







温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python知识图谱中华古诗词可视化
摘要:本文综述了利用Python技术实现中华古诗词知识图谱可视化的研究现状、主要技术与应用案例。中华古诗词作为中华民族的文化瑰宝,蕴含着丰富的历史、文化和情感内涵。Python作为一种功能强大且易于使用的编程语言,在文本处理、数据分析和可视化等方面具有显著优势,为古诗词相关研究提供了有力的技术支持。本文阐述了知识图谱构建、可视化技术、情感分析、智能问答系统以及AI大模型自动写诗等研究方向的发展现状,分析了各研究方向的关键技术与应用成果,并讨论了当前研究面临的挑战与未来发展趋势。
关键词:Python;知识图谱;中华古诗词;可视化;情感分析;智能问答系统;AI大模型自动写诗
一、引言
中华古诗词作为中华民族的文化瑰宝,蕴含着丰富的历史、文化和情感内涵。随着信息技术的发展,如何借助现代技术手段对古诗词进行数字化处理与传承,成为了一个重要的研究课题。Python作为一种功能强大且易于使用的编程语言,在文本处理、数据分析和可视化等方面具有显著优势,为古诗词相关研究提供了有力的技术支持。通过构建中华古诗词知识图谱并将其可视化,可以直观地展示诗人、诗作、朝代、类别等实体之间的关系,帮助研究人员和爱好者更深入地理解和探索古诗词的结构和内涵。
二、文献综述
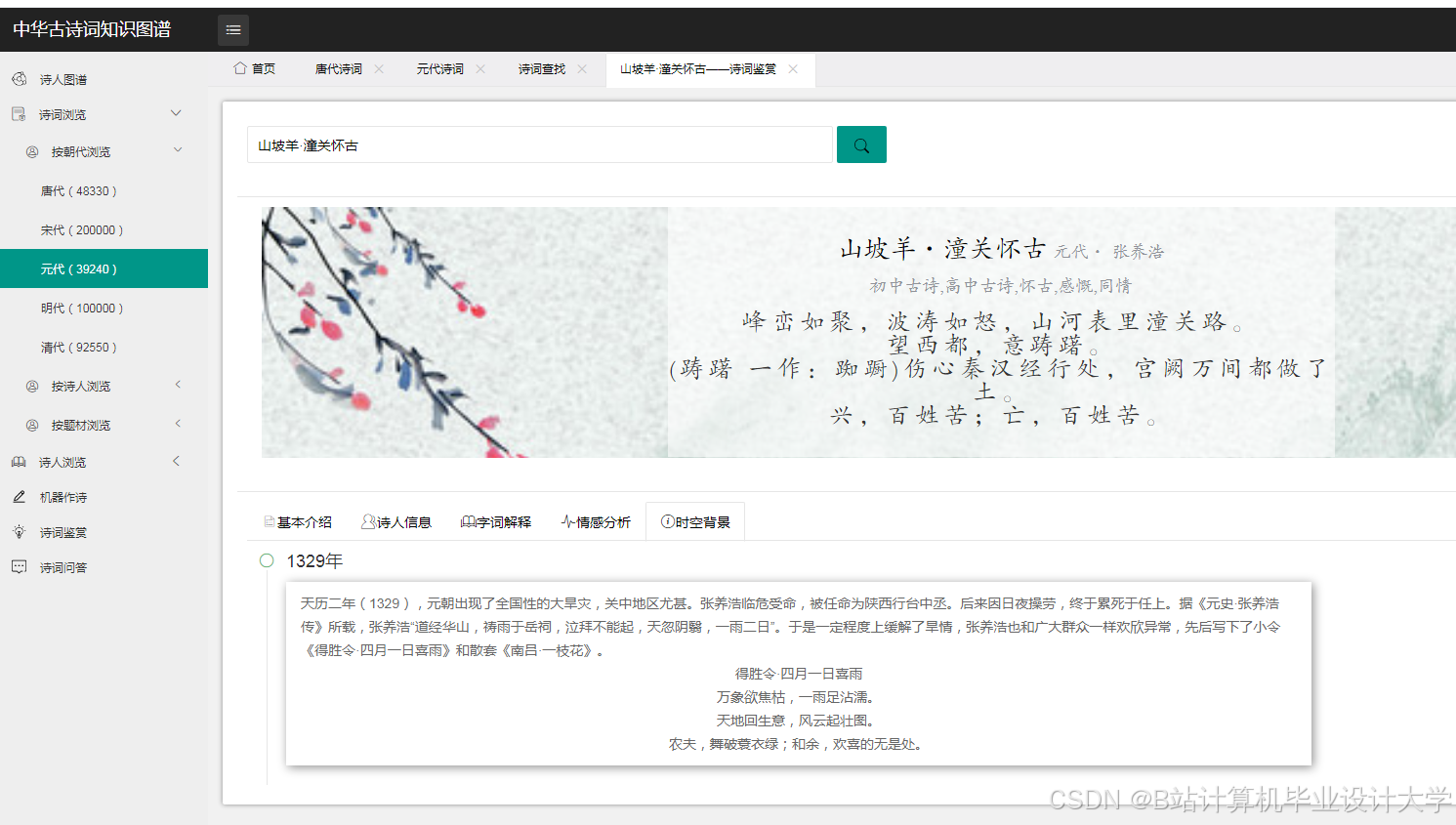
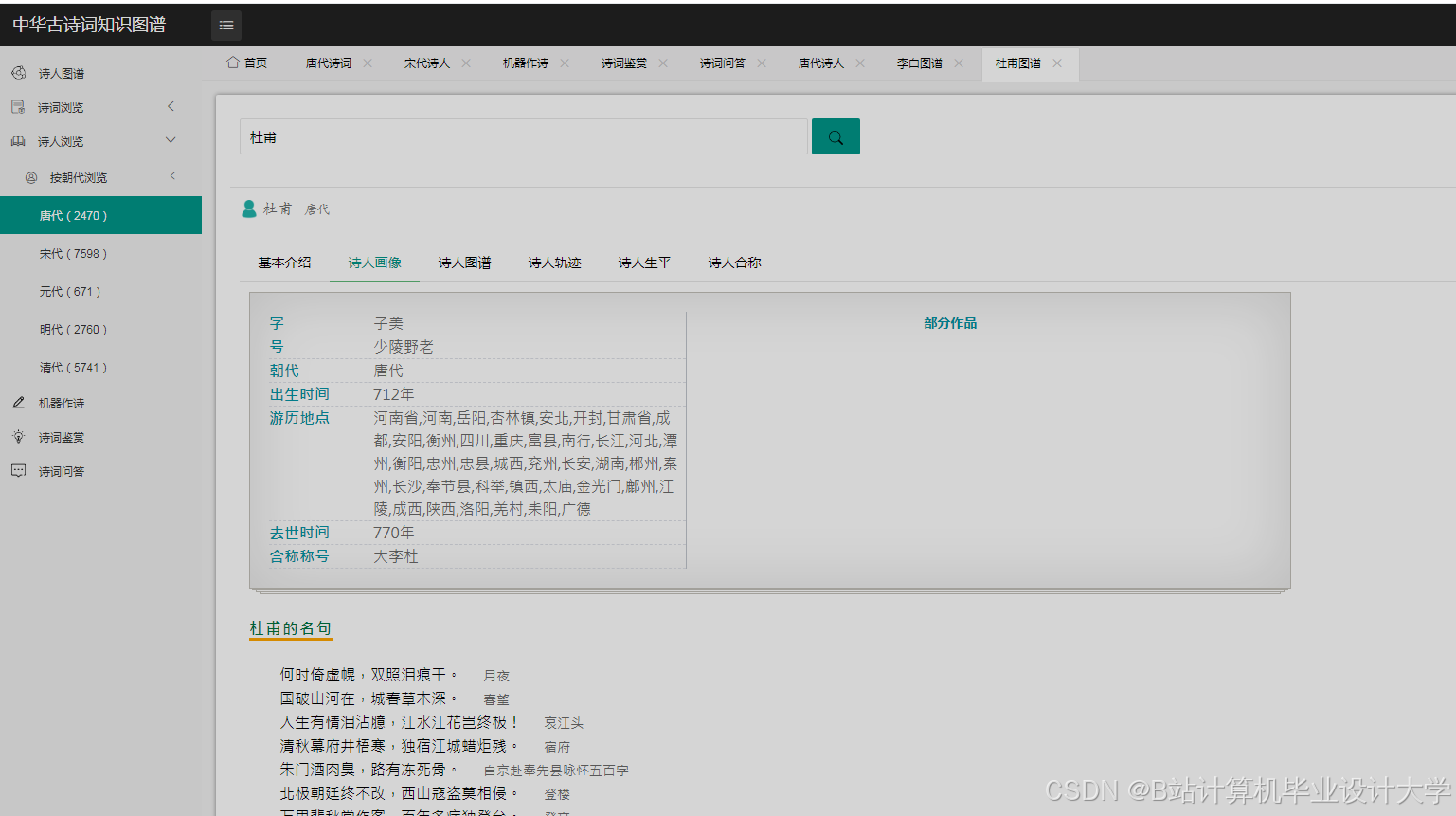
(一)知识图谱构建
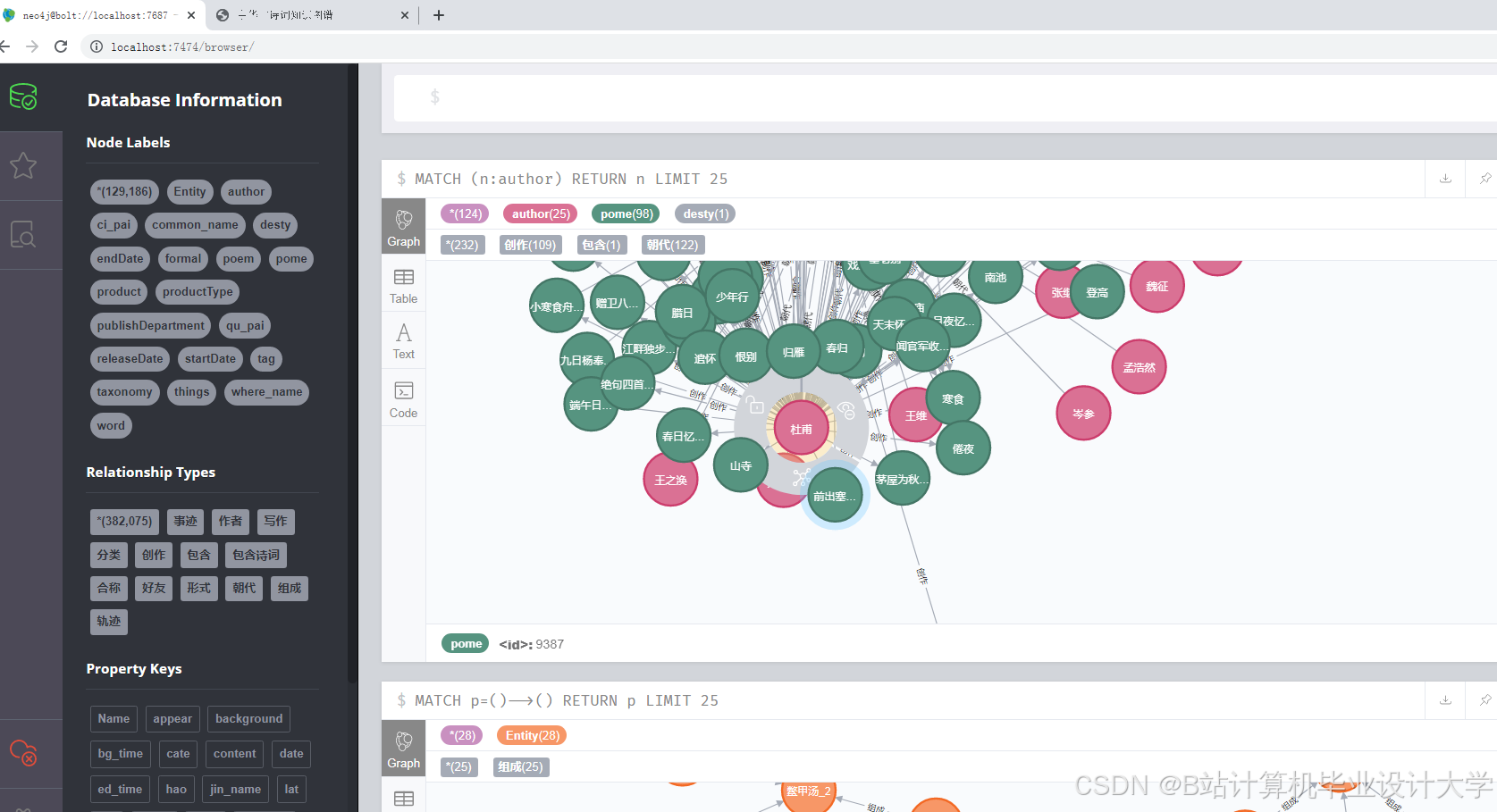
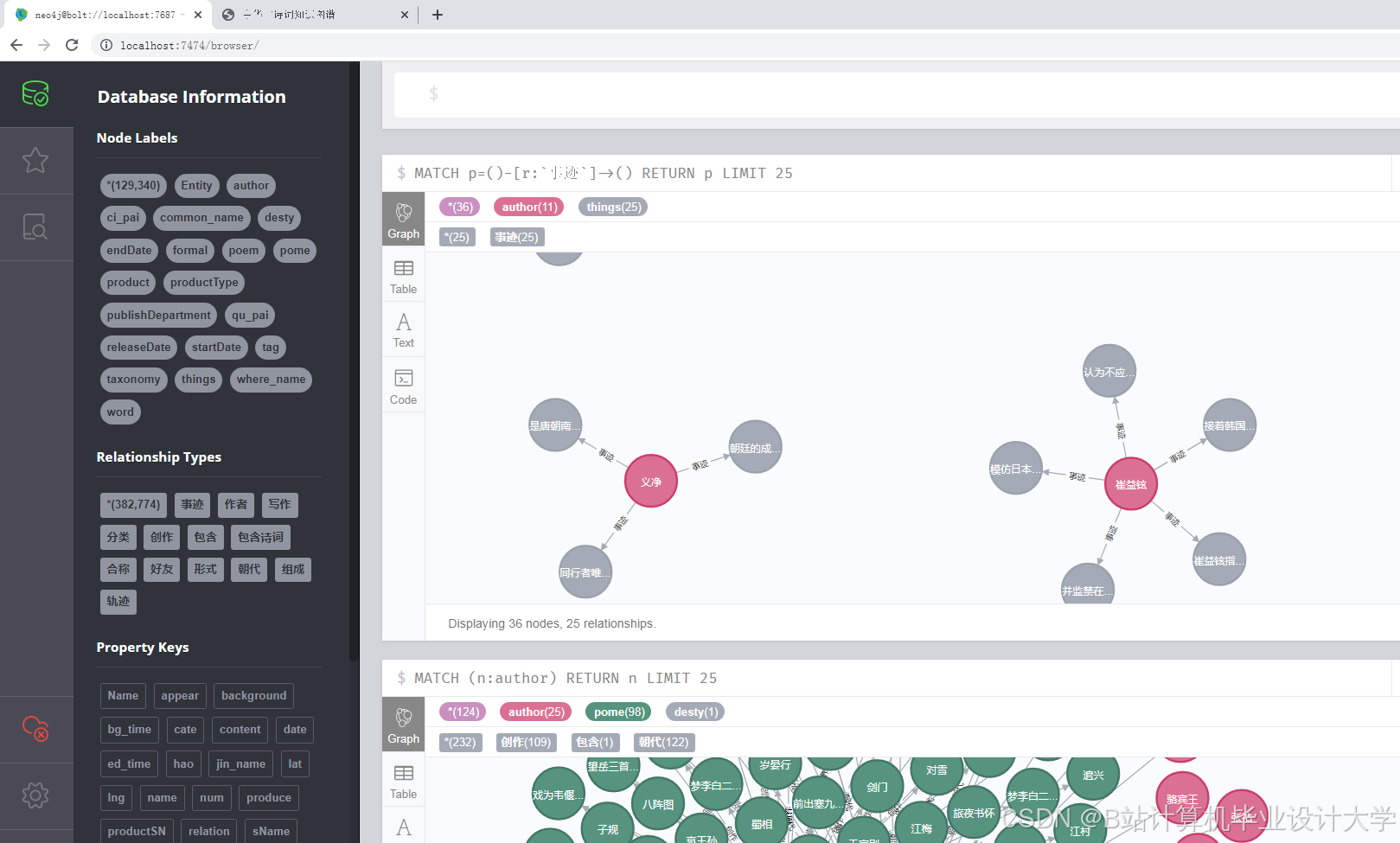
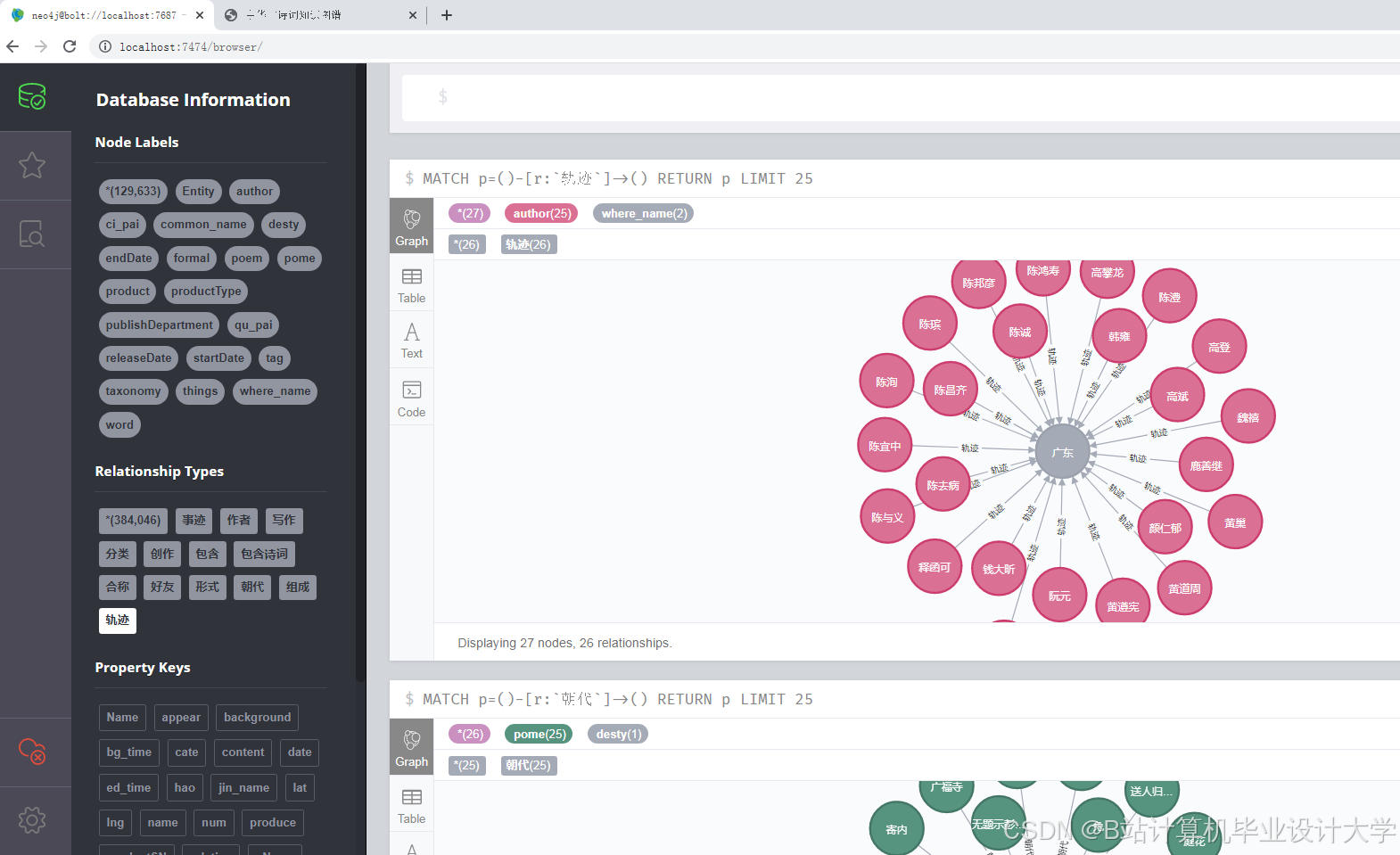
近年来,国内学者在古诗词知识图谱构建方面取得了一定进展。一些研究利用自然语言处理技术对古诗词进行分词、词性标注、实体识别等处理,提取出诗词中的关键信息,进而构建知识图谱。例如,有研究基于预处理后的数据,利用Neo4j等图数据库构建古诗词的知识图谱,图谱中的节点包括诗人、诗作、朝代、类别等,边表示节点之间的关系,如诗人创作诗作、诗作属于某个朝代等。国外在文本处理和知识图谱构建方面的研究起步较早,技术较为成熟,虽然国外在中华古诗词方面的研究相对较少,但其在文本处理和可视化方面的技术积累为国内研究提供了有益的借鉴。
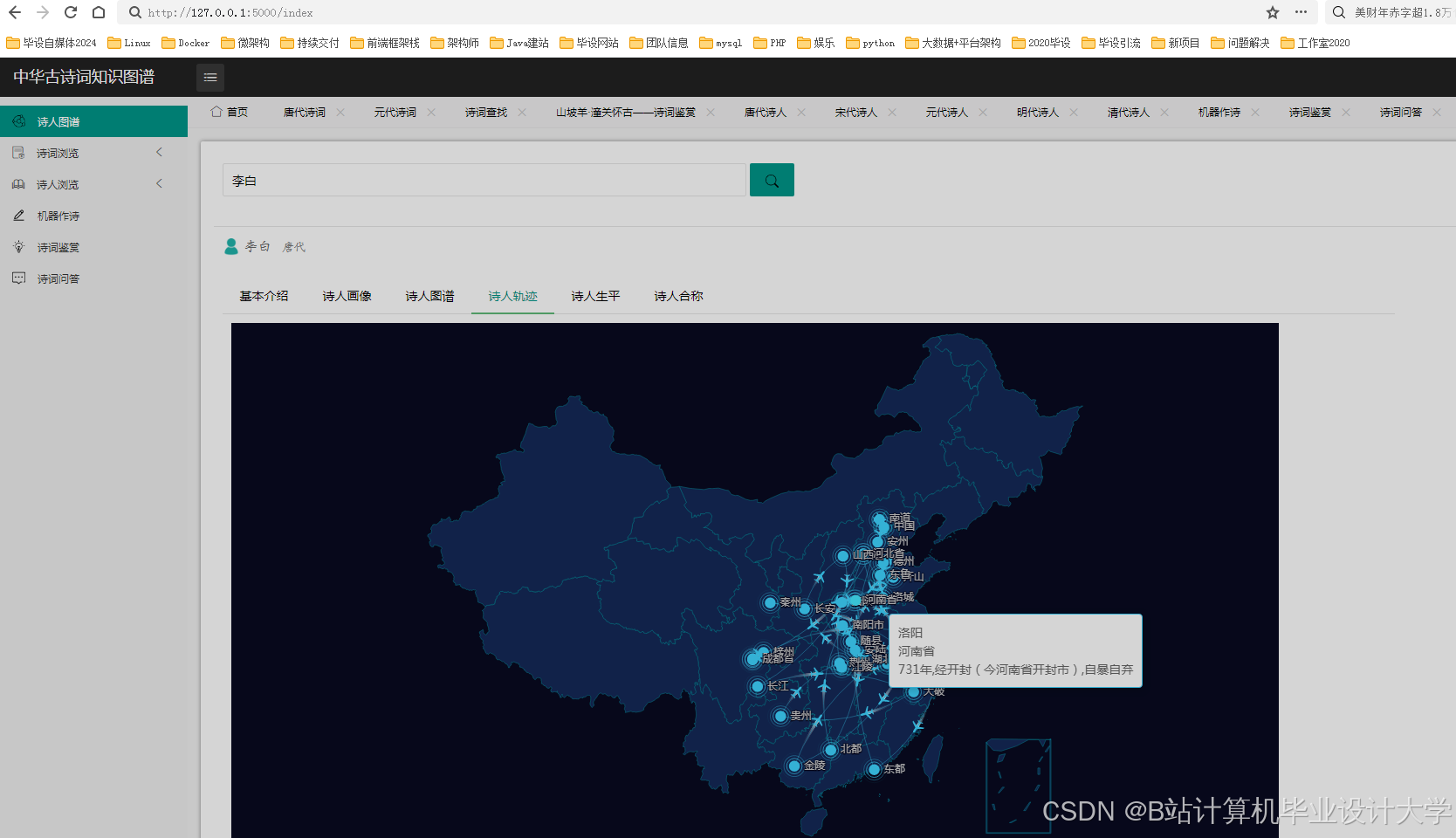
(二)可视化技术
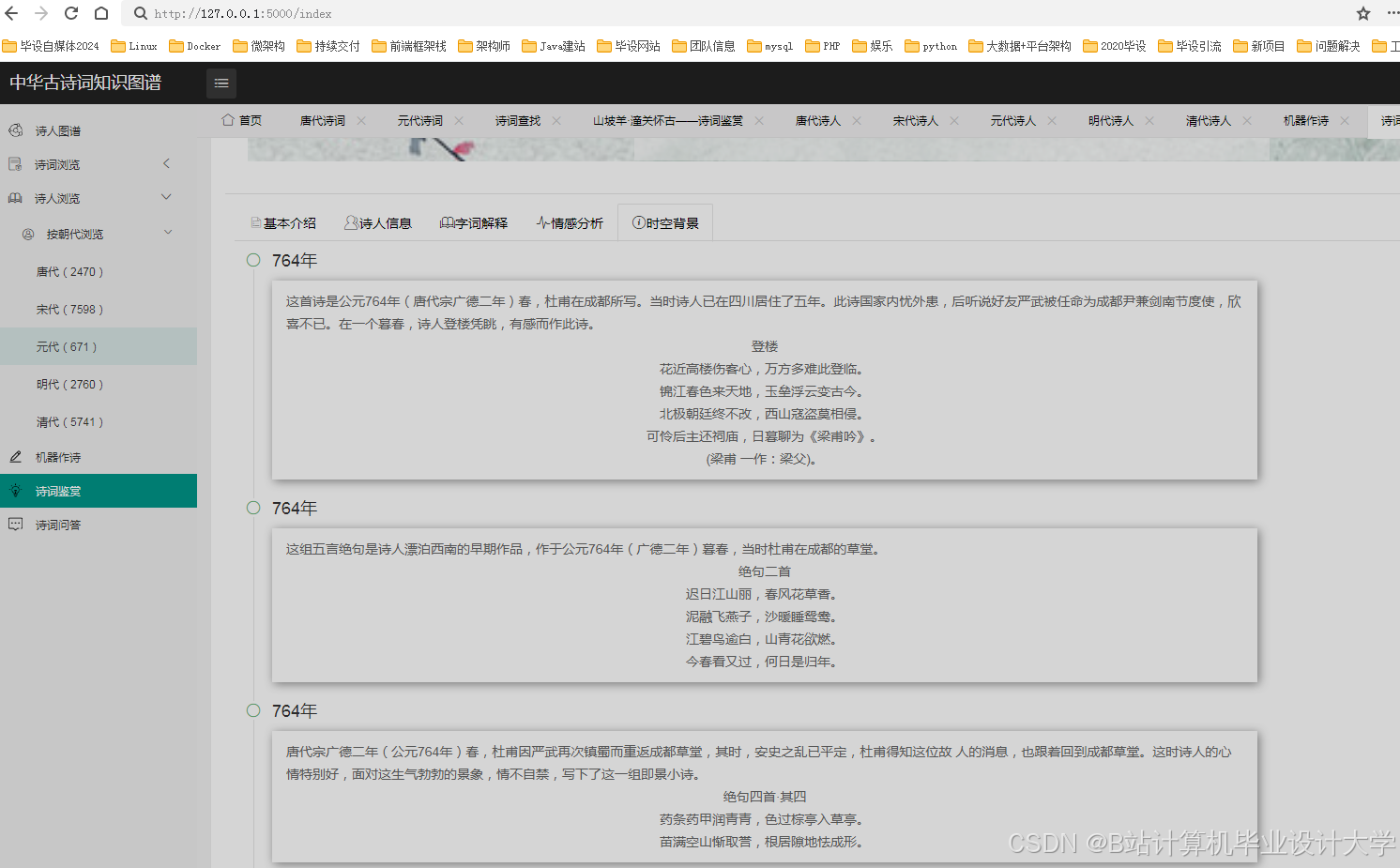
在知识图谱可视化的研究中,利用D3.js、ECharts等前端可视化库,将知识图谱以直观、交互式的方式展示出来,用户可以通过点击节点或边,查看相关诗人或诗作的信息,深入了解古诗词的结构和关系。这种可视化方式不仅有助于研究人员和爱好者更方便地查询和浏览古诗词信息,还能揭示诗人与诗作之间的关联,为古诗词的研究和教学提供了有力的支持。
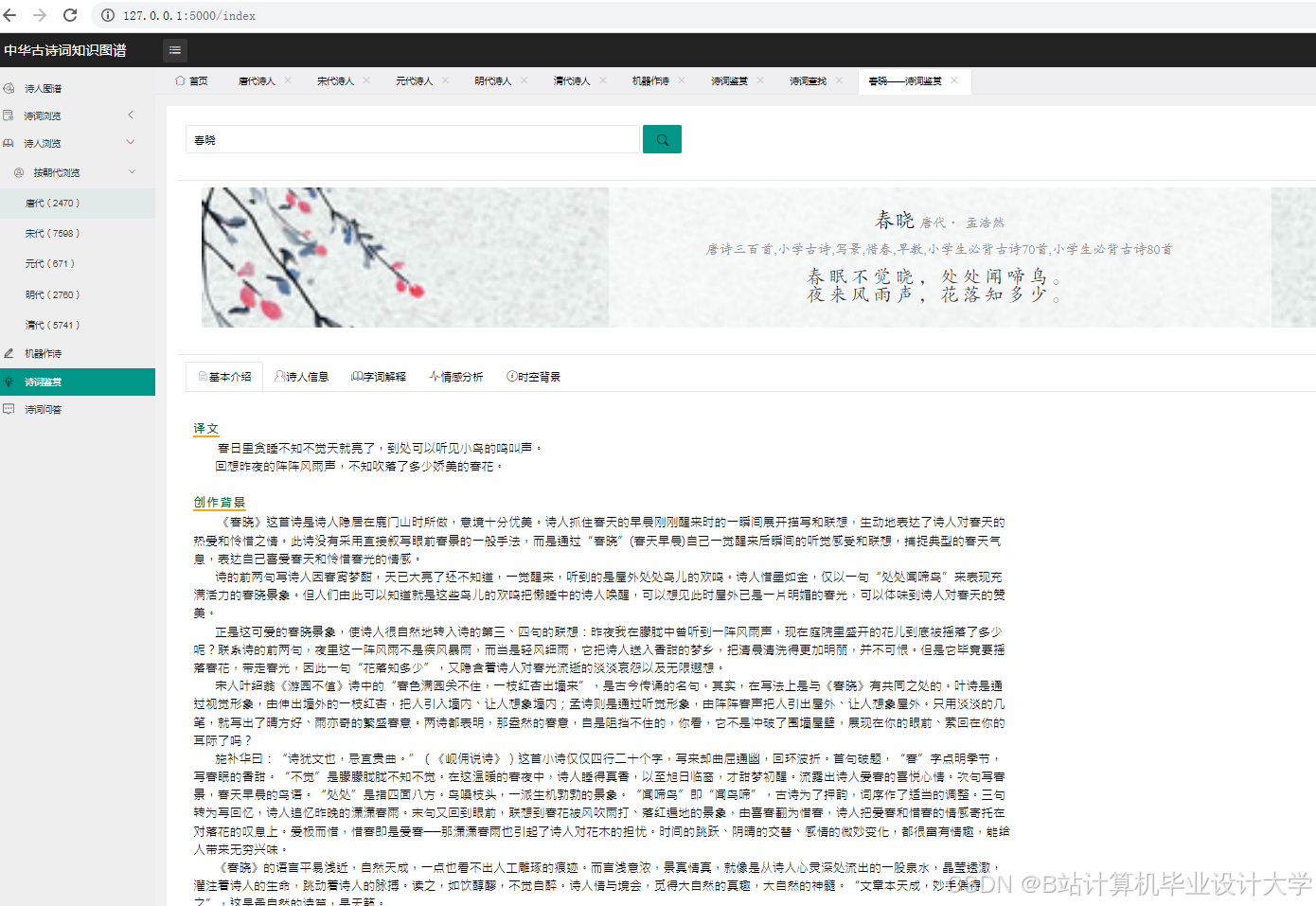
(三)情感分析
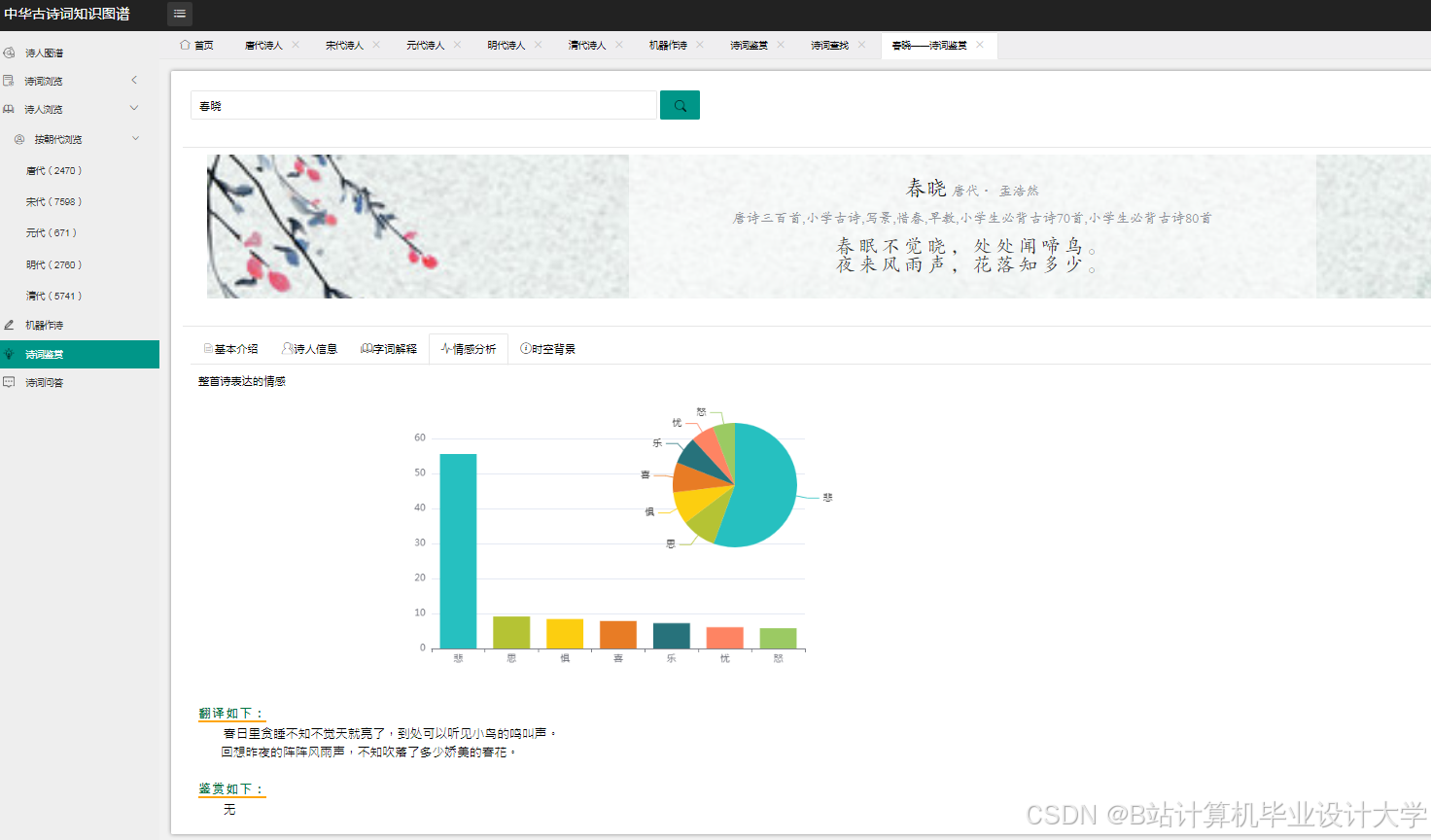
国内学者在古诗词情感分析方面进行了大量研究。一些研究利用自然语言处理技术和机器学习算法,对古诗词进行情感倾向判断,如基于词典的方法、机器学习算法等。例如,有研究利用SnowNLP库对古诗词进行情感分析,通过调用该库,分析诗句的情感倾向,值的范围在0到1之间,通常小于0.5代表消极情感,超过0.5则代表积极情感。国外在文本情感分析领域的研究较为成熟,但针对中华古诗词的情感分析研究相对较少,然而,国外在自然语言处理和机器学习方面的技术成果为国内研究提供了理论基础和方法借鉴。
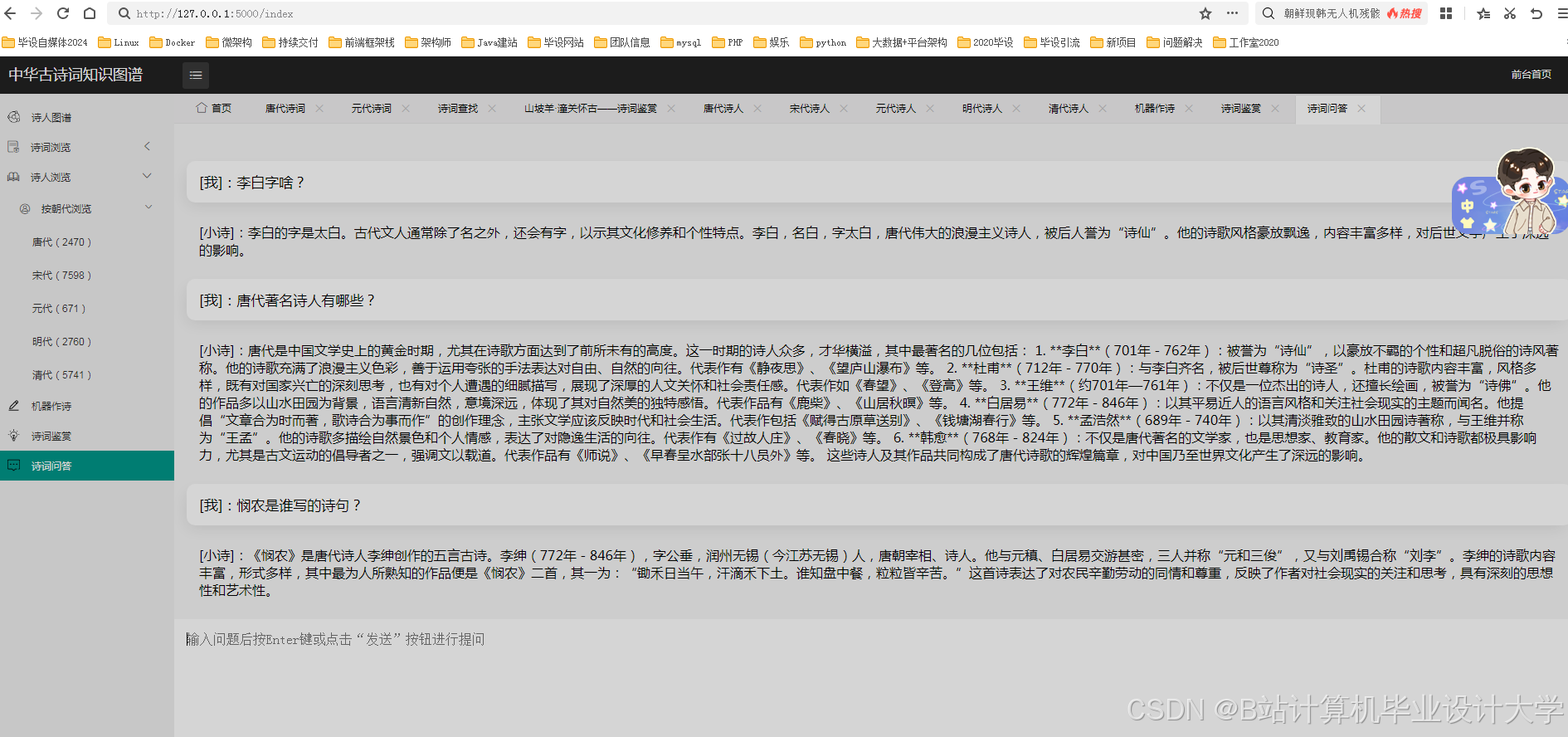
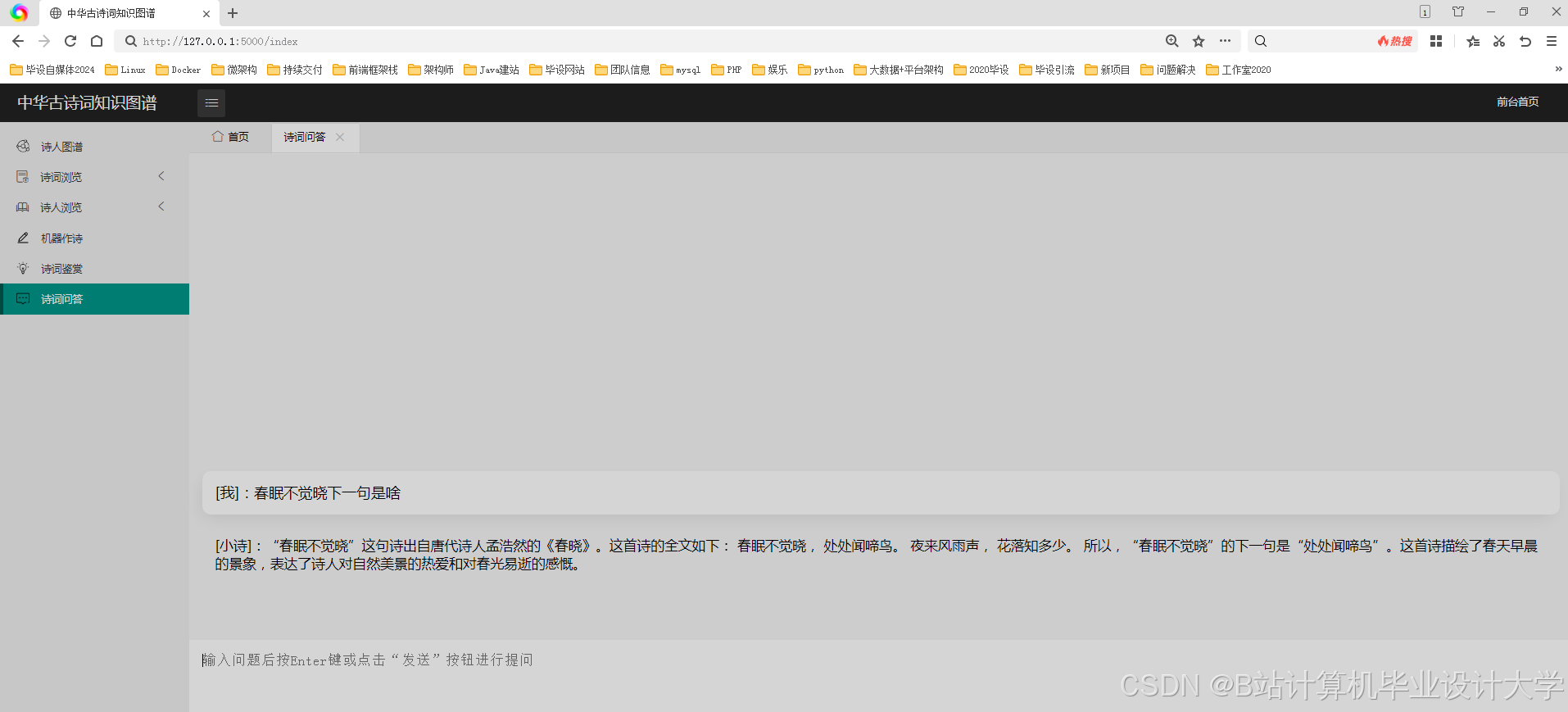
(四)智能问答系统
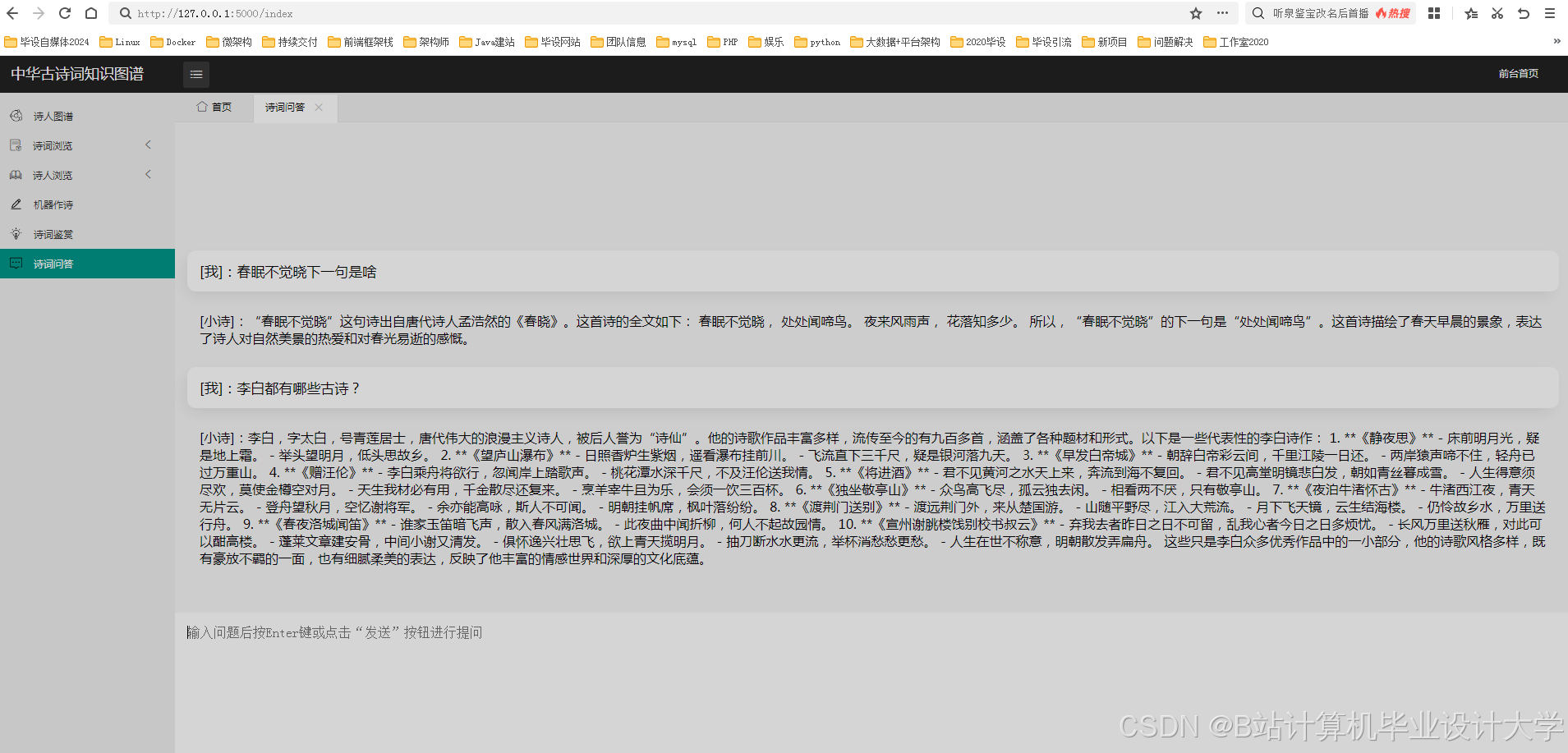
目前,已有一些研究利用自然语言处理技术和知识图谱构建了古诗词智能问答系统。这些系统能够展示诗人与诗作之间的关联,并通过智能问答系统快速回答用户关于古诗词的问题。例如,问题解析模块对用户输入的问题进行语义理解,提取问题的关键信息;知识检索模块在知识图谱中检索与问题相关的信息,找到满足查询条件的答案;答案生成模块根据检索到的信息,生成自然、准确的答案返回给用户。
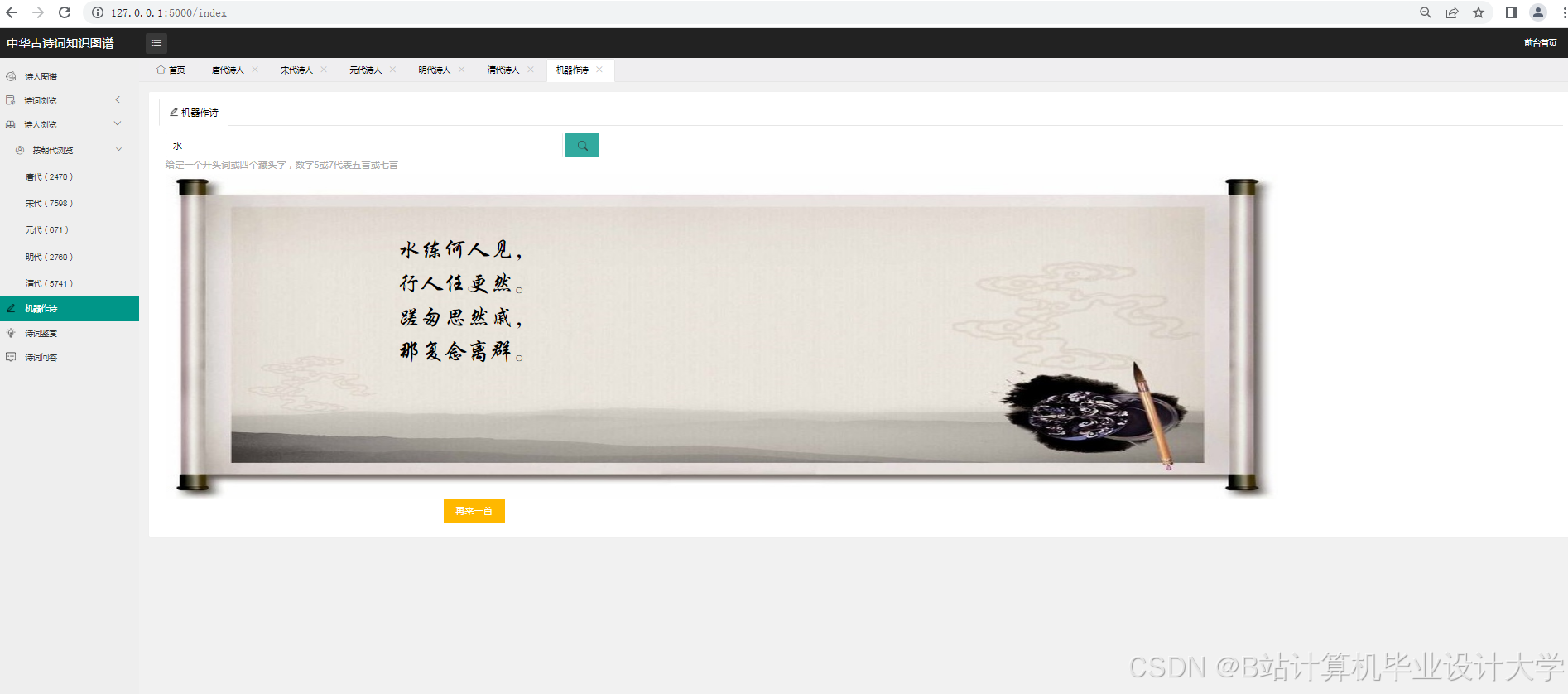
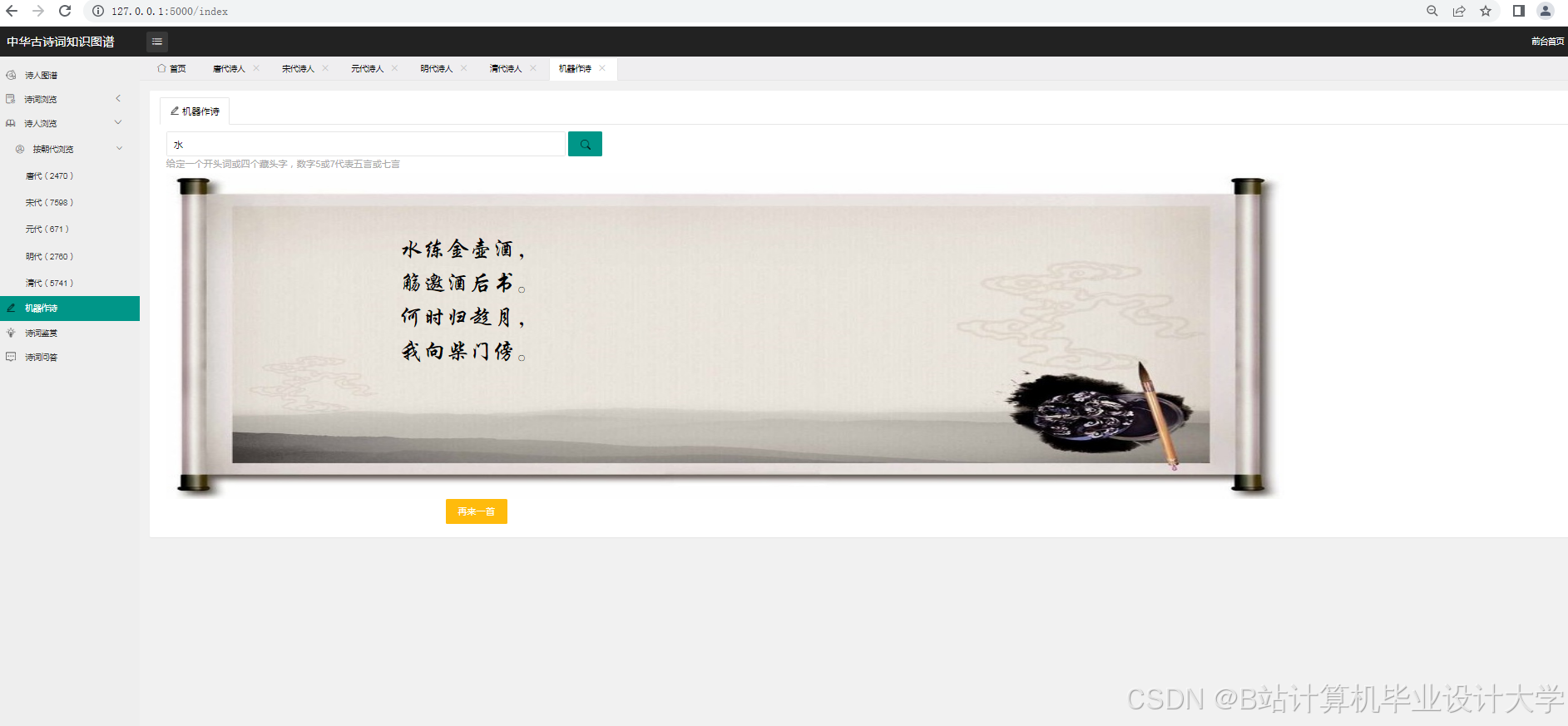
(五)AI大模型自动写诗
随着深度学习技术的发展,AI大模型在文本生成领域取得了显著成果。一些研究开始尝试利用AI大模型进行古诗词的自动创作。例如,有研究利用GPT系列模型等AI大模型,对模型进行训练与优化,使其能够生成具有古风特色的诗句。模型选择与训练是关键步骤,需要选择合适的AI大模型,并利用大量的古诗词数据对模型进行训练,使模型学习到古诗词的语言风格、韵律规则和意象表达等特点。
三、研究方法
(一)知识图谱构建技术
- 实体识别:识别古诗词中的实体,如诗人、诗作等。
- 关系抽取:识别实体之间的关系,如诗人创作诗作、诗作属于某个朝代等。
- 图数据库存储:利用Neo4j等图数据库进行存储和查询,构建完整的知识图谱。
(二)可视化技术
利用D3.js、ECharts等前端可视化库,将知识图谱以直观、交互式的方式展示出来。用户可以通过交互的方式深入了解古诗词的结构和关系。
(三)情感分析技术
- 文本表示:将古诗词文本转换为计算机可以处理的向量形式,如词袋模型、TF-IDF、词向量等。
- 情感分类算法:选择合适的机器学习算法或深度学习模型对古诗词进行情感分类,如朴素贝叶斯、支持向量机、LSTM、BERT等。
- 情感词典构建:构建专门针对古诗词的情感词典,提高情感分析的准确性。
(四)智能问答系统技术
- 问题解析:对用户输入的问题进行语义理解,提取关键信息。
- 知识检索:在知识图谱中检索与问题相关的信息。
- 答案生成:根据检索到的信息,生成自然、准确的答案。
(五)AI大模型自动写诗技术
- 模型选择与训练:选择合适的AI大模型,并利用大量的古诗词数据进行训练。
- 生成策略:采用合适的生成策略,如贪心搜索、束搜索等,提高生成诗句的质量和多样性。
- 后处理:对生成的诗句进行后处理,如韵律检查、语义优化等。
四、实验与结果
(一)数据准备
从《唐诗三百首》、古诗文网等公开数据库获取诗词内容、作者、创作时间等数据,进行清洗处理,去重、标准化文本,利用jieba等工具进行分词和去停用词。
(二)知识图谱构建
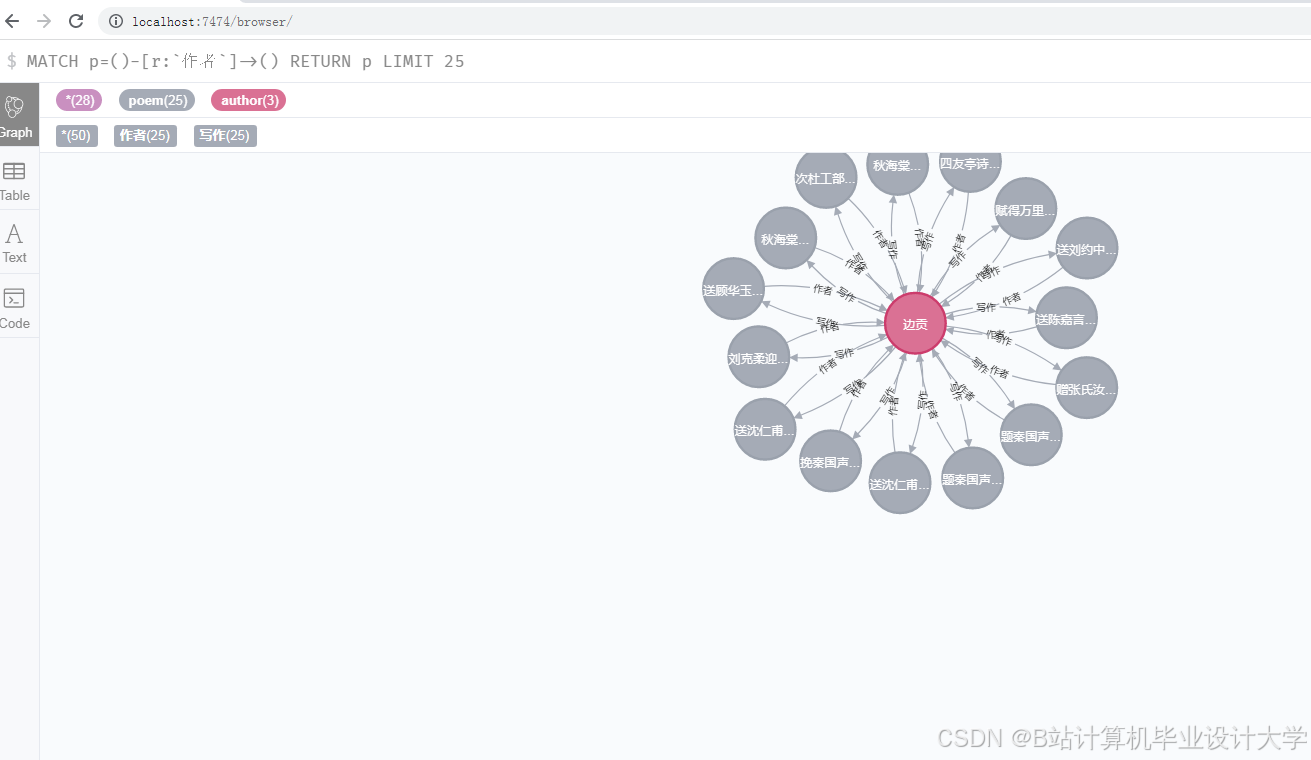
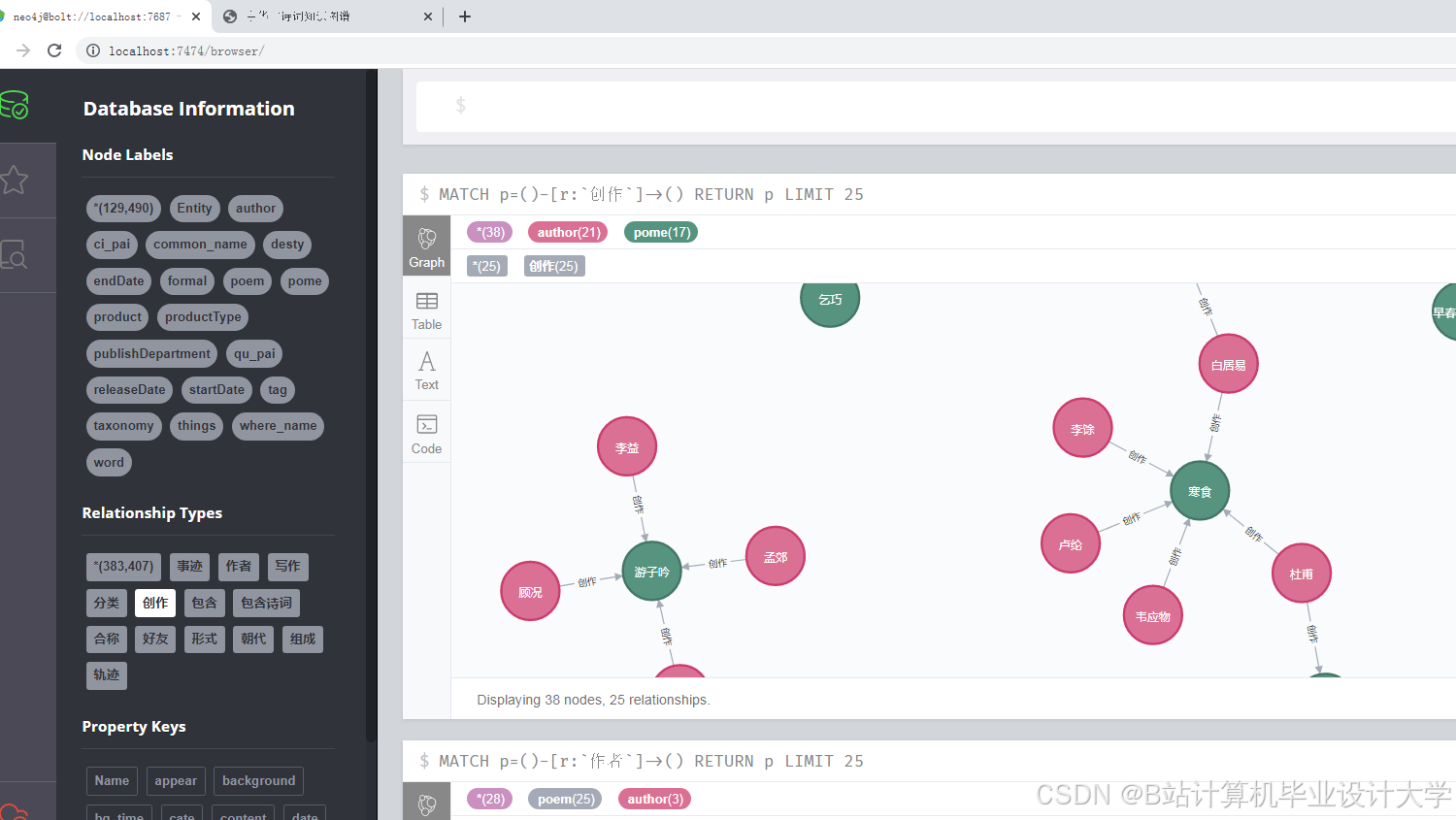
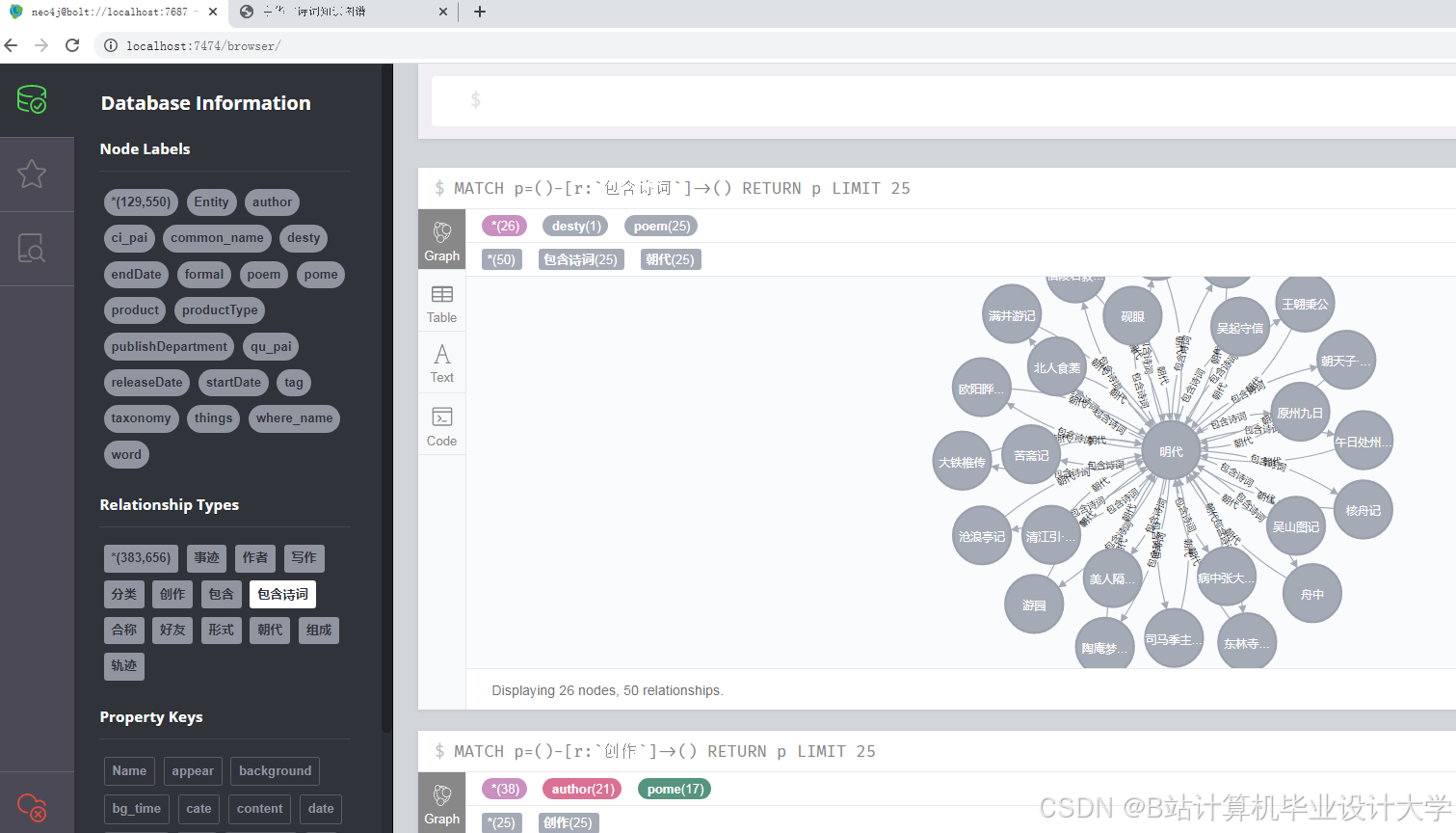
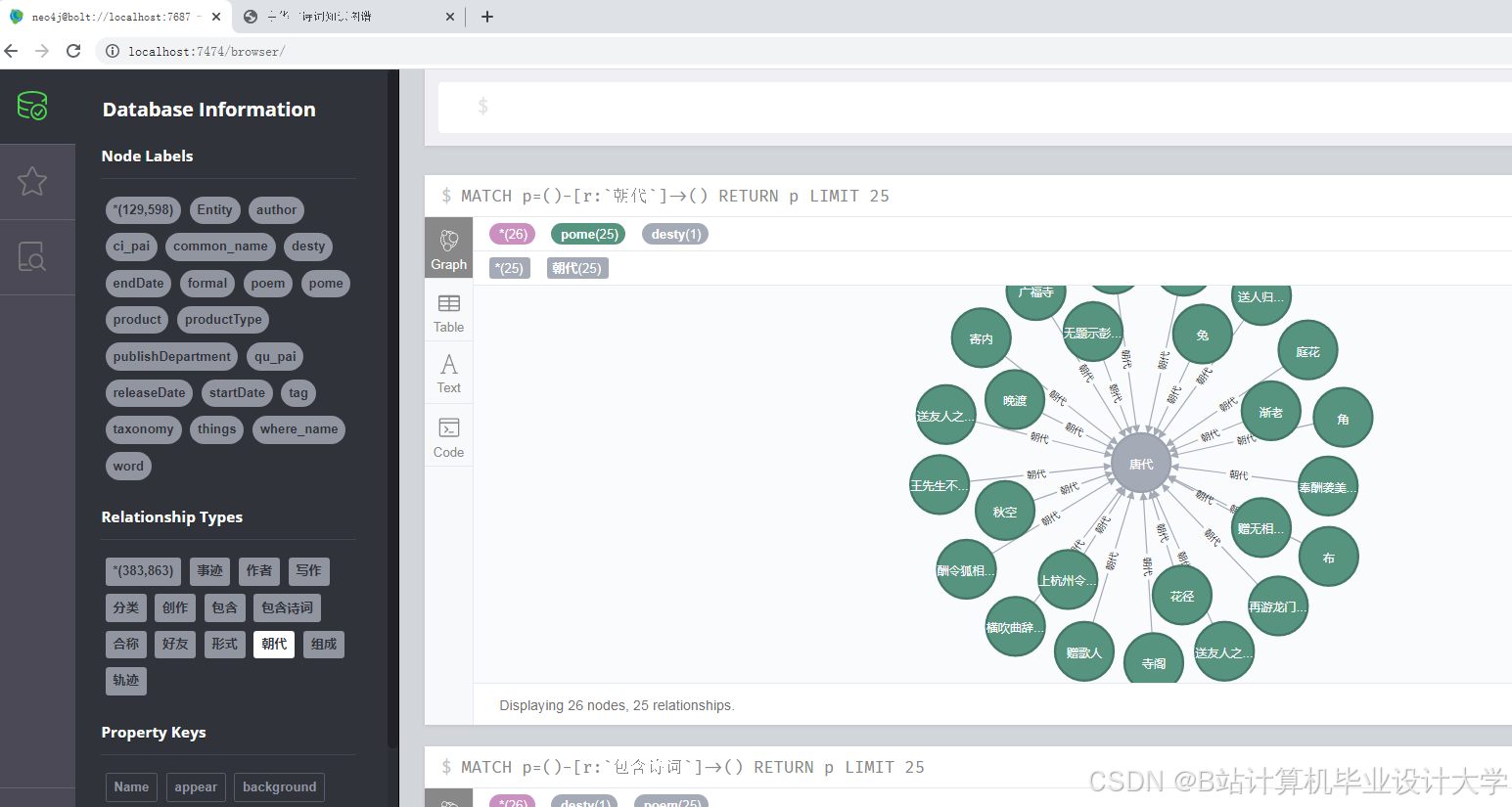
通过依存句法分析挖掘“诗人-作品”“作品-主题”等关系,使用Neo4j图数据库构建知识图谱,设计节点和边的类型及属性。
(三)可视化展示
采用D3.js、ECharts等库实现力导向布局、圆形布局等展示方式,提供交互式查询与学习功能。
(四)模型训练与融合
训练LSTM、BERT等模型进行主题分类和情感分析,将模型输出的特征与知识图谱结合,优化推荐算法。
五、讨论
(一)优势
本研究利用Python技术构建中华古诗词知识图谱,并结合深度学习模型与可视化工具,推动了传统文化的数字化传承与创新。通过知识图谱的构建和可视化,可以直观地展示诗人、诗作、朝代、类别等实体之间的关系,帮助研究人员和爱好者更深入地理解和探索古诗词的结构和内涵。同时,结合深度学习模型,可以提高情感分析的准确性,生成更具古风特色的诗句,进一步丰富古诗词的研究和应用。
(二)不足
当前研究仍存在一些挑战和不足。首先,数据质量是影响研究结果的重要因素,古诗词文本中存在大量的生僻字、古汉语词汇和语法结构,给实体识别和关系抽取带来了一定的难度。其次,模型的泛化能力有待提高,由于古诗词的语言风格和意象表达具有多样性,模型在不同类型古诗词上的表现可能存在差异。此外,跨学科融合不足也是当前研究面临的问题之一,古诗词研究涉及文学、语言学、历史学等多个学科,需要加强跨学科的合作与交流,推动古诗词研究的深入发展。
六、结论
当前研究在中华古诗词知识图谱构建、可视化、情感分析、智能问答和自动写诗等方面取得了一定成果,为古诗词的数字化处理与传承提供了有力的技术支持。然而,仍存在一些挑战和不足,如数据质量、模型泛化能力、跨学科融合等问题。未来研究可以进一步探索和改进深度学习模型的结构和算法,提高模型在古诗词领域的泛化能力和性能;同时加强跨学科的合作与交流,推动古诗词研究的深入发展。通过不断优化和完善技术手段,我们有理由相信,Python知识图谱在中华古诗词可视化领域的应用将更加广泛,为传统文化的传承与创新贡献更大的力量。
运行截图
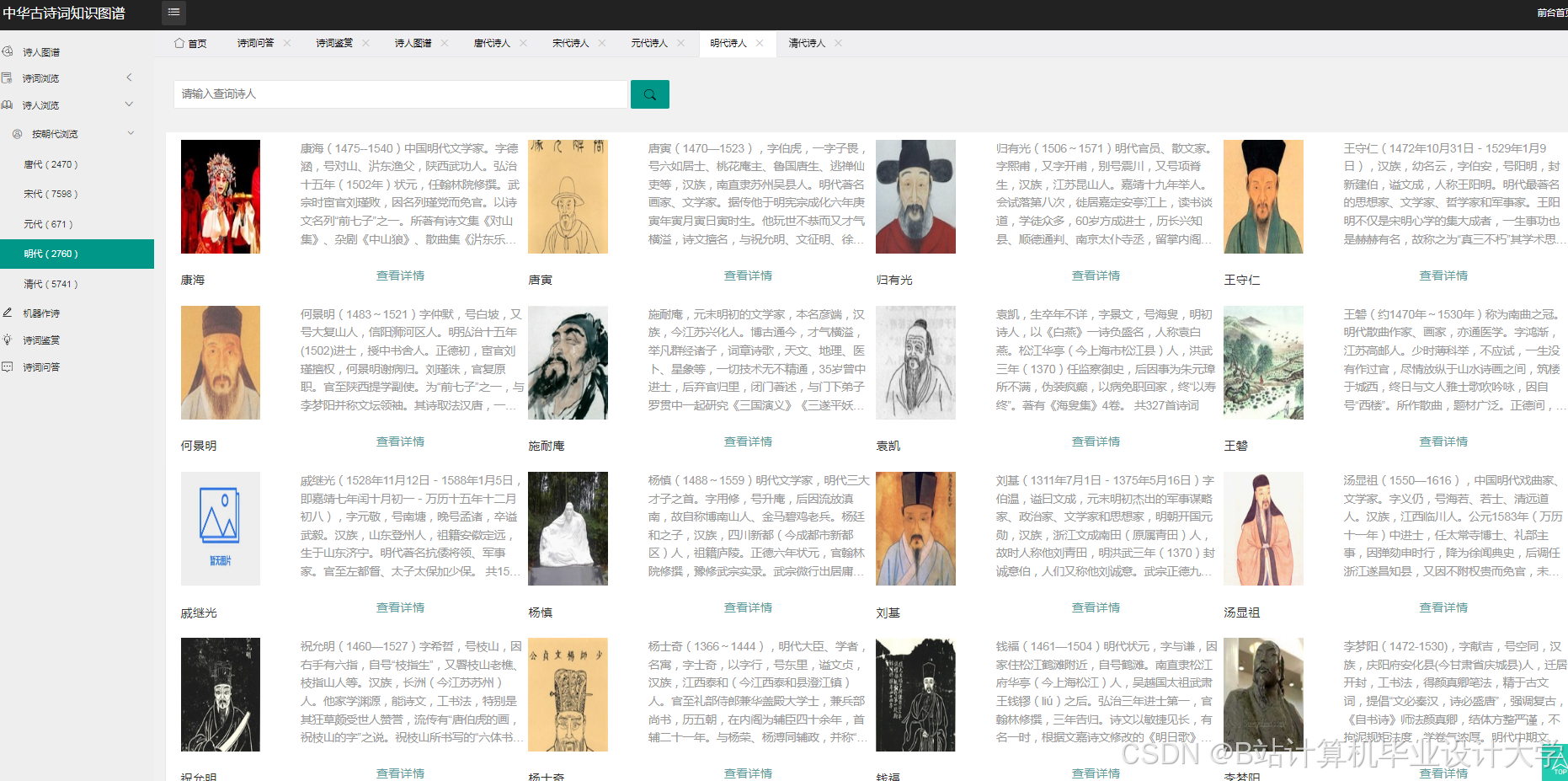
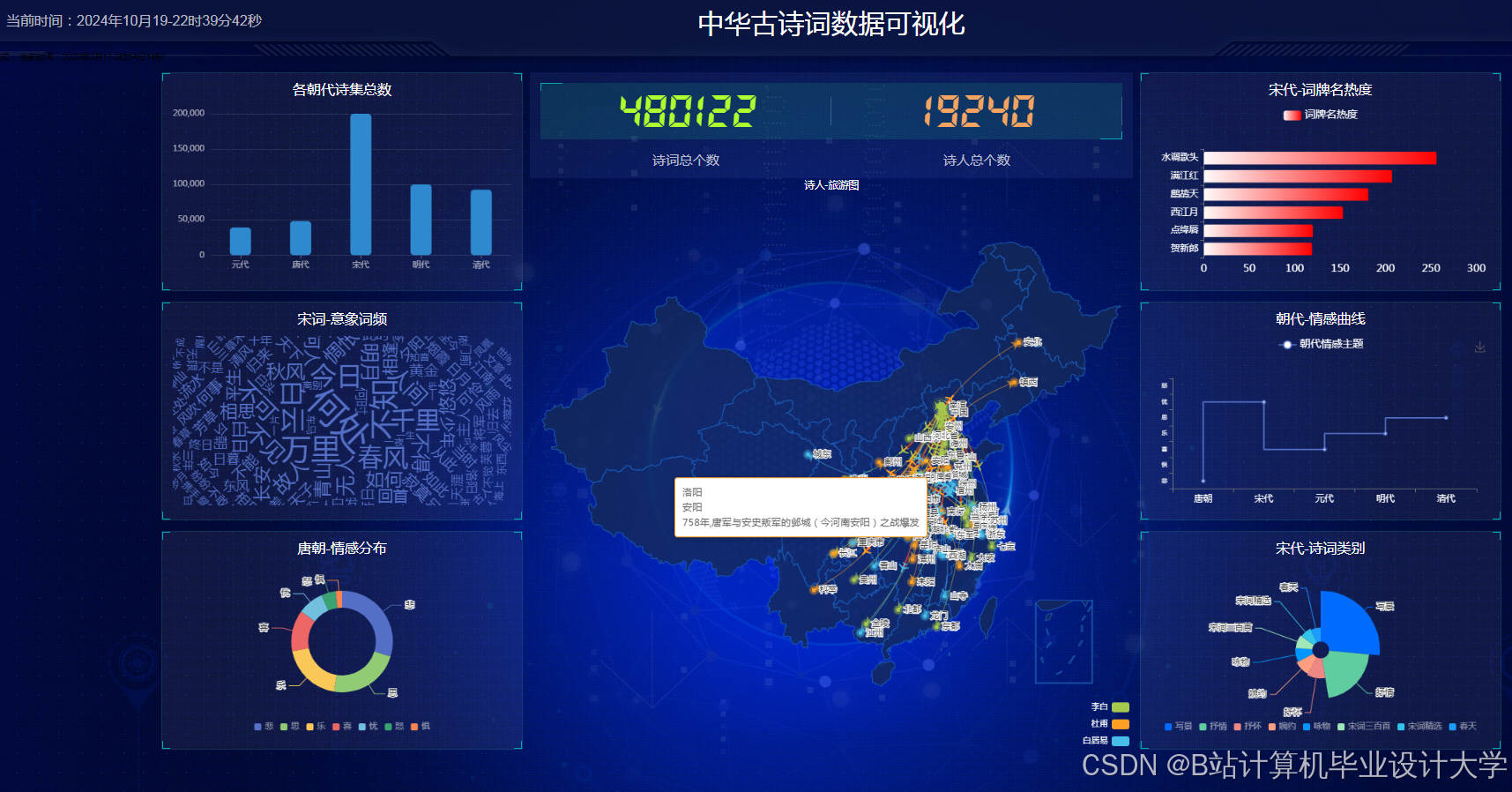
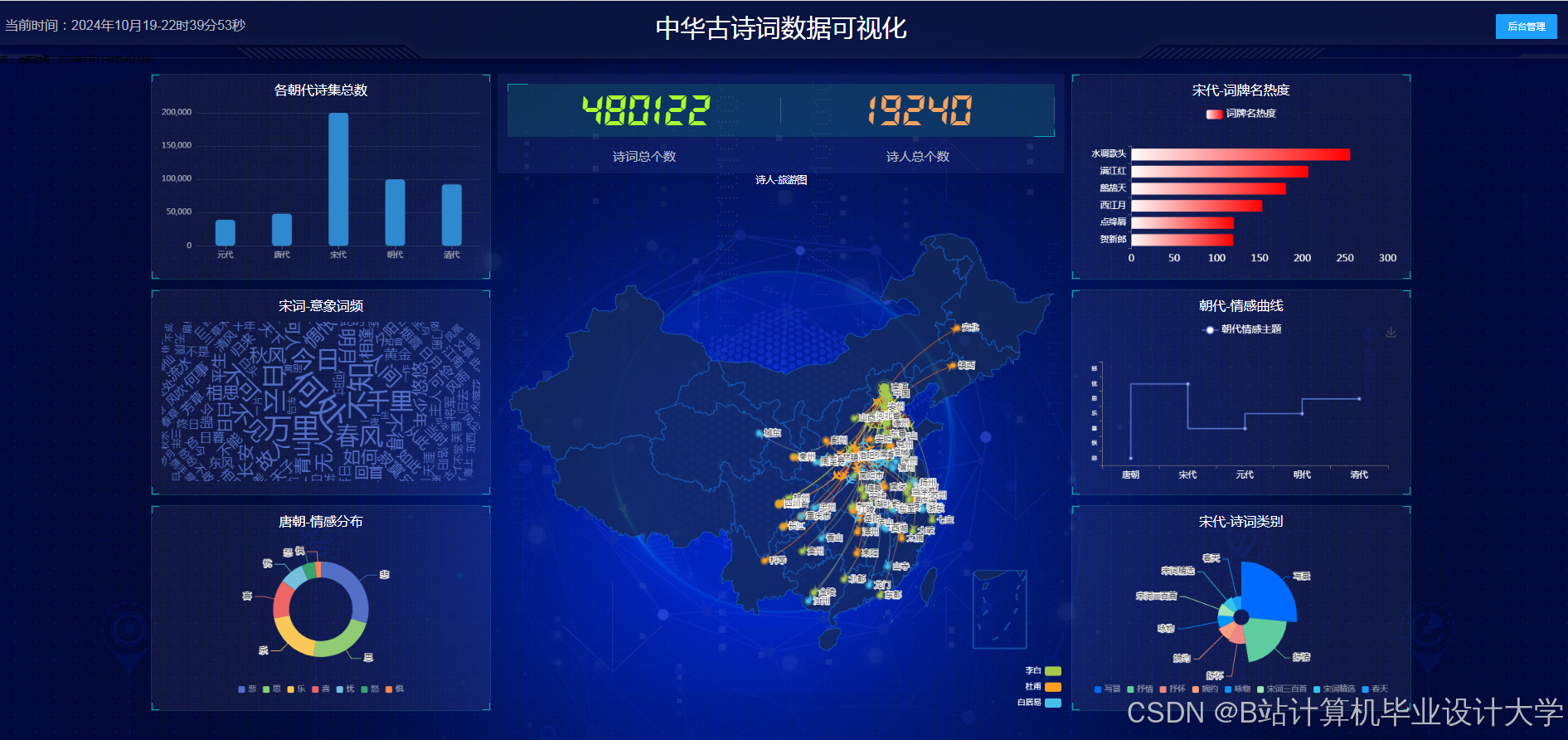
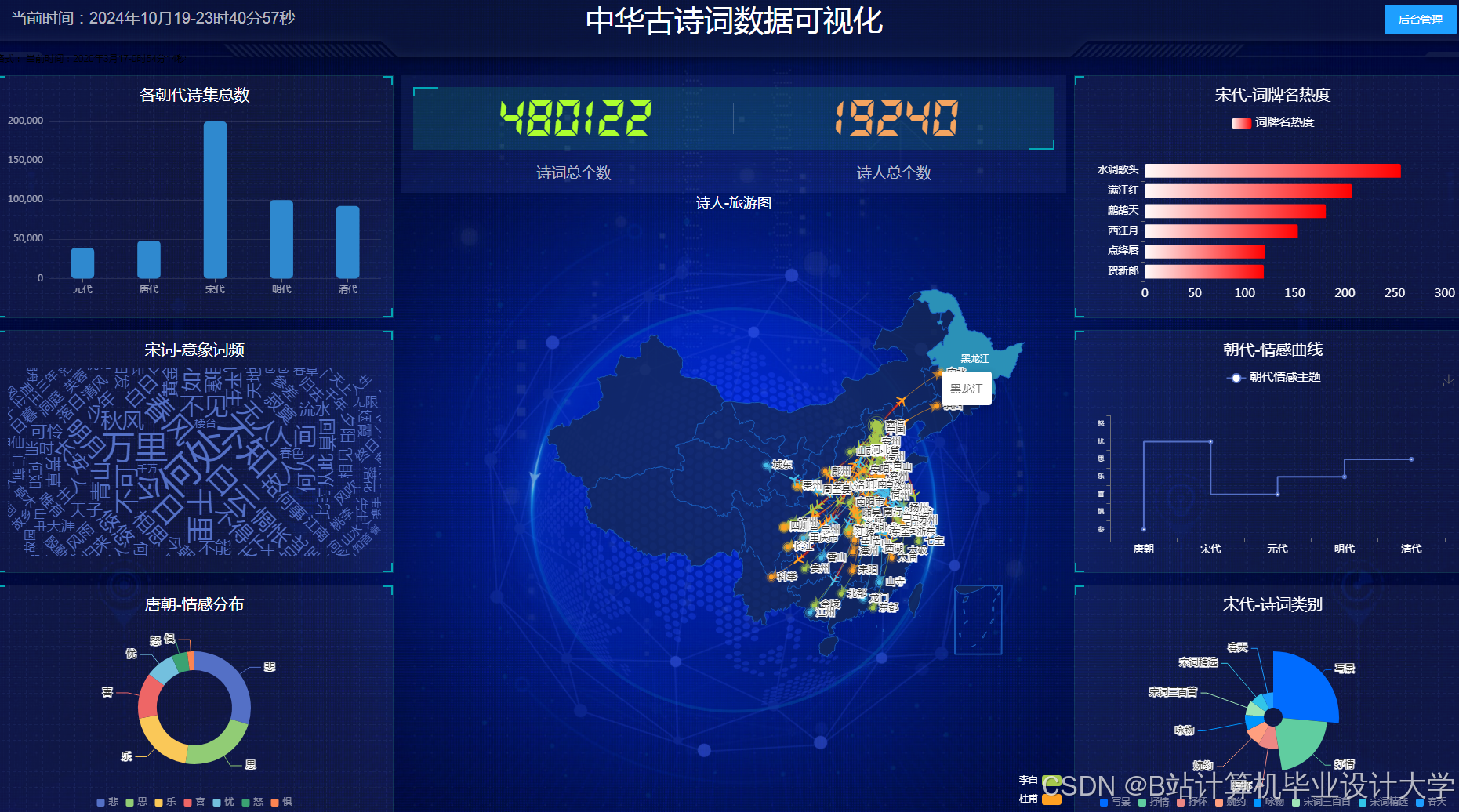

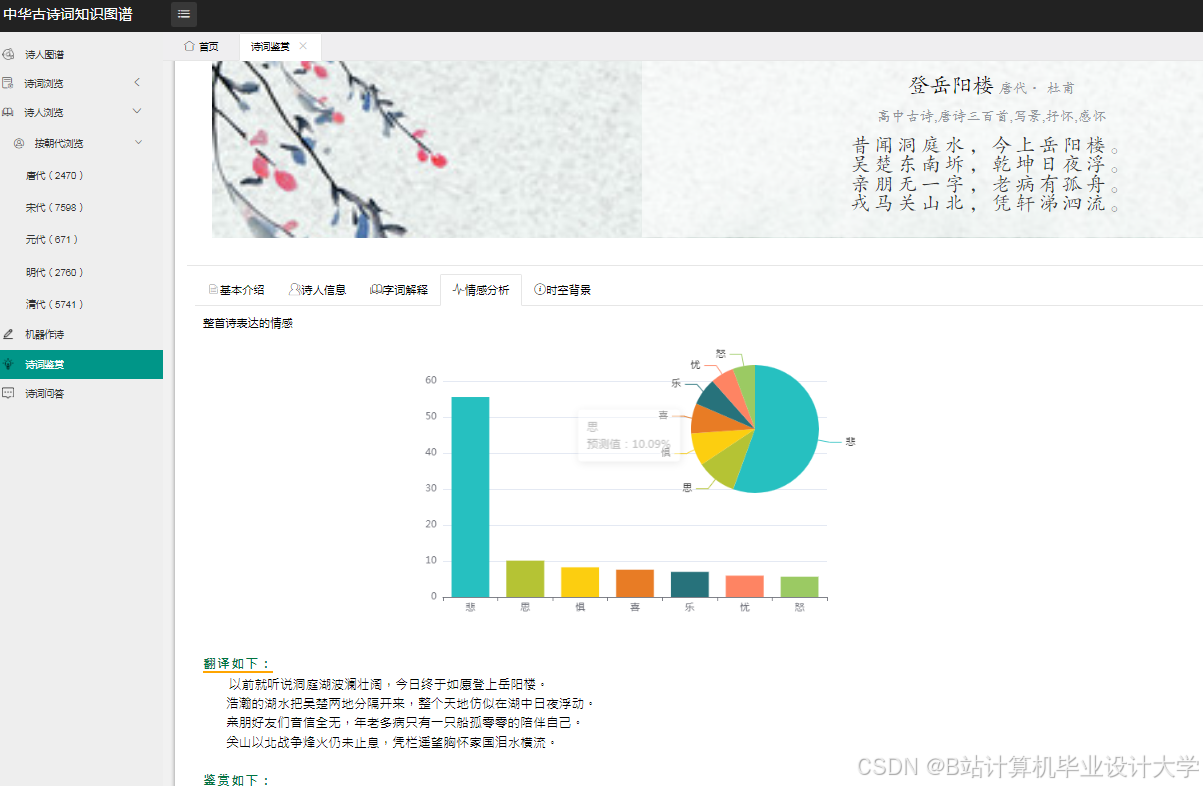
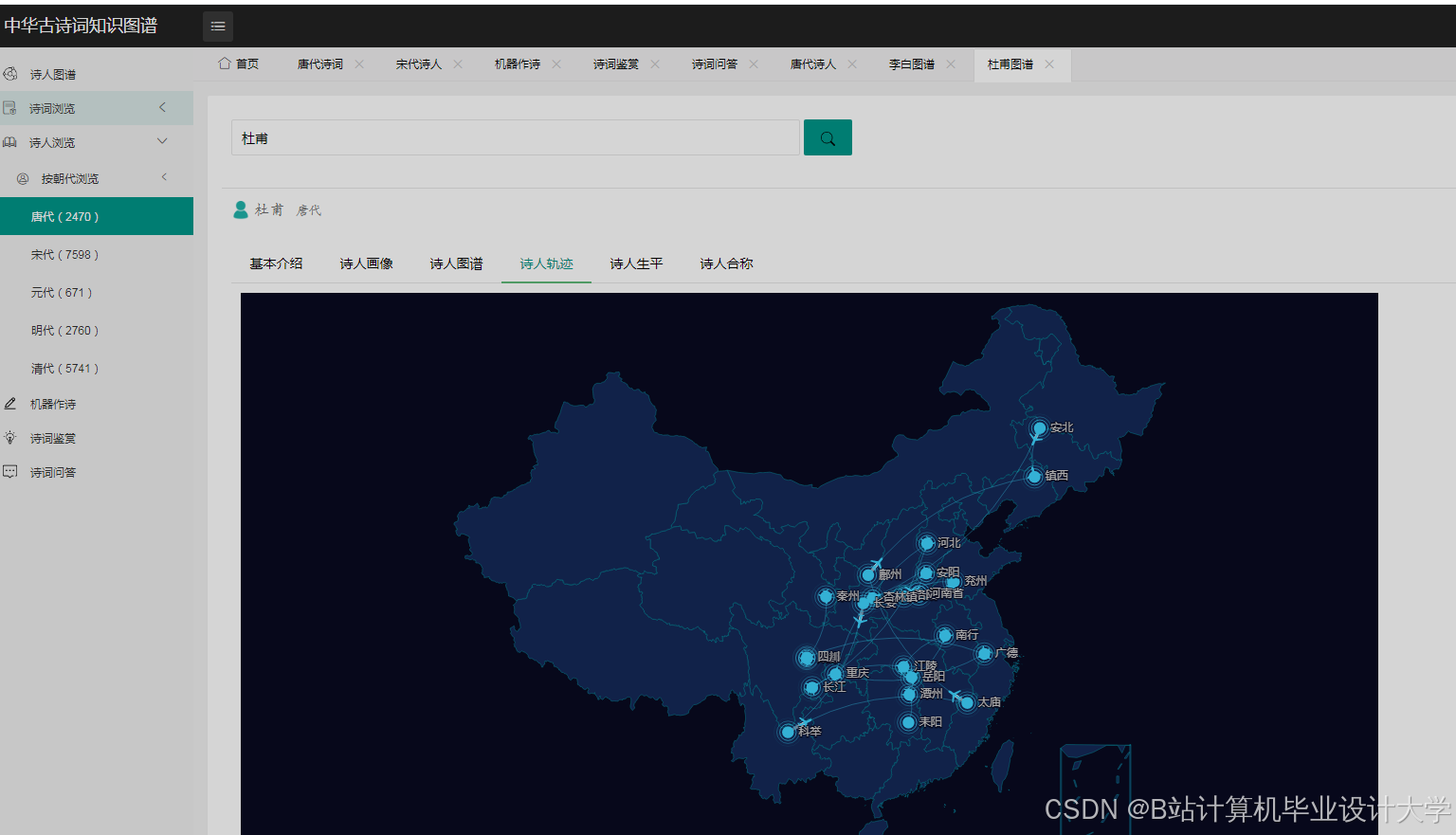
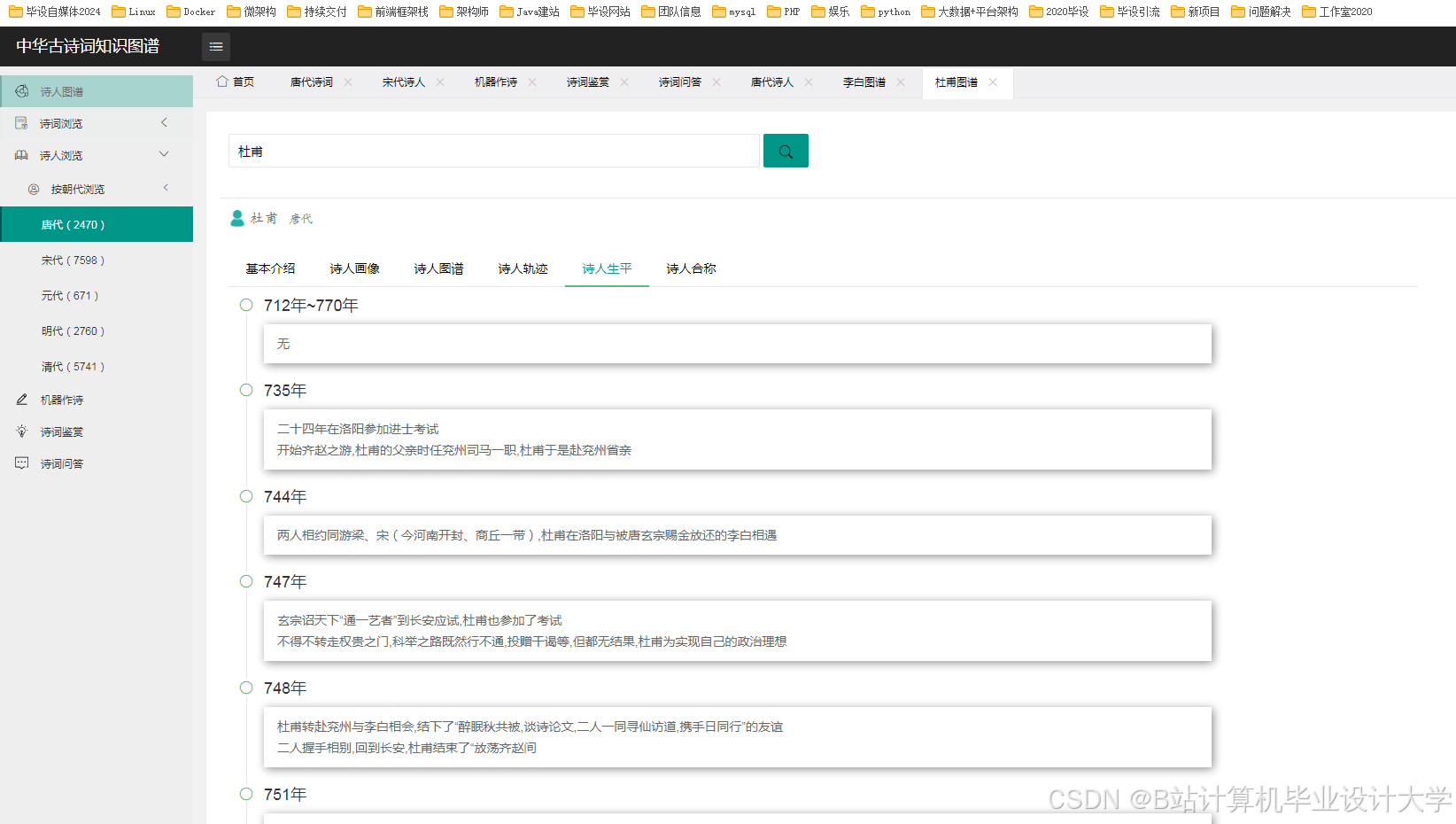
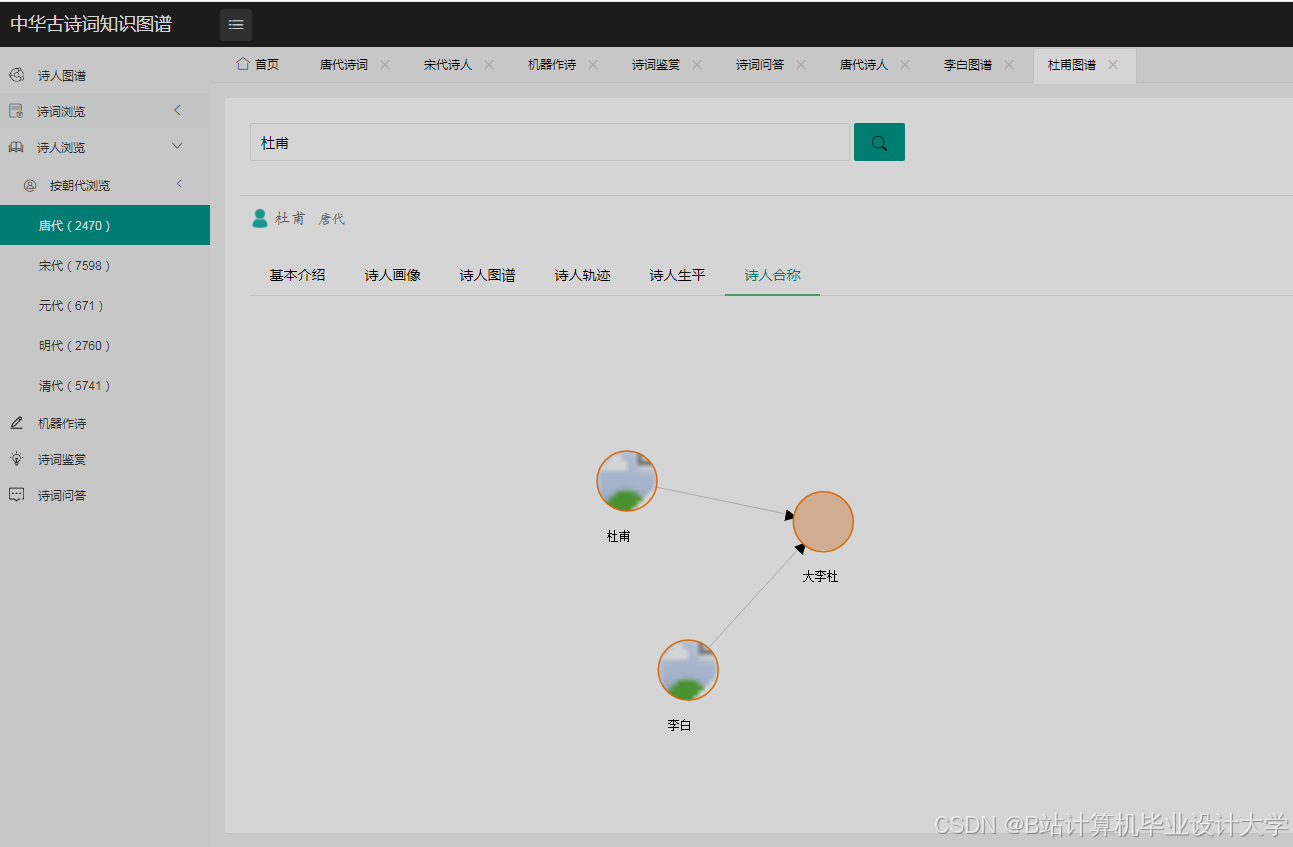
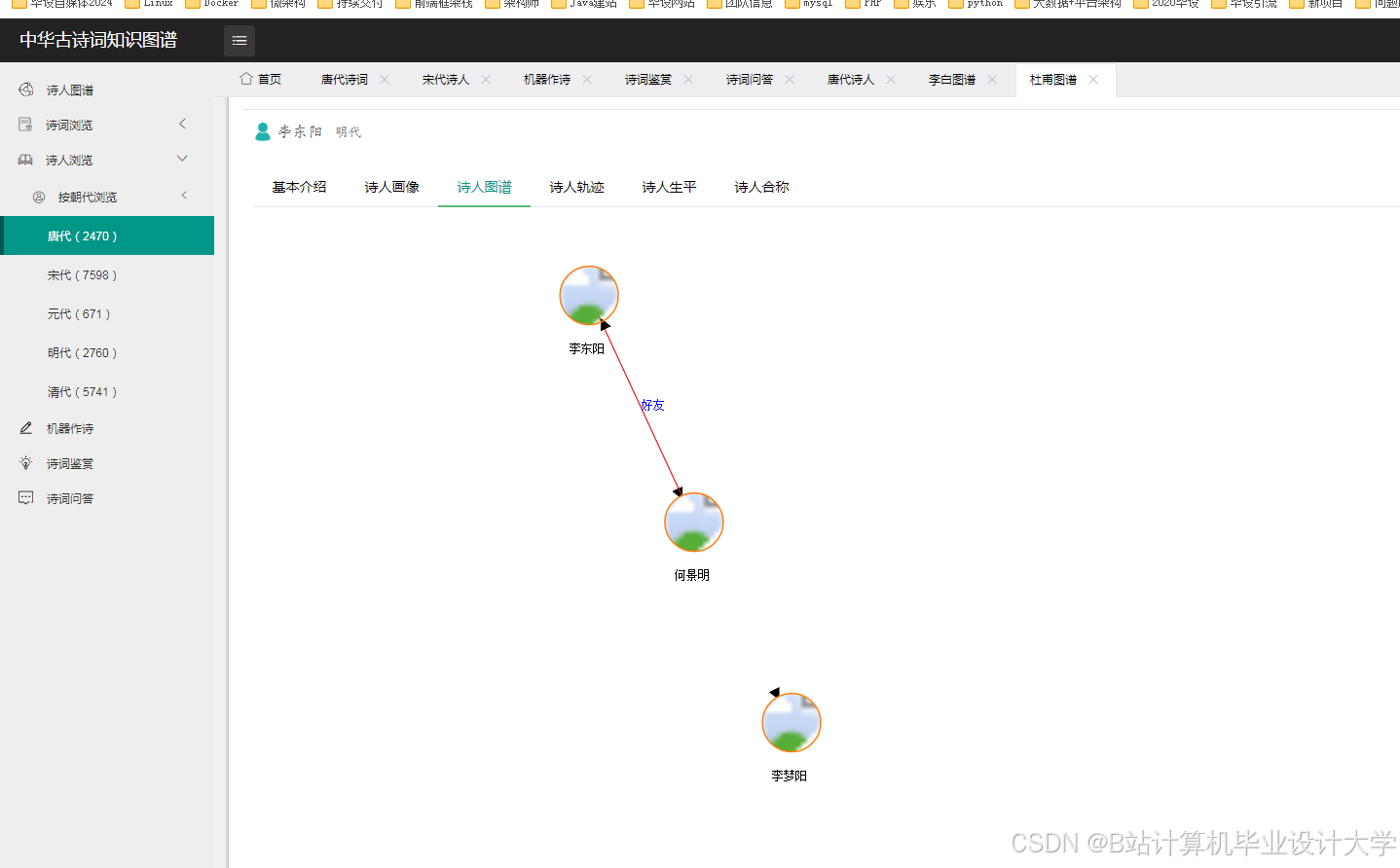

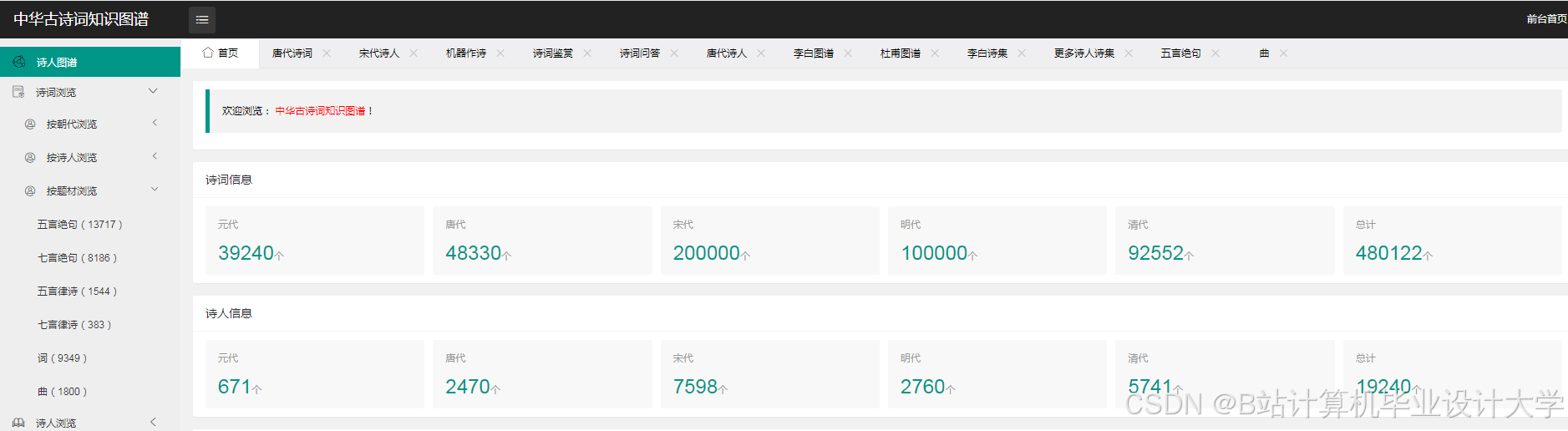
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











