







数据集为,糖尿病患者各项指标以及是否换糖尿病。
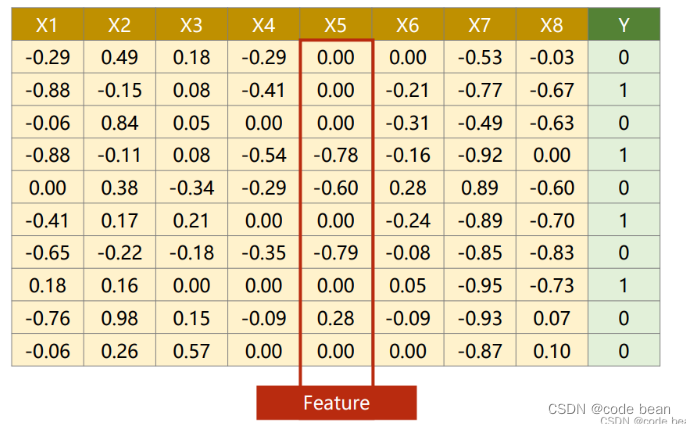
diabetes.csv 训练集
diabetes_test.csv 测试集
import torch
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
import numpy as np
# 注意这里必须写成两维的矩阵
xy = np.loadtxt('diabetes.csv', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1])
y_data = torch.from_numpy(xy[:, [-1]])
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 2)
self.linear4 = torch.nn.Linear(2, 1)
self.sigmoid = torch.nn.Sigmoid()
self.activate = torch.nn.ReLU()
# __call__() 中会调用这个函数!
def forward(self, x):
# x = self.activate(self.linear1(x))
# x = self.activate(self.linear2(x))
# x = self.activate(self.linear3(x))
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
x = self.sigmoid(self.linear4(x))
return x
# model为可调用的! 实现了 __call__()
model = Model()
# 指定损失函数
# criterion = torch.nn.MSELoss(size_average=Flase) # True
# criterion = torch.nn.MSELoss(reduction='sum') # sum:求和 mean:求平均
criterion = torch.nn.BCELoss(size_average=True) # 二分类交叉熵损失函数
# -- 指定优化器(其实就是有关梯度下降的算法,负责),这里将优化器和model进行了关联
# optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # 这个用这个很准啊,其他得根本不行啊
# optimizer = torch.optim.Rprop(model.parameters(), lr=0.01)
for epoch in range(5000):
y_pred = model(x_data) # 直接把整个测试数据都放入了
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad() # 会自动找到所有的w和b进行清零!优化器的作用 (为啥这个放到loss.backward()后面清零就不行了呢?)
loss.backward()
optimizer.step() # 会自动找到所有的w和b进行更新,优化器的作用!
# 测试
xy = np.loadtxt('diabetes_test.csv', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1])
y_data = torch.from_numpy(xy[:, -1])
x_test = torch.Tensor(x_data)
y_test = model(x_test) # 预测
print('y_pred = ', y_test.data)
# 对比预测结果和真实结果
for index, i in enumerate(y_test.data.numpy()):
if i[0] > 0.5:
print(1, int(y_data[index].item()))
else:
print(0, int(y_data[index].item()))
从代码看出,从一开始数据特征维度为8维,通过一层层的降维最终输出一维数据(输入虽然是多维,但是输出是一维一个概率值,仍然是个二分类问题)
如: Linear(8, 6) 表示输入特征是8维,输出特征6维。此时考虑的维度是列(未知数个数)。不考虑行的维度的,因为行的维度表示的是样本的个数,而对于pythroch的函数,样本个数是无所谓的,一个也行,一堆也罢,它只关心列的维度。
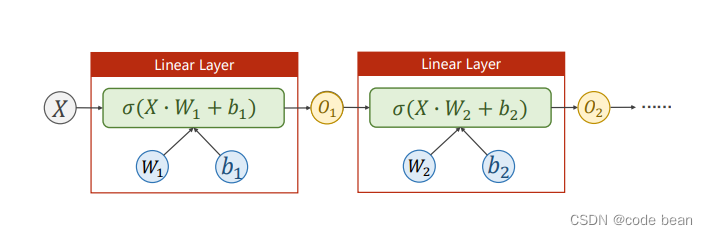
最终代码构建的模型如下:(我代码里是多构建了一层,大家也可以多尝试)

这里注意,虽然这里叫Linear Layer,但是其实,它里面是套了一个激活函数的,所以其实是非线性的,如果是线性的也就不叫神经网络
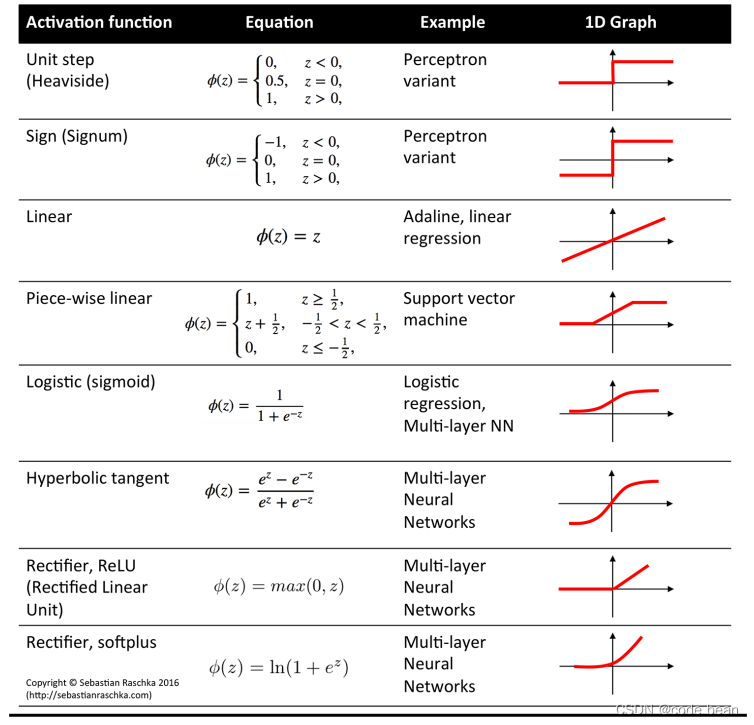
其他的激活函数也可以多试试:
欢迎大家将自己的设置发到评论区。看看大家预测的效果如何。
目前还没有对数据进行小批量处理,后续加上。
参考资料:
数据集资源:
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











