







SVD奇异值分解
正交矩阵
正交矩阵
正交矩阵对应着正交变换,特点在于不改变向量的尺寸(模)和任意两个向量的夹角。在x-y坐标系中,通俗地讲,就是旋转两个坐标轴,得到新的互相垂直的坐标轴,求向量在新坐标系中的投影。
正交变换举例
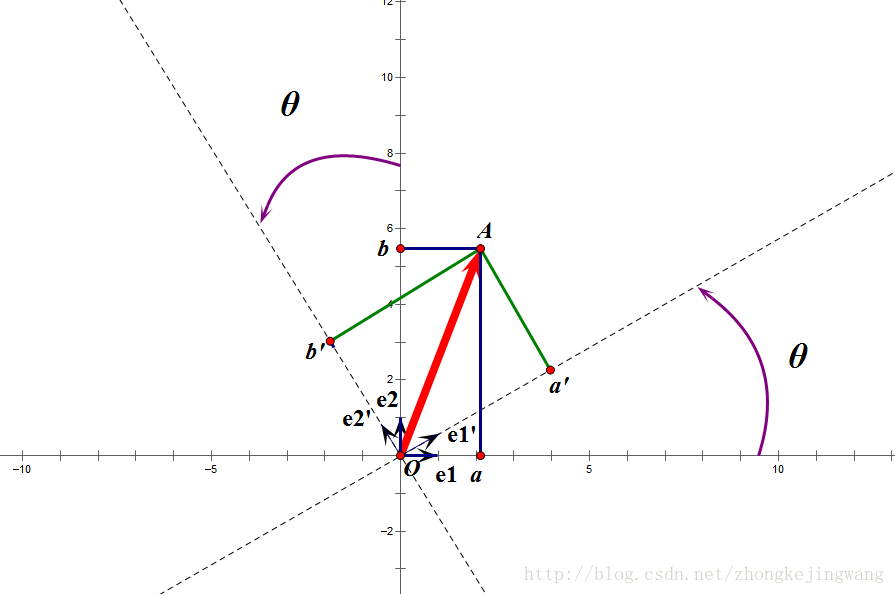
图片摘自此处。 例如向量
OA
O
A
,在原始
e1−e2
e
1
−
e
2
坐标系中表示为
(a,b)T
(
a
,
b
)
T
,在旋转后的坐标系
e′1−e′2
e
1
′
−
e
2
′
中表示为
(a′,b′)T
(
a
′
,
b
′
)
T
,若存在一个矩阵
U
U
使得,则矩阵
U
U
是正交矩阵(可见对应着坐标系之间的正交变换)。
可以代入求得矩阵,且可观察到矩阵的行向量之间都是正交的,列向量之间也是正交的。
正交矩阵的性质
正交阵的逆等于其转置
特征值分解
特征值分解
A
A
是 满秩对称方阵(对称阵的特征向量之间两两正交),有
N
N
个特征值,对应
N
N
个特征向量,有:
可以理解为向量 qi q i 在 A A 的作用下,保持方向不变,只进行比例为的缩放。特征向量所在的直线包含了所有特征向量(称为特征空间)。
以上 N N 个等式写成矩阵形式(是 N×1 N × 1 的列向量!)
等式两边右乘 Q Q 的逆,得到的特征值分解:
进一步,由于特征向量矩阵 Q Q 各列相互正交,所以是正交阵,正交阵的逆等于其转置:
特征值分解的几何意义
矩阵 A A 是一个既有旋转又有缩放的变换,用对向量 x x 进行矩阵变换,即对它进行旋转操作和缩放操作。整个过程在矩阵做EVD之后,可以看成 QΛQTx Q Λ Q T x ,即 x x 依次经过, Λ Λ 和 Q Q 的变换,特别地,如果恰与矩阵 A A 的某个特征向量平行,那么它将不会发生旋转,只发生缩放。
- :将
x
x
由原始空间变换到由各两两正交的特征向量构成的空间中
- ΛQTx Λ Q T x :将变换后的 x x 在特征空间中缩放,轴的缩放因子正是对应的特征值 λi λ i
- QΛQTx Q Λ Q T x :将缩放过的 x x 变换回原始空间
矩阵变换举例
奇异值分解SVD
SVD定义
M×N
M
×
N
矩阵
A
A
的SVD:
SVD推导
首先把 A A 变成方阵 ATA A T A ,于是就能做EVD:
然后把 A A 变成方阵,于是就又能做EVD:
非方阵的秩最多为M和N较小值,两种情况下非零特征值是一样的,多余的特征值都是0。现在假设
A
A
可以分解成的形式,现在求出这三部分:
所以 V′=V V ′ = V , U′=U U ′ = U , ∑′=Λ−−√ ∑ ′ = Λ ,也就是说中间对角矩阵 ∑ ∑ 的元素可以这样求:
SVD性质
对角阵
∑
∑
的奇异值从左上到右下按从大到小排序,一般来说少量几个奇异值(例如
k
k
个)就占据了奇异值之和的绝大部分,因此可以只用这个奇异值和对应的左右特征向量表示原矩阵
A
A
:
总结
SVD可以把任意形状的矩阵分解成 A=U∑VT A = U ∑ V T 的形式, U U 和都是有特征值分解得到的特征向量矩阵,它们都是正交阵, ∑ ∑ 可以由特征值开平方得到。只选择较大的奇异值就能很好地表示原矩阵。
EVD应用-PCA
初衷——最大方差投影
希望找到一个新的正交坐标系,将样本变换过去(投影过去),使得所有样本之间尽可能地分开(方差最大)。
- 样本集 X X 在坐标系(W的每行就是一个标准正交基,即两两之间正交,且模为1)下的投影是 WTX W T X (原因参见正交变换)
- 假设样本是去中心化的(均值为0),投影的方差为 WTXXTW W T X X T W
- 写出有约束优化问题
用拉格朗日乘子法求解:
如此可见,我们所需的新坐标系正是样本协方差 XTX X T X ( d×d d × d )做特征值分解后的特征向量矩阵。总结一下PCA的流程:首先样本去中心化,然后计算样本协方差 XTX X T X ,再对 XTX X T X 做EVD,选取最大的部分特征值所对应的特征向量,构成投影矩阵 W W 。
SVD应用-LSA潜在语义分析
构造单词-文档矩阵
假设有(Document)篇文章,每篇文章都是由很多个单词构成的结构(bag-of-words,单词的位置不重要,只关心数量),而单词来自于一个大小为
W
W
(Word)的字典,则构造矩阵,第
i
i
行第列表示单词
Wi
W
i
在文档
j
j
中出现的次数(或者tf-idf)。通常来说,该矩阵会相当地稀疏。
具体地,会先遍历所有文章进行分词,在这个过程中过滤掉停止词(例如a、the之类的)和标点等,然后进行词频计数等操作。
SVD
将单词-文档矩阵进行SVD,并且只选取部分足够大的奇异值(例如个),对应于不同的主题(语义):
其中 UW×k U W × k 描述了每个单词与不同主题之间的关系, Sk×k S k × k 描述了主题本身, VD×k V D × k 描述了每篇文章与不同主题之间的关系。我们可以从 UW×k U W × k 挖掘同义词,从 VD×k V D × k 挖掘相似文档。那么到底为什么需要做SVD呢?是因为单纯地统计词频或tf-idf并不能描述单词之间或文本之间的关系。然而SVD有一个问题,就是每一个语义具体是什么不可解释,只知道他们是互相正交的。
从SVD到SVD++
SVD在电影推荐中的应用
问题提出
- 稀疏矩阵没法直接SVD,有很多数据是缺失的
- SVD很慢,超过1000维的矩阵做SVD已经相当慢了
电影推荐
现有一个矩阵,行表示用户,列表示电影,矩阵中每个元素表示某个用户对某个电影的打分,显然这个矩阵是极其稀疏的(不是每个用户都看过所有电影的,大多只看过几部),有大量缺失值。现在的问题是,如何预测这些缺失值?即如何预测一个用户对他没看过的电影的评分?
首先,如果把U乘S看成一个矩阵,则SVD可以写成两个矩阵相乘:
那么电影评分矩阵也存在这种分解:
现在P和Q是未知的,如果能通过R中已知的评分训练P和Q,使得P和Q相乘的结果能最好地拟合R中未缺失值,则缺失值就可以通过P的一行乘上Q的一列得到:
P和Q的训练(基于梯度下降法):Basic SVD
要拟合真实的已知评分 rum r u m ,选取平方误差:
计算梯度(当然只能代入R矩阵中 rum r u m 有取值的计算),漂亮的对称结构:
接下来只需要将P和Q用随机数初始化,然后梯度下降迭代即可。
P和Q的训练:RSVD
引入正则化:
计算梯度:
有偏置的RSVD:RSVD 改
用户对电影的打分不仅取决于用户与电影之间的关系,还应该受到用户自身 bu b u 和电影自身性质 bm b m 的影响:
其中
μ
μ
是全局平均分,他描述了整个打分网站的整体打分水平。
引入正则化和惩罚:
如此对于P和Q的导数不变,新增加的三个参数中,两个b是需要学习的,仍然用梯度下降迭代更新,初始值设0即可。
考虑邻域影响的SVD++
P和Q的训练:SVD++
在有偏置RSVD的基础上,还考虑了用户对电影的历史评分。ItemCF衡量用户 u u 对电影的兴趣:
这里
N(u)
N
(
u
)
是用户
u
u
喜欢的电影集合,是电影
m
m
和电影的相似度(在ItemCF中,相似度通过统计所有用户观看的电影列表获得,但注意在SVD++中
w
w
实际上是需要学习的参数),这个式子中求和项的意思是用户过去感兴趣的所有电影和电影的整体相似程度,左边分式用于归一化。
现在嫌矩阵
W
W
太大,用SVD的思想它也能分解 ,即用
xTmyj
x
m
T
y
j
代替
wmj
w
m
j
,
xm
x
m
和
yj
y
j
都是向量
将这个兴趣加到RSVD上
又嫌参数太多,让 x=q x = q :
如此一来,需要迭代学习的参数包括 bu b u , bm b m , puk p u k , qkm q k m , yj y j 。手撸梯度之后,梯度下降求解。
总结
- PCA和SVD都能用来降维,只是PCA用的是特征值分解。
- PCA需要对数据去中心化,可能使样本由稀疏变稠密,提高计算复杂度。
- PCA只能获得矩阵一个方向的分解,SVD能获得两个方向的分解。
- SVD实际上很慢,而且无法处理缺失值,所以采取矩阵分解梯度下降拟合未缺失值
- 梯度下降拟合可能会过拟合,因此采用RSVD
- 有偏置的RSVD是出于对用户和物品各自固有属性的考虑
- SVD++是在有偏置的RSVD基础上,基于ItemCF考虑了用户历史喜好的SVD
参考资料
奇异值分解(SVD)原理详解及推导
知乎-如何理解特征值
《推荐系统实践》















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









