







自回归、自编码、序列到序列:序列模型的三大范式解析
自然语言处理(NLP)的核心挑战是建模序列数据的依赖关系。自2010年代以来,三大范式主导了序列模型的发展:自编码(Autoencoding)、自回归(Autoregressive)和序列到序列(Seq2Seq)。它们如同光谱的三个端点:自回归聚焦单向生成,自编码擅长双向理解,Seq2Seq则架起输入输出的桥梁。本文将深入解析三者的技术本质、架构差异及应用边界。
一、编码器与解码器
在介绍 自回归和自编码以及序列到序列之前,我们回顾一下什么是编码器和解码器。
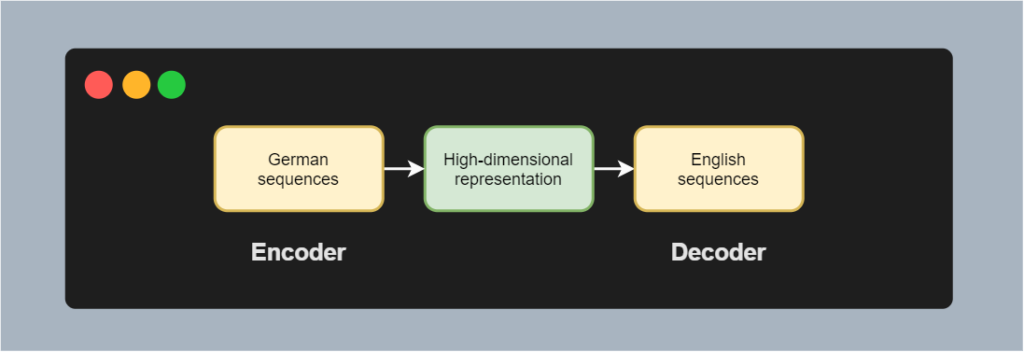
1.1 编码器(Encoder)
编码器是深度学习中用于将输入数据(如图像、文本)压缩为高纬特征表示(h)的模块。其核心功能是提取数据的关键语义信息,实现降维。典型结构包括CNN、RNN或Transformer。数学上,编码器可表示为:
h
=
f
θ
(
x
)
h = f_{\theta}(x)
h=fθ(x)
其中,
x
x
x 是输入数据,
f
θ
f_{\theta}
fθ 是编码器的参数化函数(如多层神经网络),
h
h
h 是压缩后的特征向量。目标是通过最小化重建损失(如MSE)保留输入的核心信息,例如图像自编码器中“猫”的像素数据被编码为“猫”的特征向量。
1.2 解码器(Decoder)
解码器将编码器生成的特征表示(h)恢复或生成为目标数据(如重建图像、生成文本)。其结构常与编码器对称(如自编码器的反卷积网络),或采用自回归生成(如GPT的Transformer解码器)。数学表达为:
x
^
=
g
ϕ
(
h
)
\hat{x} = g_{\phi}(h)
x^=gϕ(h)
其中,
g
ϕ
g_{\phi}
gϕ 是解码器的参数化函数,
x
^
\hat{x}
x^ 是生成的输出。在序列生成任务(如机器翻译)中,解码器逐步生成序列(
y
t
y_t
yt ),依赖历史生成结果(
y
<
t
y_{<t}
y<t )和编码器的上下文信息(如注意力机制):
y
t
=
g
ϕ
(
y
<
t
,
h
,
Attention
(
h
,
y
<
t
)
)
y_t = g_{\phi}(y_{<t}, h, \text{Attention}(h, y_{<t}))
yt=gϕ(y<t,h,Attention(h,y<t))
目标是最大化条件概率
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X) ,例如根据“Hello”的编码生成“你好”。
二、自编码模型(Autoencoding)
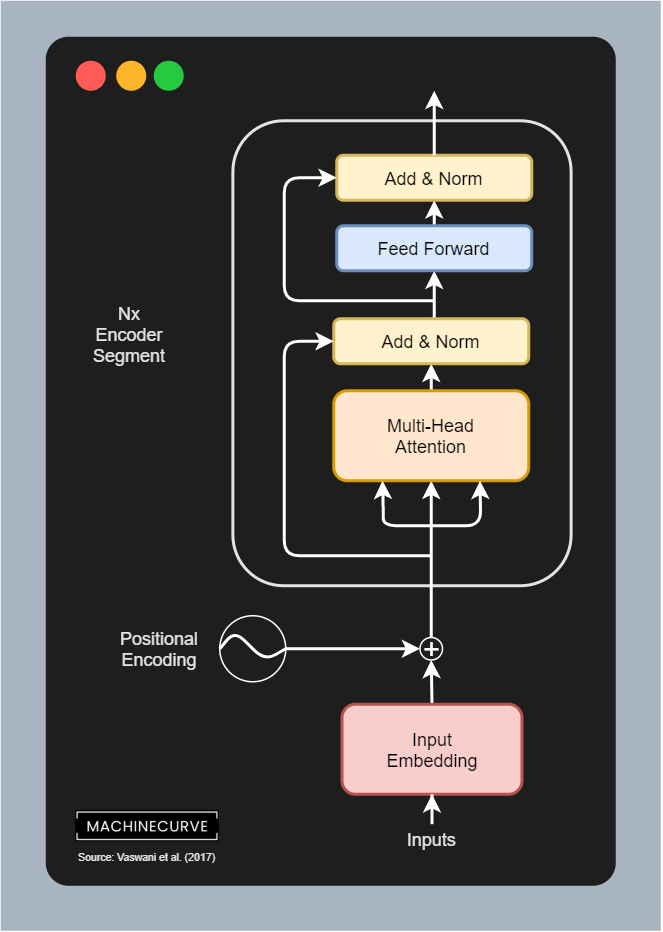
通过“破坏-重建”学习数据表征,典型方法是掩码语言模型(MLM)(如BERT)。随机遮蔽输入token(如15%的[MASK]),训练模型根据双向上下文恢复被遮蔽内容。架构基于Transformer编码器,允许每个位置访问完整上下文。训练目标为重建误差最小化:
min
L
(
x
,
x
^
masked
)
\min \mathcal{L}(x, \hat{x}_{\text{masked}})
minL(x,x^masked)
典型应用有:文本分类(BERT)、问答(RoBERTa)、实体识别(SpanBERT)。 其双向语义建模(解决自回归的单向缺陷),预训练表示的通用性。但是,掩码标记的“未见性”(微调时无[MASK]),生成任务需额外适配(如T5的文本到文本框架)。
三、自回归模型(Autoregressive)
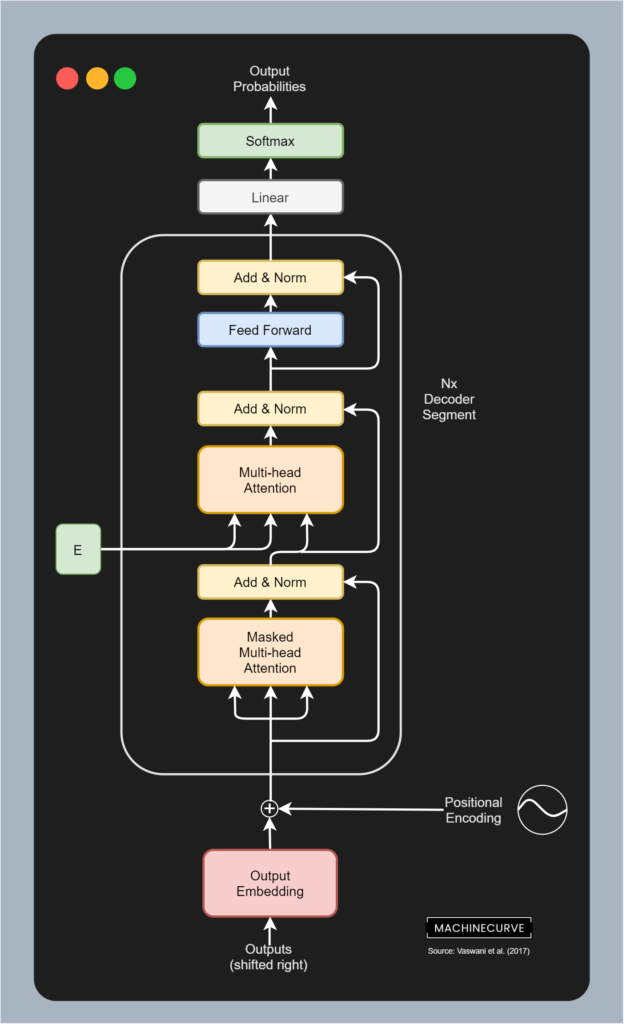
自回归模型遵循“因果关系”,每个位置的输出仅依赖过去的历史。在NLP中,典型实现是掩码Transformer解码器(如GPT系列),通过因果掩码(Causal Mask)确保每个token只能访问左侧上下文。训练目标为条件概率最大化:
P
(
x
1
,
x
2
,
.
.
.
,
x
n
)
=
∏
t
=
1
n
P
(
x
t
∣
x
1
,
.
.
.
,
x
t
−
1
)
P(x_1, x_2, ..., x_n) = \prod_{t=1}^n P(x_t | x_1, ..., x_{t-1})
P(x1,x2,...,xn)=t=1∏nP(xt∣x1,...,xt−1)
可以应用于:文本生成(GPT-4)、语音合成(Tacotron)、代码补全(GitHub Copilot)。 而且,生成的自洽性(逐步依赖),无需后处理直接输出序列。 但是,单向上下文限制(无法利用未来信息),推理速度随序列长度线性增长(自回归解码)。
四、序列到序列(Seq2Seq)
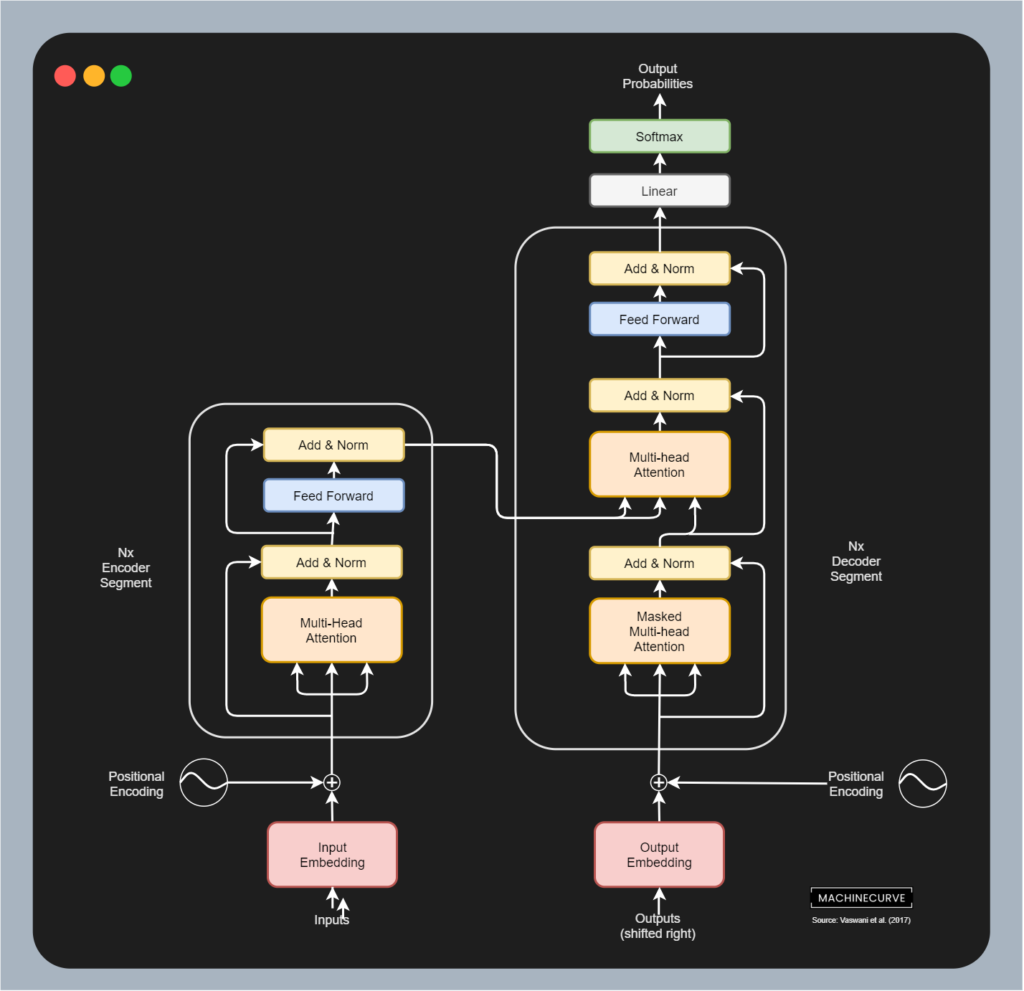
通过编码器-解码器(Encoder-Decoder)框架,将输入序列(如句子)映射到输出序列(如翻译)。编码器(如Transformer编码器)提取输入语义,解码器(如Transformer解码器)生成输出。训练目标为条件序列生成:
P
(
y
1
,
.
.
.
,
y
m
∣
x
1
,
.
.
.
,
x
n
)
=
∏
t
=
1
m
P
(
y
t
∣
y
1
,
.
.
.
,
y
t
−
1
,
Encoder
(
x
)
)
P(y_1, ..., y_m | x_1, ..., x_n) = \prod_{t=1}^m P(y_t | y_1, ..., y_{t-1}, \text{Encoder}(x))
P(y1,...,ym∣x1,...,xn)=t=1∏mP(yt∣y1,...,yt−1,Encoder(x))
因此,原始 Transformer 模型(又称vanilla或经典Transformer)是一种 Sequence-to-Sequence 模型。
典型应用有:机器翻译(Google Translate)、文本摘要(BART)、语音识别(LAS)。其灵活处理变长输入输出(如句子→段落),编码器捕捉全局依赖,解码器生成可控序列。但是,编码器和解码器的独立优化可能导致语义鸿沟,推理需两次前向传播(编码+解码)。
五、总结
| 维度 | 自回归 | 自编码 | Seq2Seq |
|---|---|---|---|
| 核心任务 | 单向生成(NLG) | 双向理解(NLU) | 跨模态/跨序列转换 |
| 上下文依赖 | 单向(过去→未来) | 双向(完整上下文) | 编码器:双向;解码器:单向 |
| 架构基础 | Transformer解码器 | Transformer编码器 | 编码器+解码器(如Transformer) |
| 训练目标 | 自回归LM(P(x_t|x<t)) | 去噪AE(P(x|x_masked)) | 序列生成(P(y|x)) |
| 典型模型 | GPT、Llama、PaLM | BERT、ELECTRA、GPT-NeoX | T5、Marian、ByT5 |
| 推理方式 | 自回归解码(逐token) | 一次性前向传播 | 编码→解码(两阶段) |
| 延迟敏感性 | 高(逐步依赖) | 低(并行处理) | 中(编码并行,解码串行) |
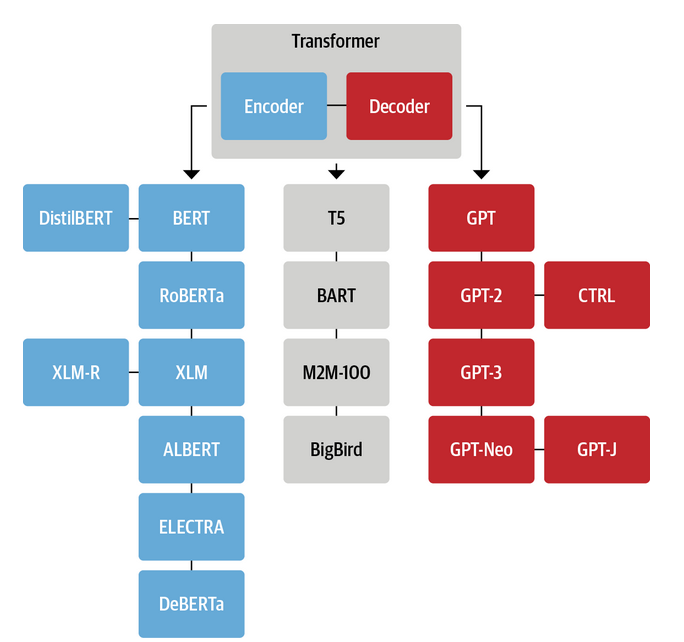
上图给出了,基于transformer架构模型,蓝色表示Transformer encoder(AE模型),红色表示Transformer decoder(AR模型),灰色表示Transformer Encoder-Decoder(seq2seq模型)。
此外,还有一些 范式融合:突破边界的创新实践:
- XLNet(自回归+双向): 提出
排列语言模型,通过随机排列输入序列,在自回归框架下实现双向上下文(每个位置可访问所有非自身token),解决BERT的掩码不一致问题。 - T5(自编码→Seq2Seq): 将所有NLP任务统一为
文本到文本,通过编码器-解码器架构(基于自编码预训练)处理生成与理解任务,证明统一范式的可行性。 - RETRO(检索增强+自回归): 在自回归模型中引入
外部知识检索,通过编码器提取查询表征,解码器生成时融合检索结果,平衡生成创造性与事实准确性。
模型选择的逻辑
- 生成类任务(如对话、诗歌创作):自回归模型更优(时序生成的自然性)。
- 理解类任务(如情感分析、信息抽取):自编码模型更擅长(双向语义捕捉)。
- 跨模态/跨序列任务(如翻译、语音转文本):Seq2Seq架构更适配(输入输出解耦)。
- 复杂任务(如多轮对话+知识检索):融合架构(如自回归+检索)是趋势。
延伸思考:
- 扩散模型(如Diffusion)的
去噪生成是否重构了序列生成范式?(以及有相关方向的研究出来了) - 神经符号模型(如Neuro-Symbolic AI)如何与三大范式结合,解决逻辑推理(自编码的短板)与符号落地(自回归的局限)问题?
参考文献:
[1] Vaswani, A., et al. (2017). Attention Is All You Need. NeurIPS.
[2] HuggingFace. (n.d.). Summary of the Models. Transformers Documentation.
[3] Wang, Z., et al. (2017). Tacotron 2: Better Speech Synthesis. arXiv.
[4] Brown, T., et al. (2020). Language Models Are Few-Shot Learners. OpenAI.
[5] Devlin, J., et al. (2019). BERT: Pre-training of Deep Bidirectional Transformers. NAACL.
[6] Liu, Y., et al. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv.
[7] Clark, K., et al. (2020). ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. ICLR.
[8] Lewis, M., et al. (2020). BART: Denoising Sequence-to-Sequence Pre-training. ACL.
[9] Sutskever, I., et al. (2014). Sequence to Sequence Learning with Neural Networks. NeurIPS.
[10] Gehring, J., et al. (2017). Convolutional Sequence to Sequence Learning. arXiv.
[11] Yang, Z., et al. (2019). XLNet: Generalized Autoregressive Pretraining for Language Understanding. NeurIPS.
[12] Raffel, C., et al. (2020). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. JMLR.
[13] Ho, J., et al. (2020). Denoising Diffusion Probabilistic Models. NeurIPS.
[14] Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS.
[15] Singhal, T., et al. (2021). FLAVA: A Foundational Language And Vision Alignment Model. arXiv.
[16] Press, O., et al. (2023). Fast Autoregressive Decoding with Blockwise Parallelism. ACL.
[17] https://zhuanlan.zhihu.com/p/625714067
[18] https://machinecurve.com/index.php/2020/12/28/introduction-to-transformers-in-machine-learning

















 2596
2596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









