







QWen2.5 论文解读
@(大模型)[Qwen2.5, 论文解读]
- 论文: https://arxiv.org/abs/2412.15115 (2024.12.14)
- 模型: https://huggingface.co/Qwen https://modelscope.cn/organization/qwen
- 代码: https://github.com/QwenLM/Qwen2.5
- web: https://chat.qwenlm.ai (官方客户端,目前支持: Qwen2.5-Max、Qwen2.5-Plus、Qwen2.5-Turbo)
总体来说,从"Qwen2.5 Technical Report" 来看,Qwen2.5 做了一些改进,通过改进预训练和后训练技术、优化架构和分词器等,提升了模型性能,在多领域任务中表现出色。虽然技术上亮眼的地方不多,但好歹更新了,比LLama还是好点,也还是2024的开源大语言模型扛鼎之人:
- 数据集: 使用了更 大 夶 𡘙 的数据集(这也是阿里的技术壁垒的一部分,毕竟模型可以开源,数据集可不会,哈哈)
- 模型:模型上使用了主流的MoE(已经不算创新了)
- 训练方式:将提升多轮对话逻辑性的强化学习步骤,拆分成离线强化学习和在线强化学习。这里的离线强化学习就是RLHF。
论文总结
下面按照Qwen2.5这篇文章结构简单总结论文的结构:
- 重点解决的问题:旨在打造更优的大语言模型,解决过往模型在数据、规模、应用等方面的局限,提升模型的通用性、准确性和效率,以满足多样化的使用需求,推动大语言模型在各领域的应用与发展。
- 创新点
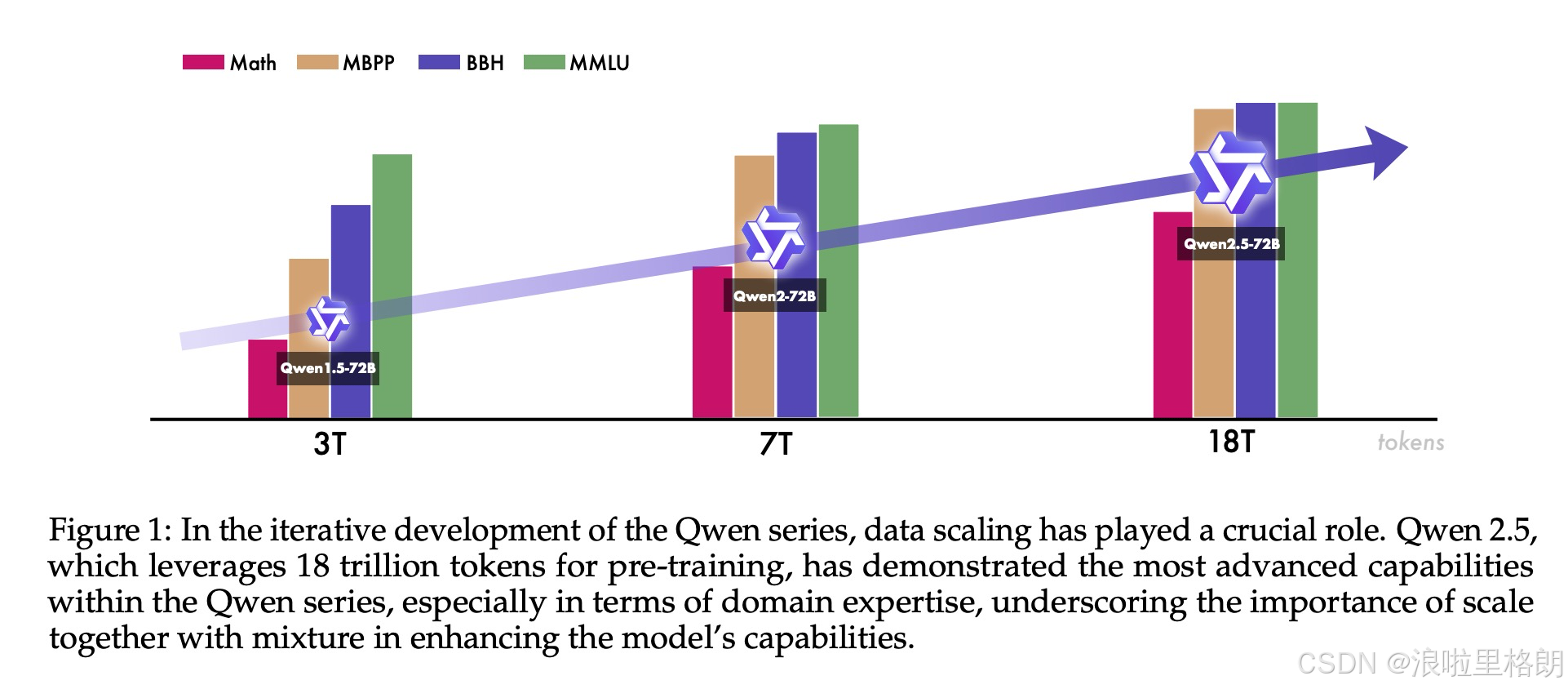
- 数据处理创新:如Figure 1所示,预训练数据从7万亿token扩展到 18万亿token ,通过优化数据筛选、融入高质量领域数据、生成合成数据以及平衡数据分布等手段,提升数据质量。利用Qwen2-Instruct模型进行数据质量过滤和内容分类,提高数据的质量和多样性。
- 训练方法创新:开发超参数缩放定律,确定不同规模模型的最优训练超参数,如批量大小和学习率;采用两阶段预训练和渐进式上下文长度扩展策略,提升模型对长序列的处理能力;后训练阶段,通过扩展监督微调数据覆盖范围和 采用两阶段强化学习 ,增强模型多方面的能力。
- 模型架构创新:开源的密集模型采用基于Transformer的解码器架构,并融入多种优化组件;基于密集模型扩展出 MoE模型架构 ,通过替换FFN层和采用创新路由机制提升性能;扩展控制令牌,统一词汇表,减少兼容性问题。
- 实验结果
- 基准测试表现优异:在涵盖语言理解、推理、数学、编码等多领域的基准测试中,Qwen2.5系列模型性能卓越。例如:
- Qwen2.5-72B 基础模型在多项任务上超越同类别模型,与参数规模大五倍的 Llama-3-405B 相当;
- 指令调整模型 Qwen2.5-72B-Instruct 在多个关键基准测试中甚至超过 Llama-3.1-405B-Instruct 。
- 长文本处理能力突出:借助 YARN和DCA 等技术,Qwen2.5模型长文本处理能力显著提升。Qwen2.5-Turbo在1M令牌的密钥检索任务中准确率达100%,Qwen2.5-72B-Instruct在长文本基准测试中表现强劲,超越众多开源和专有模型。
- 奖励模型效果良好:在多个奖励模型评估基准测试中,Qwen2.5-RM-72B表现出色,在PPE和内部收集的中文人类偏好基准测试中领先,在其他基准测试中也名列前茅。
- 基准测试表现优异:在涵盖语言理解、推理、数学、编码等多领域的基准测试中,Qwen2.5系列模型性能卓越。例如:
- 存在的不足:
- 当前 奖励模型评估基准 存在局限性,可能引发Goodhart定律,导致模型在其他基准测试中性能下降;
- 奖励模型评估基准得分与 强化学习模型 性能之间的关联不紧密,难以准确预测强化学习模型的性能,需要进一步研究更具预测性的评估方法。
网络结构
Qwen2.5系列模型包含开源的密集模型与用于API服务的MoE模型,在架构设计、参数配置与token处理上具备独特优势,有力支撑了模型的高性能表现。
- 整体架构分类:Qwen2.5系列模型分为开源的密集模型(Qwen2.5-0.5B/1.5B/3B/7B/14B/32B/72B)和用于API服务的MoE模型(Qwen2.5-Turbo和Qwen2.5-Plus)。
- 密集模型架构细节
- 基础架构:采用基于 Transformer的解码器 架构,融入多种关键组件提升性能。
- 注意力机制:运用 分组查询注意力(GQA) 提升KV缓存利用效率,降低内存占用和计算量。
- 激活函数:使用 SwiGLU激活函数 增强模型非线性表达能力,学习复杂数据模式。
- 位置编码:借助 旋转位置嵌入(RoPE) 对位置信息编码,使模型有效捕捉文本序列顺序特征。
- 归一化方式:采用 RMSNorm 进行预归一化,确保训练过程稳定,加速收敛并提高模型泛化能力。
- 参数设置:各模型在 层数、头数、嵌入层共享 等方面有差异。层数从0.5B模型的24层到72B模型的80层不等;头数(查询/键值)也不同,如0.5B模型为14/2,7B模型为28/4;部分模型(0.5B、1.5B、3B)共享嵌入层,7B及以上模型不共享 。
- MoE模型架构扩展:基于密集模型架构,用专门的MoE层替换标准前馈网络(FFN)层。MoE层含多个FFN专家和路由机制,根据输入动态分配计算资源,将token分配给前K个专家处理,提升模型效率和性能。(还是传统 MoE方法)
- tokenizer设置:使用Qwen的tokenizer,采用 字节级字节对编码(BBPE) ,词汇表含151,643个常规token。控制token从3个扩展到22个,为工具功能新增2个token,其余用于扩展模型能力,统一了所有Qwen2.5模型的词汇表,减少兼容性问题 。
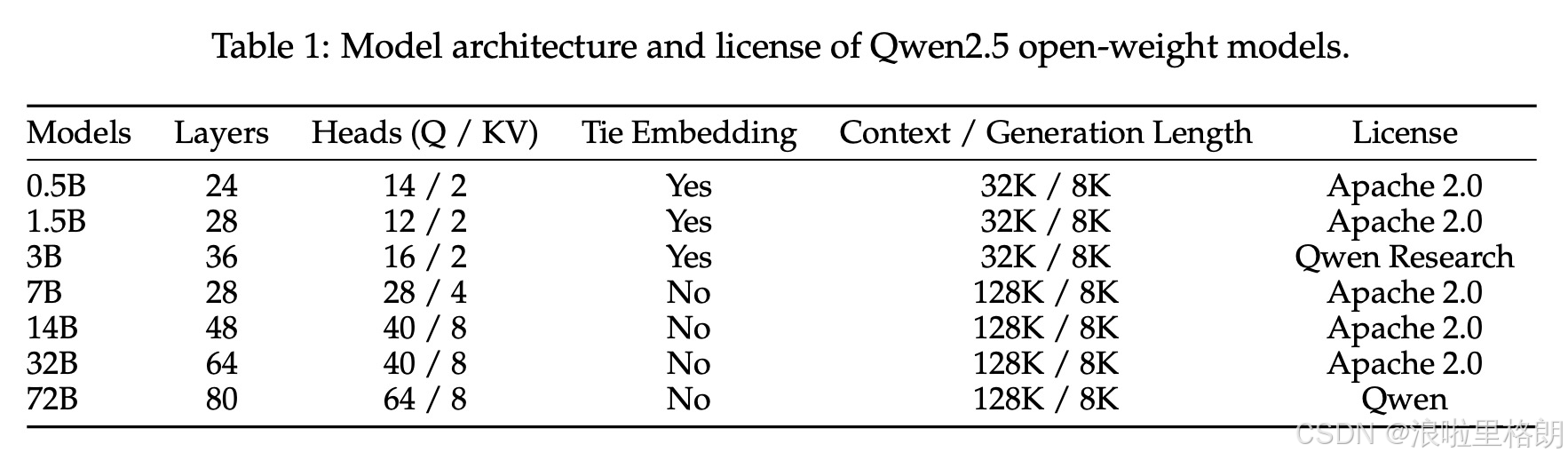
Table 1 展示了Qwen2.5开源模型的架构信息,具体解释如下:
- 模型:代表Qwen2.5系列中不同参数规模的模型,如0.5B、1.5B等,这些模型涵盖了从较小规模到大规模的多种选择,以适应不同的应用场景和资源需求。
- 层数:表示模型中Transformer层的数量。层数越多,模型的复杂度和学习能力可能越强,但也会增加计算成本。不同规模的模型具有不同的层数,例如: 0.5B模型有24层,72B模型有80层 ,反映了模型在结构复杂度上的差异。
- 头数(查询/键值):多头注意力机制中查询头和键值头的数量。多头注意力有助于模型在不同表示子空间中捕捉信息,提高模型对复杂数据的理解能力。例如: 7B模型有28个查询头和4个键值头 。
- 嵌入层共享:表明模型是否共享嵌入层。共享嵌入层可以减少模型参数数量,提高训练效率和泛化能力。0.5B、1.5B和3B模型的嵌入层是共享的,而7B、14B、32B和72B模型不共享嵌入层。
- 上下文/生成长度:上下文长度指模型在处理输入时能够考虑的最大文本长度,生成长度则是模型输出文本的最大长度。Qwen2.5系列模型的上下文长度在32K - 128K之间,生成长度均为8K,这使得模型在处理长文本任务时具有一定的优势。
- 许可证:规定了模型的使用许可条款。不同模型有不同的许可证,如Apache 2.0许可证允许在一定条件下自由使用、修改和分发模型,而Qwen Research许可证可能有其特定的使用限制和要求。
训练
预训练(Pre-Training)
该部分主要介绍了Qwen2.5语言模型的预训练过程,涵盖数据处理、超参数确定以及长上下文训练等关键环节,旨在提升模型的性能和泛化能力。
- 预训练数据
- 数据质量提升:利用Qwen2-Instruct模型进行多维度数据质量评估和筛选,相较于Qwen2有显著改进,能更好地保留高质量数据并过滤低质量样本。整合来自 Qwen2.5-Math 和 Qwen2.5-Coder的训练数据 ,增强模型在数学和编码任务上的能力;同时,借助 Qwen2-72B-Instruct 和 Qwen2Math-72B-Instruct生成高质量合成数据 ,并通过严格过滤确保数据质量。
- 数据混合优化:通过 Qwen2-Instruct模型 对 不同领域数据进行分类和平衡 ,对网络数据中过度代表和代表性不足的领域分别进行下采样和上采样,构建更平衡、信息更丰富的训练数据集。最终将预训练数据集从Qwen2的7万亿token扩展到18万亿token。
- 缩放定律确定超参数:基于Qwen2.5的预训练数据制定 超参数缩放定律 ,通过大量实验研究不同模型架构下最优学习率和批量大小与模型规模、数据规模的关系。利用这些关系预测模型最终损失,比较MoE模型和密集模型的性能,指导MoE模型的超参数配置,以实现与特定密集模型相当的性能。
- 长上下文预训练
- 多数模型训练策略:多数Qwen2.5模型采用 两阶段预训练 方法,先在4096-token上下文长度下训练,最后阶段将上下文长度扩展到32768 token,并使用ABF技术将RoPE基础频率从10,000提高到1,000,000。
- Qwen2.5-Turbo的特殊策略: Qwen2.5-Turbo 在训练过程中采用渐进式上下文长度扩展策略,分 四个阶段 将上下文长度逐步扩展到262,144 token ,每个阶段使用特定比例的不同长度序列进行训练,并将RoPE基础频率设为10,000,000。同时,利用YARN和Dual Chunk Attention(DCA)技术,使Qwen2.5-Turbo能处理长达100万token的序列,其他模型能处理长达131,072 token的序列,且在处理长序列时降低困惑度,保持对短序列的良好性能。
后训练(Post-Training)
Qwen2.5第4章后训练内容丰富,涵盖监督微调、离线强化学习、在线强化学习以及长文本微调多个关键环节。
- 监督微调(SFT)
- 数据构建:构建超100万高质量样本的数据集,覆盖长序列生成、数学、编码、指令遵循等多领域,针对Qwen2不足进行优化。
- 训练策略:模型以32,768令牌序列长度微调两个epoch,学习率从 7 × 1 0 − 6 7×10^{-6} 7×10−6渐降至 7 × 1 0 − 7 7×10^{-7} 7×10−7 ,采用0.1的权重衰减和梯度裁剪(最大值1.0)防止过拟合。
- 任务优化:通过开发长响应数据集、引入思维链数据、多语言协作框架等方法,分别提升模型长序列生成、数学、编码、指令遵循、结构化数据理解、逻辑推理、跨语言转移、鲁棒系统指令和响应过滤等能力。
- 离线强化学习:聚焦数学、编码等难以用奖励模型评估的领域,利用SFT模型 重采样生成正负例 ,构建约150,000训练对,使用在线合并优化器以 7 × 1 0 − 7 7×10^{-7} 7×10−7学习率训练一个epoch,确保训练信号可靠且与人类期望一致。
- 在线强化学习
- 奖励模型训练:依据真实性、有用性等标准标注数据,使用开源数据和专有复杂查询集 训练奖励模型 ,偏好对通过人工和自动标注生成,并 整合DPO 训练数据。
- 模型训练:采用 GRPO 算法,依据奖励模型评估的响应分数方差确定训练顺序,每个查询采样8个响应,以2048的全局批量大小和每集2048个样本进行训练。
- 长上下文微调:为扩展Qwen2.5-Turbo的上下文长度,SFT阶段分两阶段训练,先仅用短指令,再结合长短指令,提升长上下文任务能力并保持短任务性能;RL阶段仅用短指令训练,在提升长上下文任务的同时减少计算成本。
实验结果
Table 2 和 Table 3 是对Qwen2.5与其他模型性能对比的评估结果,展示了不同规模模型在多领域任务中的表现,为理解Qwen2.5的优势与定位提供了关键参考。
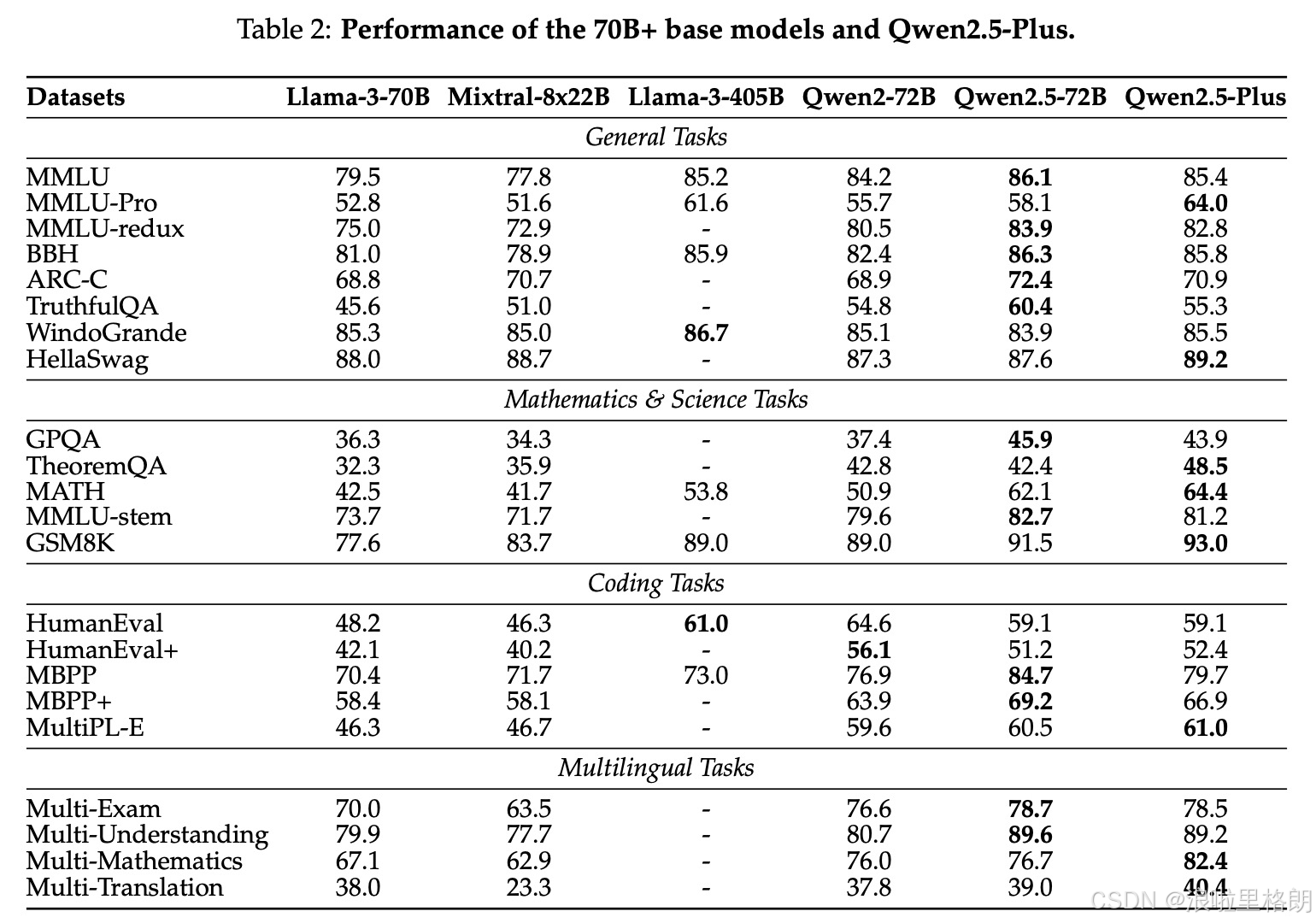
- 表2:70B+基础模型和Qwen2.5-Plus的性能:对比了 Llama-3-70B、Mixtral-8x22B 等模型与 Qwen2.5系列中70B+ 基础模型及Qwen2.5-Plus的性能。
- 在General Tasks、Mathematics & Science Tasks、Coding Tasks、Multilingual Tasks等多领域任务的评估里,Qwen2.5-72B在多数任务上表现出色,成绩与Llama-3-405B相近,但参数仅为其五分之一。
- Qwen2.5-Plus在部分任务上优于Qwen2.5-72B,在Hellaswag、TheoremQA等任务上超越其他基线模型。
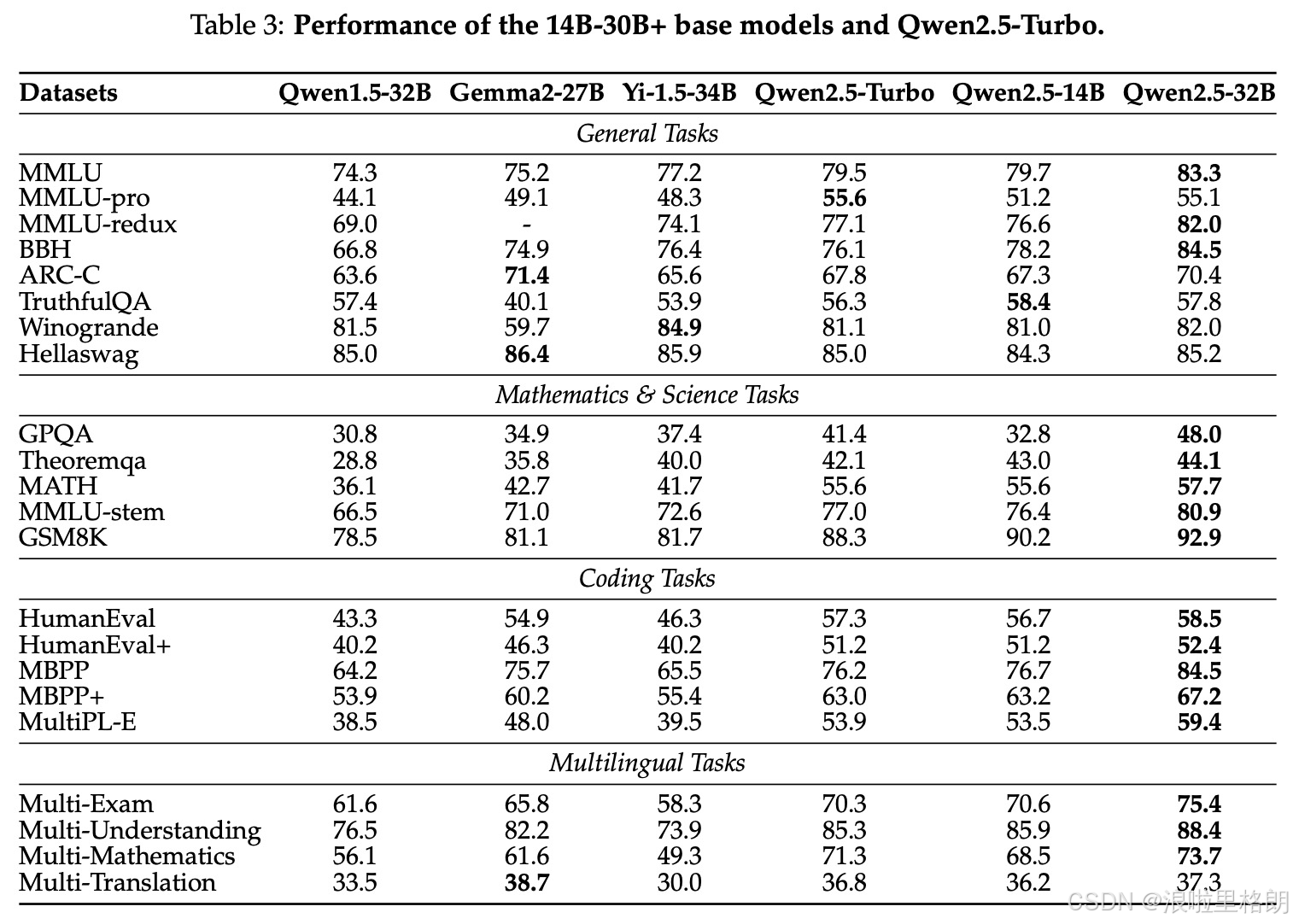
- 表3:14B-30B+基础模型和Qwen2.5-Turbo的性能:比较了 Qwen1.5-32B、Gemma2-27B 等模型与 Qwen2.5-Turbo、Qwen2.5-14B、Qwen2.5-32B 的性能。
- Qwen2.5-14B在各类任务中性能出色,在MMLU和BBH等通用任务上得分突出。
- Qwen2.5-32B在数学和编码等任务上表现卓越,显著超越其前身Qwen1.5-32B。
- Qwen2.5-Turbo训练和推理成本低,在MMLU-Pro等任务上成绩甚至优于Qwen2.5-32B。

















 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









