







 这篇博客介绍了jiebaR在R中的使用,包括四种分词模式、词性标注、关键词提取、simhash计算和快速模式。示例代码详细展示了如何进行分词操作,并提到了jiebaR的优化和自定义设置。
这篇博客介绍了jiebaR在R中的使用,包括四种分词模式、词性标注、关键词提取、simhash计算和快速模式。示例代码详细展示了如何进行分词操作,并提到了jiebaR的优化和自定义设置。
参考于jiebaR中文分词帮助文档,做了个笔记,方便以后学习。这里有官方英文文档,以及jiebaR官网。
#1. 分词
jiebaR提供了四种分词模式,可以通过函数worker()来初始化分词引擎,使用函数segment()进行分词。具体使用?worker查看帮助
简单用法举例说明
text <- '你要明白,这仅仅是一个测试文本'
mixseg <- worker() #使用默认参数,混合模型(MixSegment)
segment(text, mixseg)
#等价于mixseg[text]
#也等价于mixseg <= text
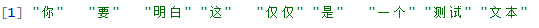
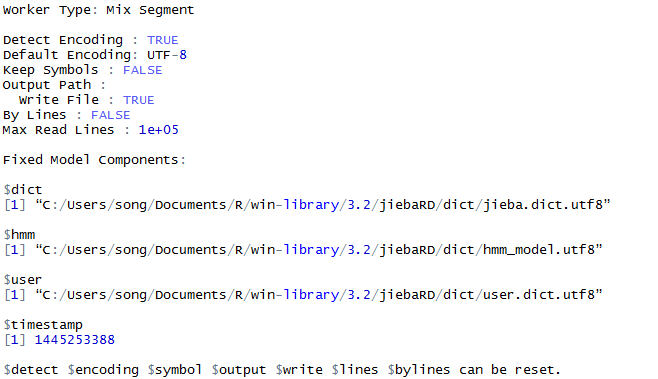
直接输入mixseg命令,可以查看此worker的配置
mixseg
可以通过R语言常用的 $符号重设一些worker的参数设置,如 WorkerName$symbol = T,在输出中保留标点符号。一些
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5215
5215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









