






http://preshing.com/20121019/this-is-why-they-call-it-a-weakly-ordered-cpu/
注:对于理解weak cpu下的reordering而言,这真是一篇相当好的文章。拿起你的xcode和4s,可以直接测试运行作者的例子。没什么比鲜活的例子更令人印象深刻。
还有就是,除了在iphone 3GS上测试外,这里可以再次使用cpu affinity设置来验证单核运行的情况。
---->正文开始
在前面,我们已经了解了lock-free编程的一些主题,比如acquire and release语义,以及weakly-ordered CPU。我试图使这些主题讲解的容易接受和容易理解。但是什么都没有一个实际的例子来的更直观。
(注:acquire and release后面就翻译到)
如果用一件事情来表征weakly-ordered CPU,那就是一个CPU core看到的共享内存中几个value的变化顺序和另一个写入它们的core不同。这就是本篇中我希望使用纯粹的C++11来描述的。
对于正常应用,x86/64和AMD都不会有这种特性,所以PC上是不可能出现的。我们真正需要的是一个weakly-ordered设备,幸运的是,我口袋里就有一个:iPhone4S。
苹果的iPhone4S运行在ARM双核处理器上,而ARM体系结构就是weakly-ordered。
The Experiment
我们的实验包括一个被mutex保护的integer变量sharedValue。我们生成两个线程,每个线程都一直运行,直到它们将sharedValue增加了10,000,000次。
我们不会让线程block在等待mutex上。相反,每个线程都会做busy loop(只是为了浪费CPU),并且试图获取mutex。如果成功上锁,就增加sharedValue,再unlock。如果lock失败,就继续busy loop。伪代码像这样:
count = 0
while count < 10000000:
doRandomAmountOfBusyWork()
if tryLockMutex():
// The lock succeeded
sharedValue++
unlockMutex()
count++
endif
end while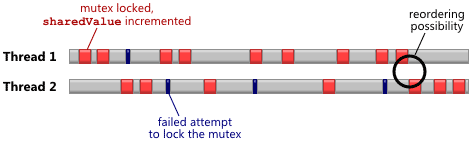
这很容易首先,因为mutex就是一个概念,有很多种方式实现一个。我们可以直接使用C++11提供的std::mutex,显然,一切都会运行正常。那我就没有什么好说的了。去二呆子,我们将自己实现一个mutex——然后让我们再将其分解展示weak hardware ordering的结果。直观上,潜在的memory reordering最可能发生在线程之间存在“close shave”的那些时刻——比如,在上面的图中,正当一个线程释放锁的时候另一个线程获得了锁。
最新的Xcode很好的支持C++11的thread和atomic类型,我们就用它了。C++11的所有标识符都在std命名空间中。
A Ridiculously Simple Mutex
我们的mutex只包含一个integer变量flag,1表示mutex已经被获取,0表示没有。为了保证mutex的互斥性,一个thread只能在flag为0的时候将它设置为1,并且这个操作是atomic的。为了做到这一点,我们将flag定义为C++11 atomic类型,atomic<int>,并且使用它的read-modify-write操作:
int expected = 0;
if (flag.compare_exchange_strong(expected, 1, memory_order_acquire)) {
// The lock succeeded
}这是释放锁:
flag.store(0, memory_order_release);If We Don’t Use Acquire and Release Sematics…
现在,让我们使用C++11实验一把,但是不使用正确的顺序限制,让我们在两个地方都是用memory_order_relaxed,这意味着C++11编译器并不会强制memory ordering,任何reordering都是允许的。
void IncrementSharedValue10000000Times(RandomDelay& randomDelay) {
int count = 0;
while (count < 10000000) {
randomDelay.doBusyWork();
int expected = 0;
if (flag.compare_exchange_strong(expected, 1, memory_order_relaxed)) {
// Lock was successful
sharedValue++;
flag.store(0, memory_order_relaxed);
count++;
}
}
}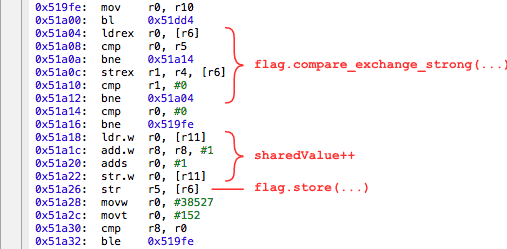
如果你对汇编语言不熟悉,不用担心。我们所需要知道的就是compiler是否对共享变量的任何操作做了重新排序。这包括flag上的两次操作,以及中间的sharedValue的递增操作。我已经在上面的汇编语言上做了标注。你可以看到,我们很幸运:compiler没有重新排列这些操作的顺序,即使memory_order_relaxed参数意味着它可以这么做,凭心而论。
我已经写了一个简单程序重复上面的实现,在每次执行结束后打印sharedValue的最终结果。在Github上你可以看到代码:https://github.com/preshing/AcquireRelease
这是Xcode的运行输出:
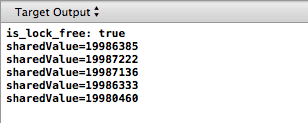
仔细看看,sharedValue的最终结果一贯的小于20,000,000,即使每个线程都精确的执行了10,000,000次递增操作,并且汇编语言中指令的顺序和我们程序的操作顺序也是一致的(也就是说compiler没有给我们重排序)。
你可能已经猜到了,这个结果完全来自于CPU的memory reordering。指出可能的一种重排序——有好几种——内存交互 str .w r0, [r11](sharedValue的store)可以和str r5, [r6](flag的store 0)重排序。换句话说,在我们结束之前,mutex可以被释放掉!!!另一个线程就可以将我们所做的修改置换掉,导致了sharedValue的值与预期的不相符。就像实验中看到的那样。
Using Acquire and Release Semantics Correctly
要想修正我们的程序,很简单就是使用C++11正确的memory ordering限制。
void IncrementSharedValue10000000Times(RandomDelay& randomDelay) {
int count = 0;
while (count < 10000000) {
randomDelay.doBusyWork();
int expected = 0;
if (flag.compare_exchange_strong(expected, 1, memory_order_acquire)) {
// Lock was successful
sharedValue++;
flag.store(0, memory_order_release);
count++;
}
}
}结果就是,我们可以看到编译器插入了一堆dmb ish指令,在ARMv7指令集中起到memory barrier的作用。我不是ARM专家——欢迎评论——但是可以安全的假设这条命令就像PowerPC上的lwsync一样,为在compare_exchange_srong上获取acquire语义,以及store上获取release语义,提供了所有的memory barrier类型。

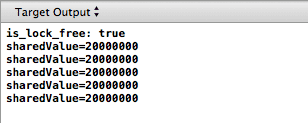
这一次,我们自己的mutex确实保护了sharedValue,在每次lock mutex成功时,保证了所有的修改都正确的传递给了另外一个线程。
如果你还不是很直观的理解这个实验,我建议你看看我的代码控制那篇文章。使用那个类比的术语,你可以想象两个电脑对sharedValue和flag都有自己的本地copy,你需要一个经理来保持它们是sync的。个人而言,我发现用这种可视化的方式很有帮助。
我还是喜欢重申一遍——我们这里看到的memory reordering只能在multicore或者multiprocessor设备上观察到。如果你将同样的代码在iPhone 3GS或者第一代iPad上运行,你不会看到sharedValue有错误值的情况,它们也是同样的ARMv7体系,但是只有一个CPU core。
Interesting Notes
同样的程序,你可以在使用x86/64CPU的Windows,MacOS或者Linux平台上测试,除非你的compiler在这些指令上做了reordering,否这你是看不到运行时的memory reordering的——即使是multicore系统上。因为x86/64 processor是strongly-ordered:当一个CPU core执行一系列writes时,其它的任何CPU看到的这些值改变的顺序,和它们write时的顺序完全一致。
这也可说明为什么错误使用了C++11的atomic时,程序依然是正确的,而你并不知道这种错误。
在本例下,VS2012的发布版本生成的x86代码真是很糟糕。一点也不像Xcode生成的ARM代码那么高效。毕竟在多核上使用lock-free编程的首要原因就是性能![2013 Feb更新:就像后面的评论,VS2012 Professional的最新版生成的机器代码好多了]
这一篇是前面证明x86/64平台上的StoreLoad reordering的姊妹篇(也就是前面的caught in the act那篇)。然而,根据我的经验,#StoreLoad barrier的使用并不像其它ordering限制那么频繁。
最后,我不是第一个例证在实际中weak hardware ordering的人,有可能我是第一个使用C++11的那个。Pierre Lebeaupin和ridiculousfish以前也写过文章使用不同的例子描述了这种现象。
http://wanderingcoder.net/2011/04/01/arm-memory-ordering/
http://ridiculousfish.com/blog/posts/barrier.html
















 1413
1413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









