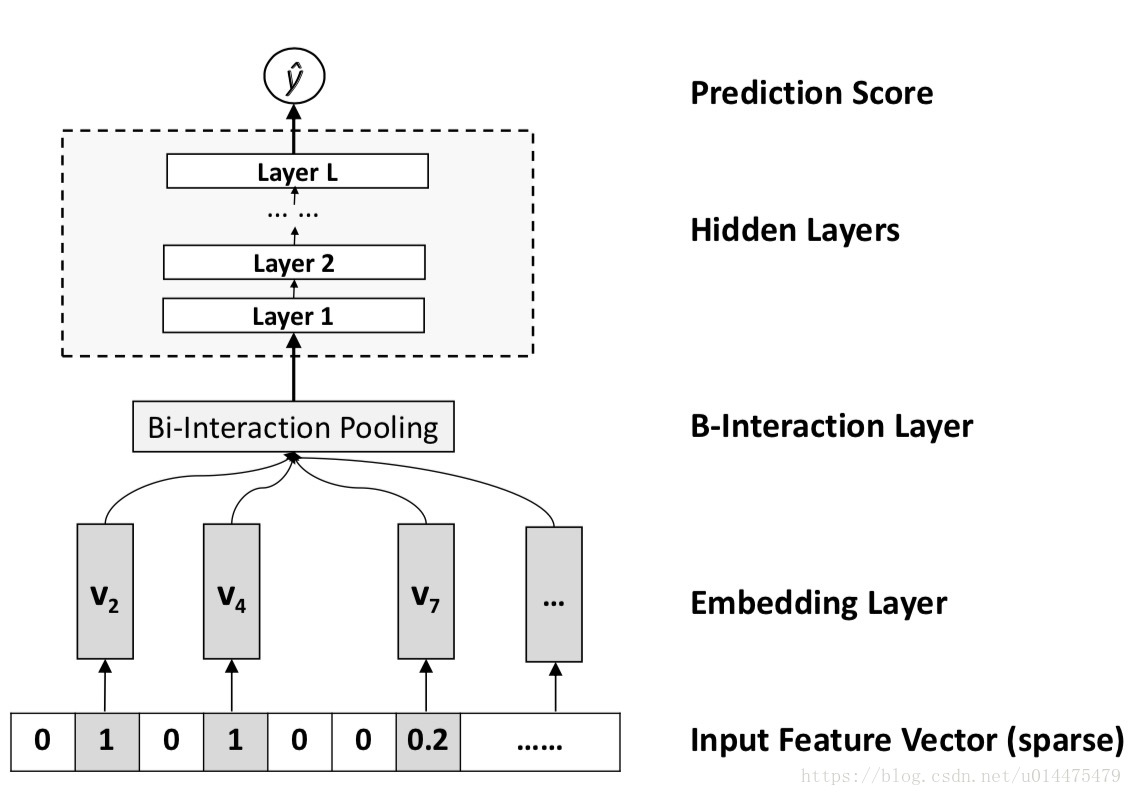
我们来逐层解释上图:
Embedding Layer
该层是一个全连接层,将稀疏的向量给压缩表示。
假设我们有 为第
i
i
个特征的embedding向量,那么在经过该层之后,我们得到的输出为
v1
v
1
,...,xn
,
.
.
.
,
x
n
vn
v
n
}
}
,注意,该层本质上是一个全连接层,不是简单的embedding lookup.
Bi-Interaction Layer
上层得到的输出是一个特征向量的embedding的集合,本层本质上是做一个pooling的操作,让这个embedding向量集合变为一个向量,公式如下:
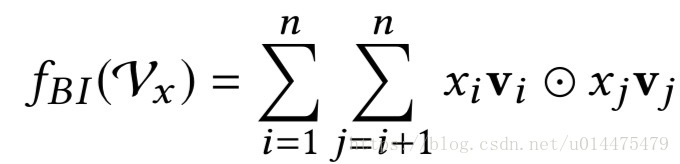
其中
⨀
⨀
代表两个向量对应的元素相乘。显然,该层的输出向量为
k
k
维,本层采用的pooling方式与传统的max pool和average pool一样都是线性复杂度的,上式可以变换为:
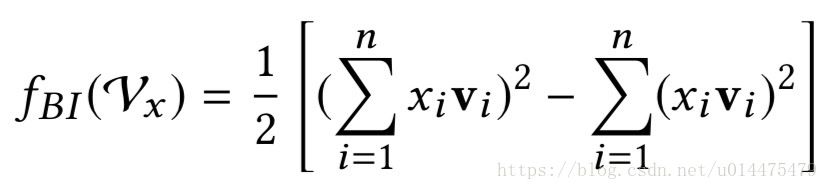
上式中用 来表示
v⨀v
v
⨀
v
,其实本层本质上就是一个fm算法。
hidden layer
就是普通的全连接层,没有什么特别的。
Prediction Layer
将hidden layer的输出过一个n*1的全连接层,得到输出















 719
719











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









