







简介
本系统基于推荐算法给用户实现精准推荐图书。
根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性,然后再基于这些关联性进行推荐,种被称为基于协同过滤的推荐。
本系统使用了三种推荐算法:基于用户的协同过滤算法、基于物品的协同过滤算法、基于机器学习k-means聚类的过滤算法,以及三种算法的混合推荐算法。
主要功能如下图:

二、使用到的技术
开发语言是python3.7,框架是Django3.0,采用的是djanog前后端相结合的技术,后台管理系统是xadmin,数据库是Mysql5.7。
1、Django的MTV架构
所谓MTV就是:数据模型(M)-前端界面(T)-调度控制器(V).
用户在浏览器发起一个请求:通过V对M和T进行连接,用户通过T(界面)对服务器进行访问(发送请求),T把请求传给V(调度),V调用M(数据模型)获取数据,把数据给模板T进行渲染,然后再把渲染后的模板返回给用户。
MTV框架是一种 把业务逻辑、数据、界面显示分离而设计创建的Web应用程序的开发模式。在web开发中应该尽量使代码高内聚低耦合,这样利于代码复用、维护、管理,MTV框架就是这样分层的。
M对应于Model,即数据模型(数据层),用于管理数据库,对数据进行增删改查;
T对应于视图,template(即T),模板,用于管理html文件,呈现给用户的界面;
V对应于控制层,views(即V),视图调度器,用于访问数据层,获取数据,把数据调度给模板进行渲染,把渲染的结果返回给客户端。
MTV框架的大体流程是:
1、客户端发起请求,路由对客户发起的请求进行统一处理和分发给控制层;
2、控制层获取请求,访问数据层;
3、数据层对数据进行增删改查,把数据返回给控制层;
4、控制层获取数据,把数据调度给视图(模板);
5、视图(模板)对数据进行渲染,形成html文件返回给控制层;
6、控制层把渲染后的视图(模板)返回给客户端。
三、开发流程
1、环境搭建:创建虚拟环境、创建数据库
2、创建数据库模型:用户表、图书标签表、用户选择类型表(用户解决推荐算法冷启动问题)、借书清单表、购书清单表、评分表、收藏表、点赞表、评论表、推荐反馈表。然后数据迁移,把表映射到数据库中。
3、爬取数据,然后把数据经过预处理存放到数据库中。
4、编写用户界面框架,完成各种功能点击响应事件
5、编写后台管理文件,管理数据。
6、系统测试,检验完成的功能。
具体开发过程可以查看【开发文档.pdf】
四、主要功能




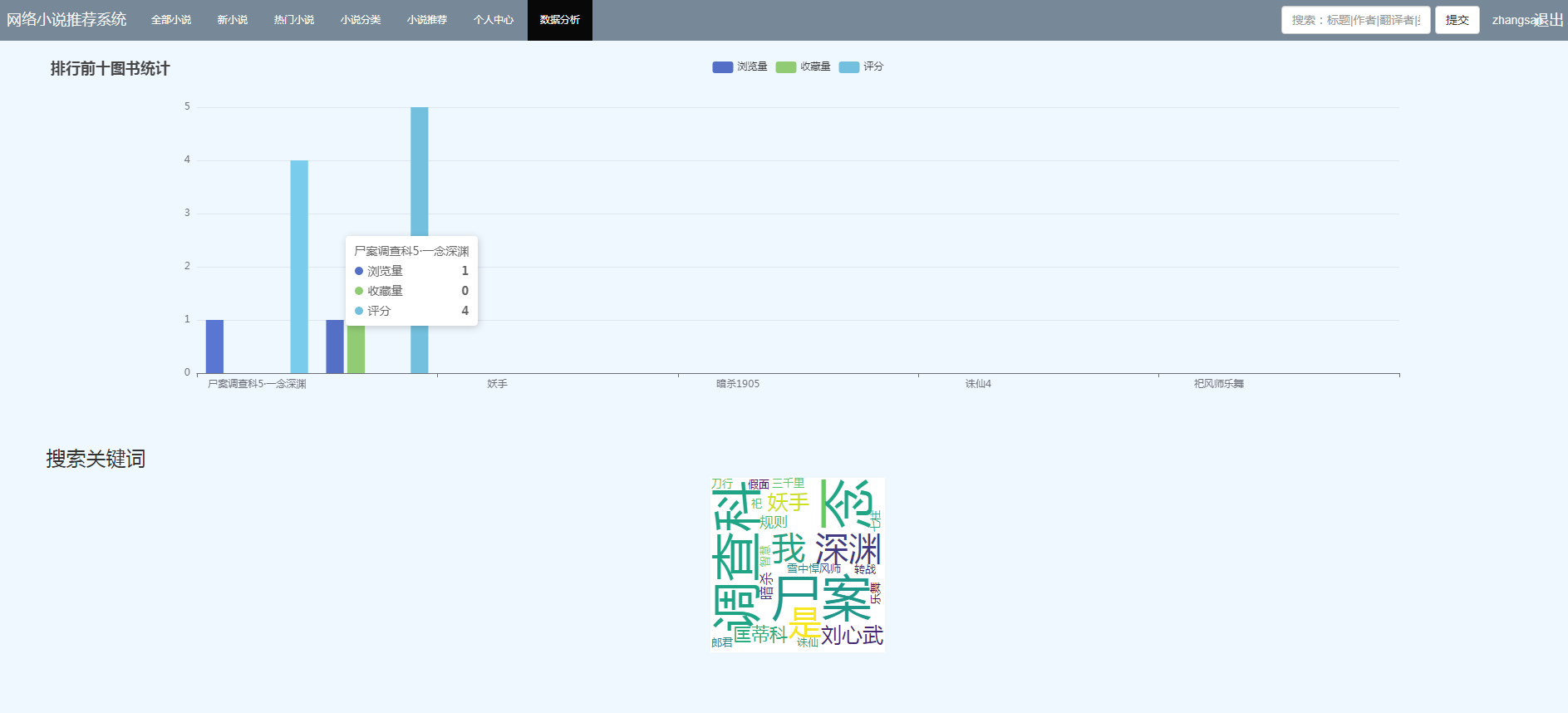

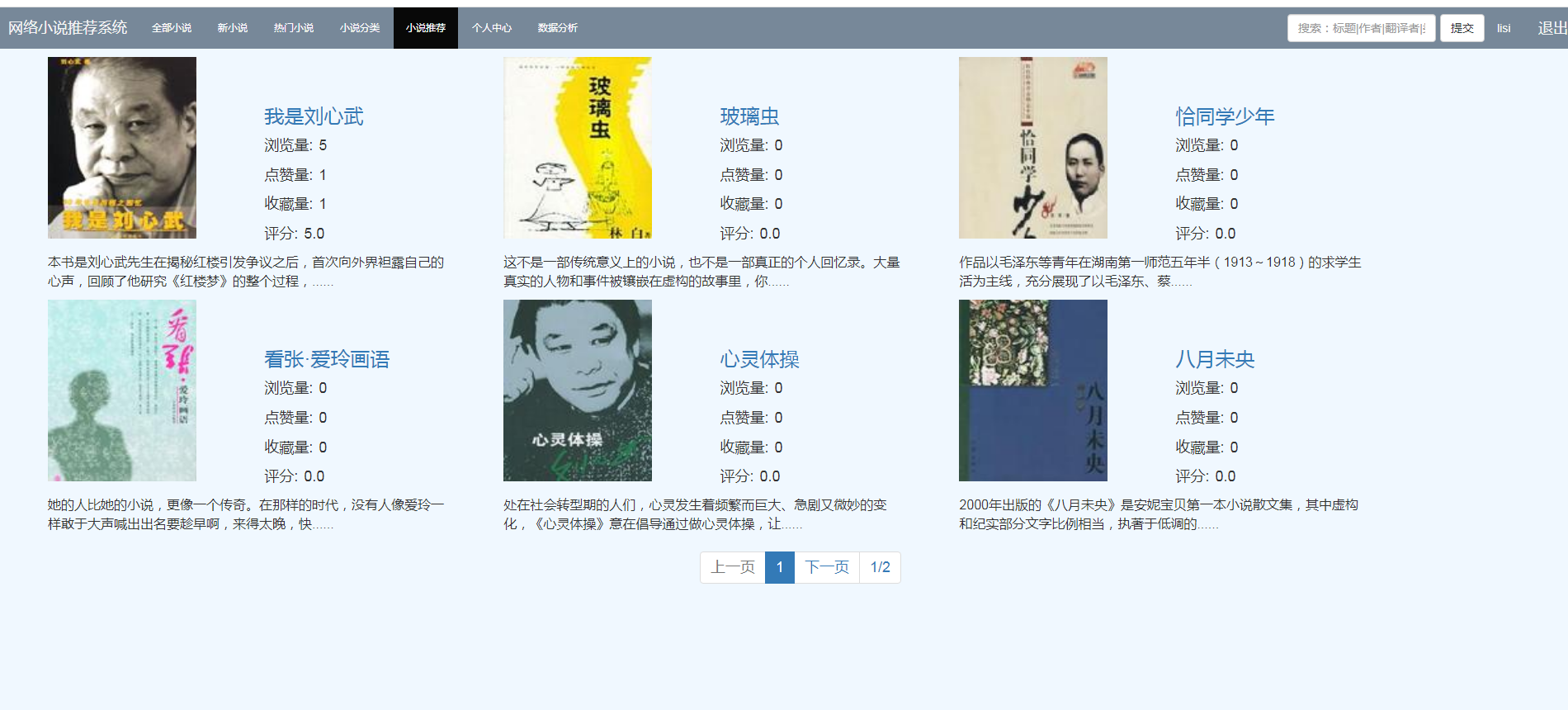

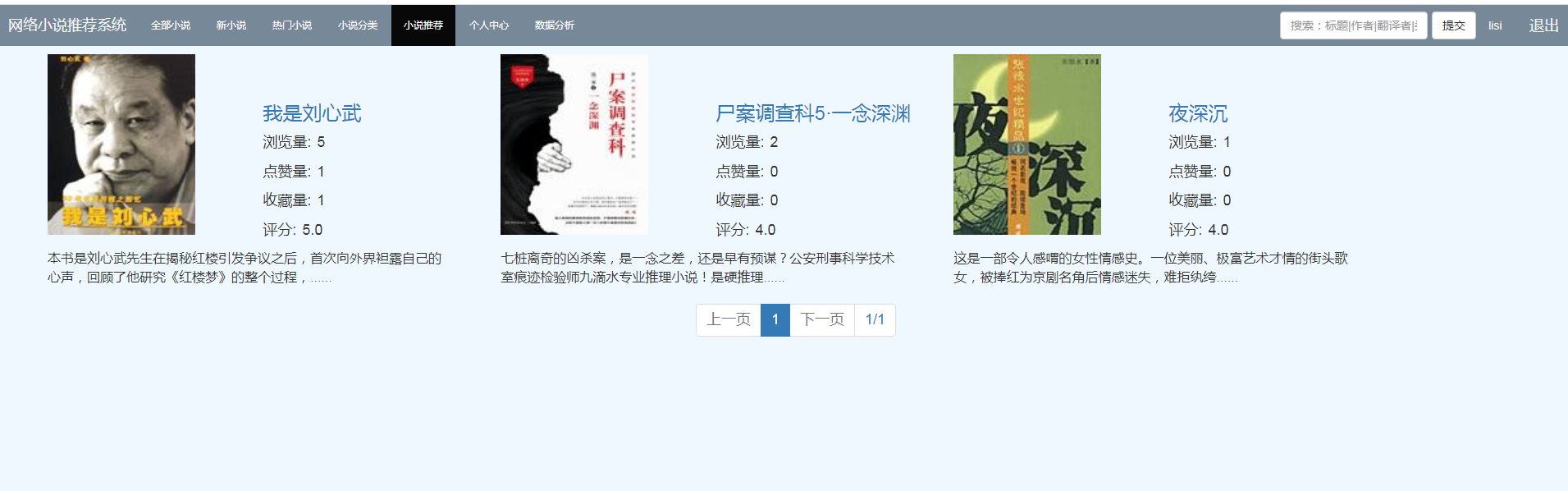
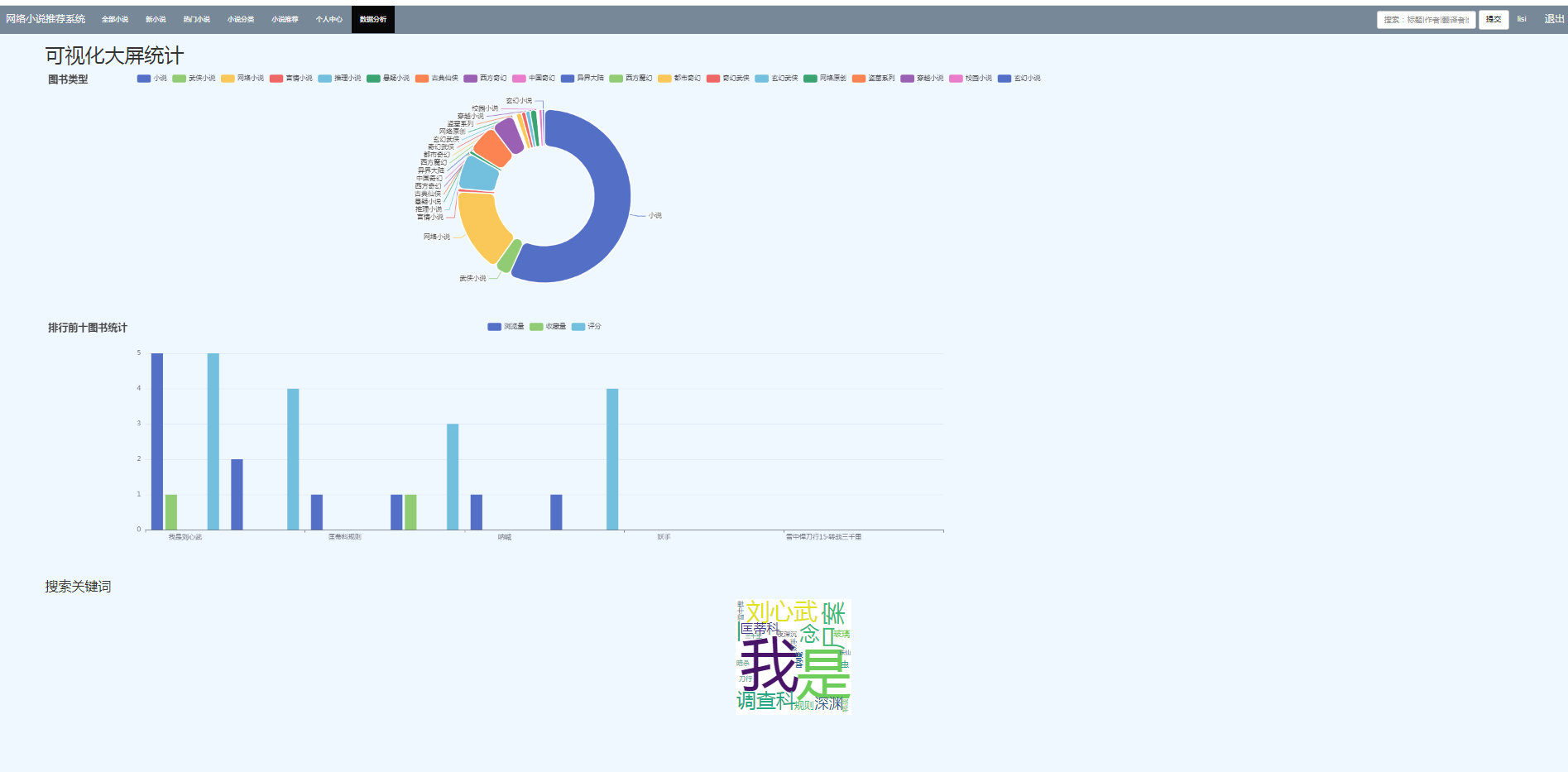


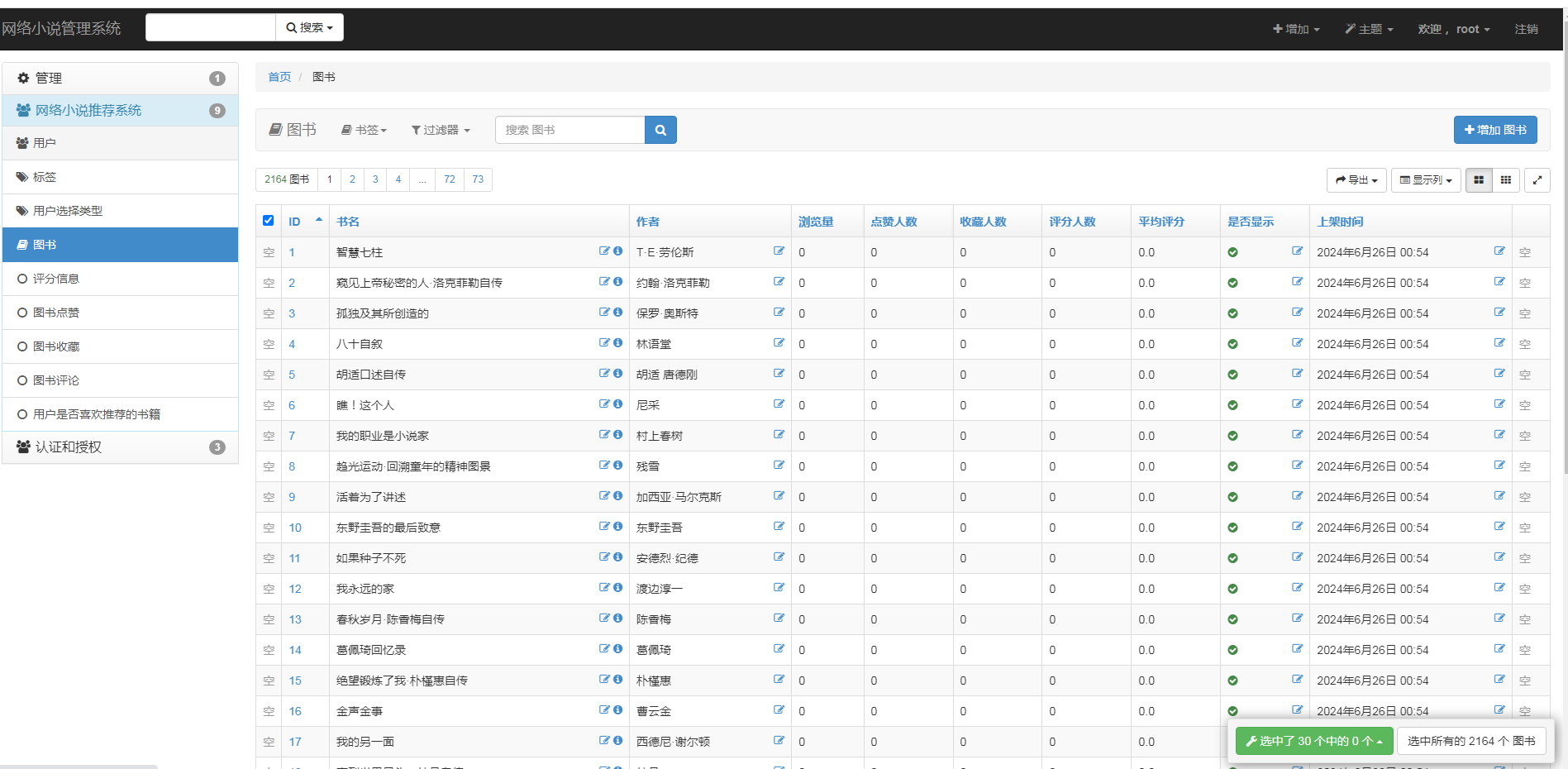
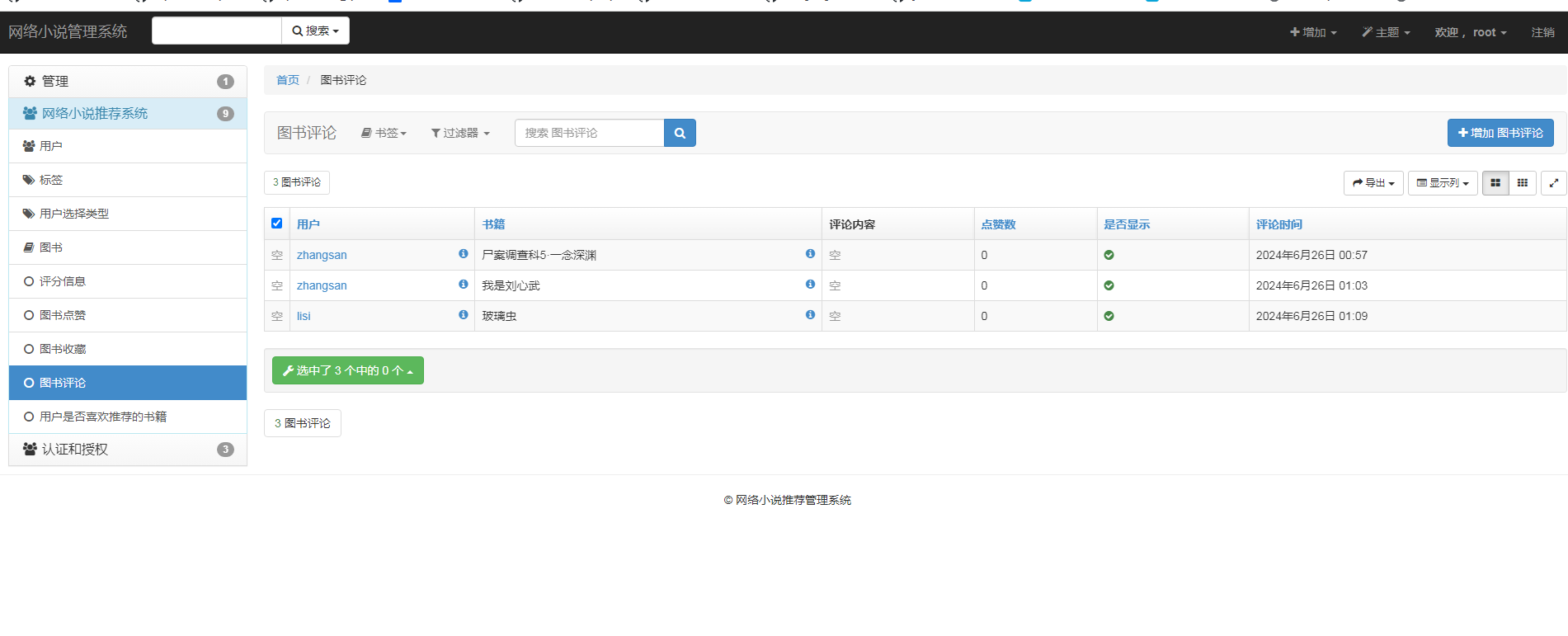


五、算法说明
1、基于用户协同过滤推荐算法
基于用户的协同过滤算法:就是把和你相似的用户喜欢的东西推荐给你。
协同过滤:利用用户的群体行为来计算用户的相关性。计算用户相关性的时候我们就是通过对比他们对相同物品打分的相关度来计算的
举例:
--------+--------+--------+--------+--------+
| X | Y | Z | R |
--------+--------+--------+--------+--------+
a | 5 | 4 | 1 | 5 |
--------+--------+--------+--------+--------+
b | 4 | 3 | 1 | ? |
--------+--------+--------+--------+--------+
c | 2 | 2 | 5 | 1 |
--------+--------+--------+--------+--------+
a用户给X物品打了5分,给Y打了4分,给Z打了1分
b用户给X物品打了4分,给Y打了3分,给Z打了1分
c用户给X物品打了2分,给Y打了2分,给Z打了5分
那么很容易看到a用户和b用户非常相似,但是b用户没有看过R物品,那么我们就可以把和b用户很相似的a用户打分很高的R物品推荐给b用户,这就是基于用户的协同过滤。
相关性
基于用户的协同过滤需要比较用户间的相关性,那么如何计算这个相关性呢?
我们可以利用两个用户对于相同物品的评分来计算相关性。
对于a,b用户而言,他们都对XYZ物品进行了评价,那么,a我们可以表示为(5,4,1),b可以表示为(4,3,1),经典的算法是把他们看作是两个向量,并计算两个向量间的夹角,或者说计算向量夹角的cosine值来比较,于是a和b的相关性为:
这个值介于-1到1之间,越大,说明相关性越大。
皮尔逊相关系数
到这里似乎cosine还是不错的,但是考虑这么个问题,用于用户间的差异,d用户可能喜欢打高分,e用户喜欢打低分,f用户喜欢乱打分。
--------+--------+--------+--------+
| X | Y | Z |
--------+--------+--------+--------+
d | 4 | 4 | 5 |
--------+--------+--------+--------+
e | 1 | 1 | 2 |
--------+--------+--------+--------+
f | 4 | 1 | 5 |
--------+--------+--------+--------+
很显然用户d和e对于作品评价的趋势是一样的,所以应该认为d和e更相似,但是用cosine计算出来的只能是d和f更相似。于是就有皮尔逊相关系数(pearson correlation coefficient)。
pearson其实做的事情就是先把两个向量都减去他们的平均值,然后再计算cosine值。
等价公式:
其中E是数学期望,N表示变量取值的个数。
2、基于物品协同过滤推荐算法
2.1、基于⽤户的协同过滤算法(UserCF)
该算法利⽤⽤户之间的相似性来推荐⽤户感兴趣的信息,个⼈通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的⽬的进⽽帮助别⼈筛选信息,回应不⼀定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。
但两个问题,⼀个是稀疏性,即在系统使⽤初期由于系统资源还未获得⾜够多的评价,很难利⽤这些评价来发现相似的⽤户。
另⼀个是可扩展性,随着系统⽤户和资源的增多,系统的性能会越来越差。
2.2、基于物品的协同过滤算法(ItemCF)
内容过滤根据信息资源与⽤户兴趣的相似性来推荐商品,通过计算⽤户兴趣模型和商品特征向量之间的向量相似性,主动将相似度⾼的商品发送给该模型的客户。
由于每个客户都独⽴操作,拥有独⽴的特征向量,不需要考虑别的⽤户的兴趣,不存在评价级别多少的问题,能推荐新的项⽬或者是冷门的项⽬。
这些优点使得基于内容过滤的推荐系统不受冷启动和稀疏问题的影响。
2.3、算法核心
通过分析用户行为记录(评分、购买、点击、浏览等行为)来计算两个物品的相似度,同时喜欢物品A和物品B的用户数越多,就认为物品A和物品B越相似。
2.4、流程
1.构建⽤户–>物品的对应表
2.构建物品与物品的关系矩阵(同现矩阵)
3.通过求余弦向量夹角计算物品之间的相似度,即计算相似矩阵
4.根据⽤户的历史记录,给⽤户推荐物品
2.5、构建用户与物品的对应关系表
如下表,⾏表⽰⽤户,列表⽰物品(电影),数字表⽰⽤户喜欢该物品的程度(评分)
| 用户\电影 | 唐伯虎点秋香 | 逃学威龙1 | 追龙 | 他人笑我太疯癫 | 喜欢你 | 暗战 |
| A | 5 | 1 | 2 | |||
| B | 4 | 2 | 3.5 | |||
| C | 2 | 4 | ||||
| D | 4 | 3 | ||||
| E | 4 | 3 |
2.6、构建物品与物品的关系矩阵(共现矩阵)
共现矩阵C表⽰同时喜欢两个物品的⽤户数,是根据⽤户物品对应关系表计算出来的。
如根据上⾯的⽤户物品关系表可以计算出如下的共现矩阵C:
| 电影\电影 | 唐伯虎点秋香 | 逃学威龙1 | 追龙 | 他人笑我太疯癫 | 喜欢你 | 暗战 |
| 唐伯虎点秋香 | 1 | 1 | 1 | 1 | ||
| 逃学威龙1 | 1 | 1 | 2 | |||
| 追龙 | 1 | 1 | ||||
| 他人笑我太疯癫 | 2 | |||||
| 喜欢你 | 1 | 2 | ||||
| 暗战 | 1 | 2 |
2.7、计算相似矩阵
两个物品之间的相似度如何计算?
设|N(i)|表⽰喜欢物品i的⽤户数,|N(i)⋂N(j)|表⽰同时喜欢物品i,j的⽤户数,则物品i与物品j的相似度为:
利用公式计算物品之间的余弦相似矩阵如下:
| 电影\电影 | 唐伯虎点秋香 | 逃学威龙1 | 追龙 | 他人笑我太疯癫 | 喜欢你 | 暗战 |
| 唐伯虎点秋香 | 0.41 | 0.7 | 0.5 | 0.5 | ||
| 逃学威龙1 | 0.41 | 0.58 | 0.82 | |||
| 追龙 | 0.71 | 0.58 | ||||
| 他人笑我太疯癫 | 0.82 | |||||
| 喜欢你 | 0.5 | 1.0 | ||||
| 暗战 | 0.5 | 1.0 |
2.8、给用户推荐物品
根据⽤户的历史记录,给⽤户推荐物品。
最终推荐的是什么物品,是由预测兴趣度决定的。
物品j预测兴趣度=⽤户喜欢的物品i的兴趣度×物品i和物品j的相似度
例如:A⽤户喜欢唐伯虎点秋香,逃学威龙1,追龙 ,兴趣度分别为5,1,2
在用户A的评分电影列表中只有唐伯虎点秋香与喜欢你有相似度,推荐喜欢你的预测兴趣度=5 x 0.5 = 2.5
在用户A的评分电影列表中只有唐伯虎点秋香与暗战有相似度,推荐暗战的预测兴趣度=5 x 0.5 = 2.5
在用户A的评分电影列表中只有逃学威龙1与他人笑我太疯癫有相似度,推荐他人笑我太疯癫的预测兴趣度=1 x 0.82 =0.82
3、基于机器学习K-means聚类推荐算法
原理:
从数据库中
1、首先获取书籍类别
2、获取用户注册时勾选喜欢的类别,勾选的为1,否则为0,得到一个样本数据
例:[1,0,1,0,0,...],[1,1,1,0,1,...],[0,0,1,0,0,...],
3、使用k-mean算法把用户分成6类【用户模型】
4、获取6类的【用户模型】的质心,比如[1,0,1,0,0,...]
把为1的类别找出来,然后获取该类别排行前3的书籍,组成一个推荐列表推荐给用户
5、类别书籍排行按收藏量来排序
6、用户购买书籍行为会动态更新样本数据
六、程序文件说明
book是子应用名称,migrations是数据迁移文件,把数据模型映射到数据库中,templatetags是定义界面模板语法,__init__.py是导包文件,adminx.py存放的是后台管理代码,apps.py是子应用说明,forms.py是登录注册表单定义,models.py是数据模型,test.py是测试文件,urls.py是路由表,views.py是控制层调度器。
book_manager是项目应用管理起始文件夹,settings.py是项目数据库,静态文件等配置,urls.py是总路由表。
media保存的是媒体文件。
static保存的是界面的静态文件:css,html,js,图片等。
template保存的是前端界面模板代码。
book-k-mean.dat是k-means聚类后的模型。
manage.py是项目启动管理器。
recommend_books.py是推荐算法代码。
requirements.txt保存的是第三方库文件。
spider_get_data.py是爬虫代码。
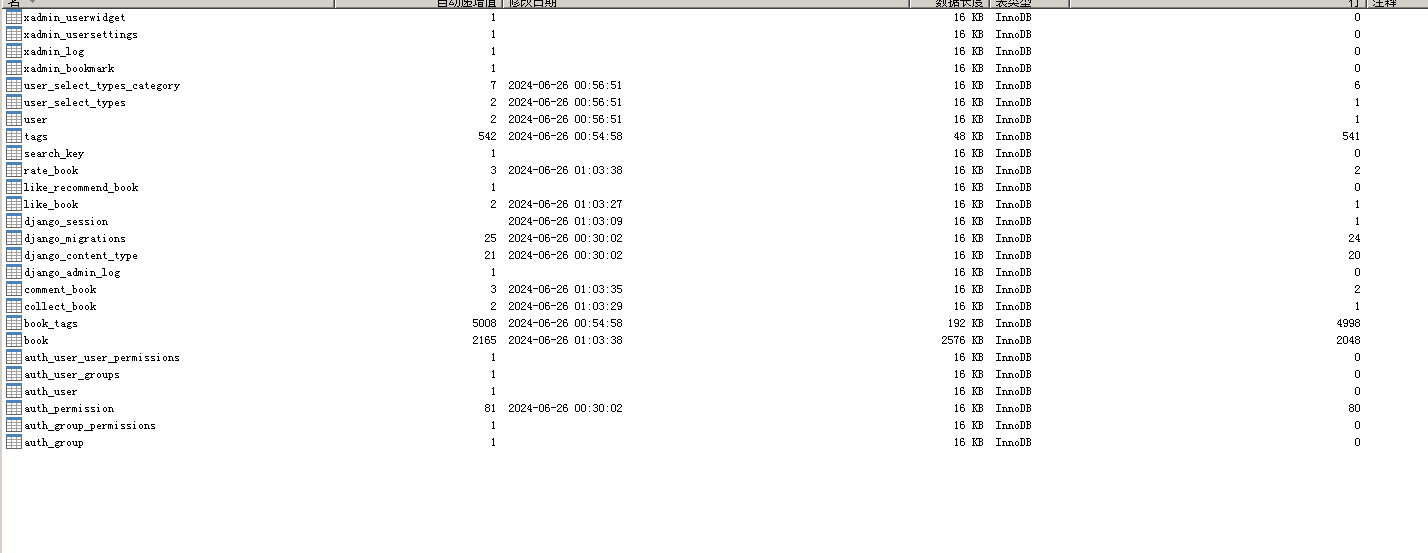
七、数据库表说明
数据库表如下:
auth_group、auth_group_permissions、auth_permissions是后台管理的组、权限表。
auth_user、auth_user_group、auth_user_groups、auth_user_user_permissions是后台管理用户数据表。
book是图书表。
book_tags是图书标签表。
borrow_list是图书借阅表。
collect_book是图书收藏表。
comment_book是图书评论表。
django_admin_log是原始后台管理日志表。
django_content_type是django应用内容表。
django_migrations是数据迁移文件表。
django_session是django缓存表。
like_book是图书点赞表。
like_recommend_book是图书推荐反馈表。
purchase_list是购物车表
rate_book是评分表。
tags是图书标签表。
user是用户表。
user_select_types是用户注册时选择喜欢的图书类型表。
user_select_types_category是一个多对多表,存放的是图书标签id与user_select_types表id的对应关系。
xadmin_bookmark是是后台管理的标签表。
xadmin_log是后台管理操作日志表。
xadmin_usersettings是后台管理用户设置表。
xadmin_userwidget是后台管理小组件表。
















 831
831











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











