










在很长一段时间内,占据大模型评测榜单最前列的大多是一些闭源模型,直到Meta再次发布了最新的开源模型。就在近日,Meta和OpenAI打响了硅谷 AI 大模型保卫战。
美国当地时间7月23日,Meta正式发布Llama 3.1。其包含8B、70B 和405B三个规模,最大上下文提升到了128k。Llama是目前开源领域中用户最多、性能最强的大型模型系列之一。
Meta 表示,他们将通过提供更多与模型协同工作的组件(包括参考系统),继续将 Llama 打造成一个系统,并希望为开发人员提供工具,帮助他们创建自己的定制智能体和新智能体行为。
此外,Meta 也将通过新的安全和保障工具(包括 Llama Guard 3 和 Prompt Guard)帮助开发者负责任地进行开发。Meta 在在官方博客中写道,“迄今为止,开源大语言模型在功能和性能方面大多落后于封闭的同类产品。如今,我们迎来了一个由开源引领的新时代。我们将公开发布 Meta Llama 3.1 405B,我们相信它是世界上规模最大、功能最强的开放基础模型。”

性能表现
与之前的 Llama 版本相比,Llama 3.1提高了用于训练前和训练后的数据的数量和质量。这些改进包括为训练前数据开发更仔细的预处理和管理流程、开发更严格的质量保证以及训练后数据的过滤方法。
另外,为了支持 405B 规模模型的大规模生产推理,团队还将模型从 16 位 (BF16) 量化为 8 位 (FP8) 数字,有效降低了所需的计算要求并允许模型在单个服务器节点内运行。
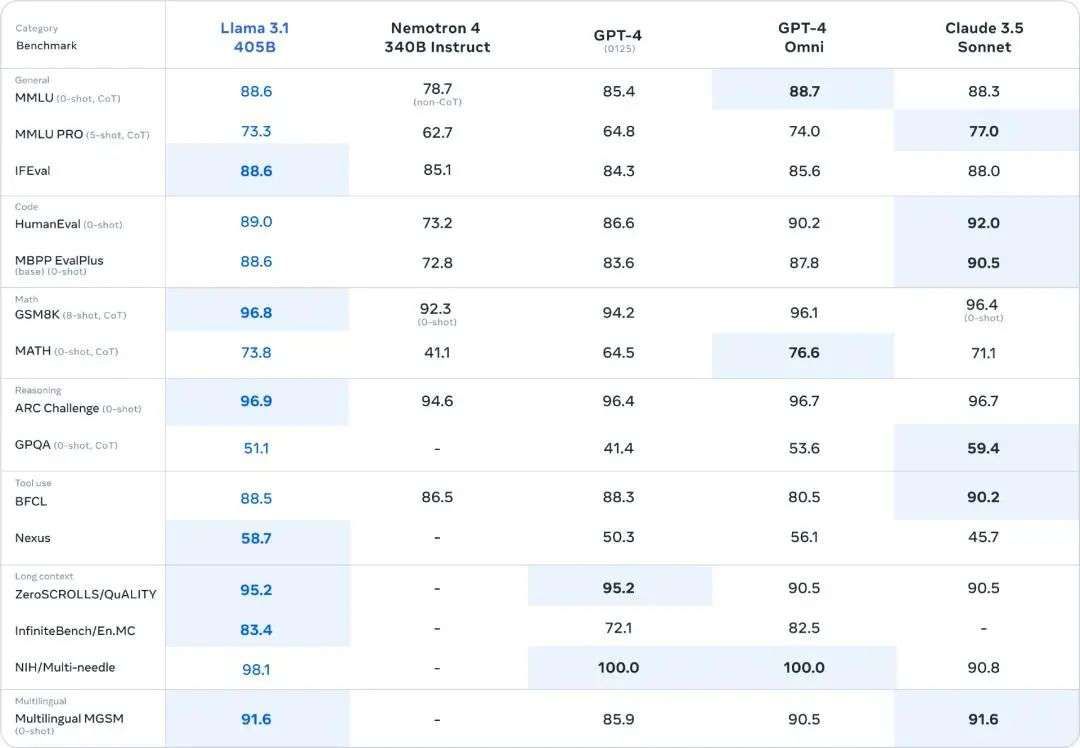
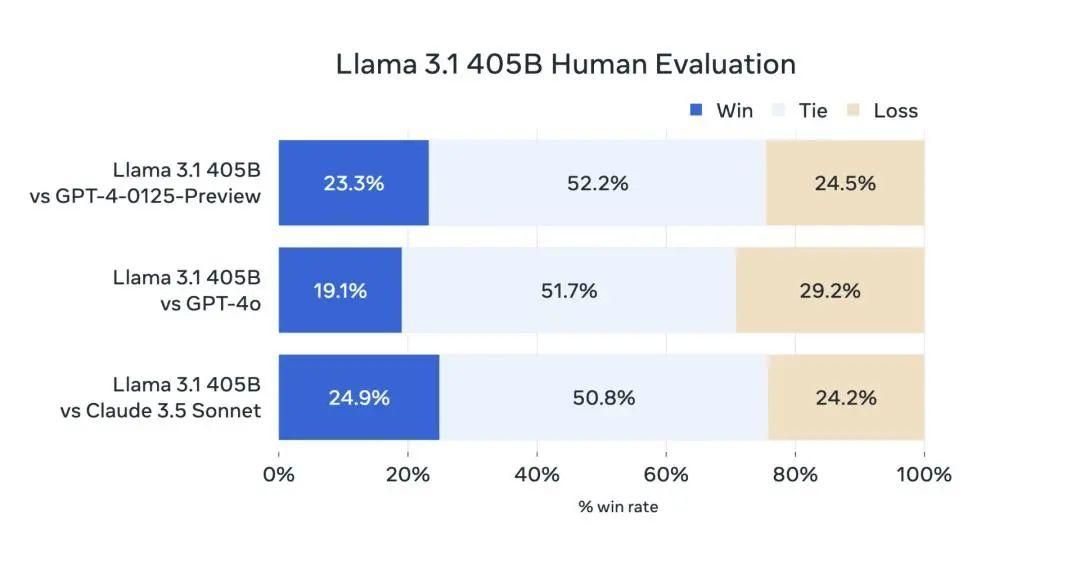
在其他场景中,Llama 3.1 405B进行了与人工评估的比较,Llama 3.1 405B在常识、可操作性、数学、工具使用和多语言翻译等一系列任务中,其总体表现优于GPT-4o和Claude 3.5 Sonnet。
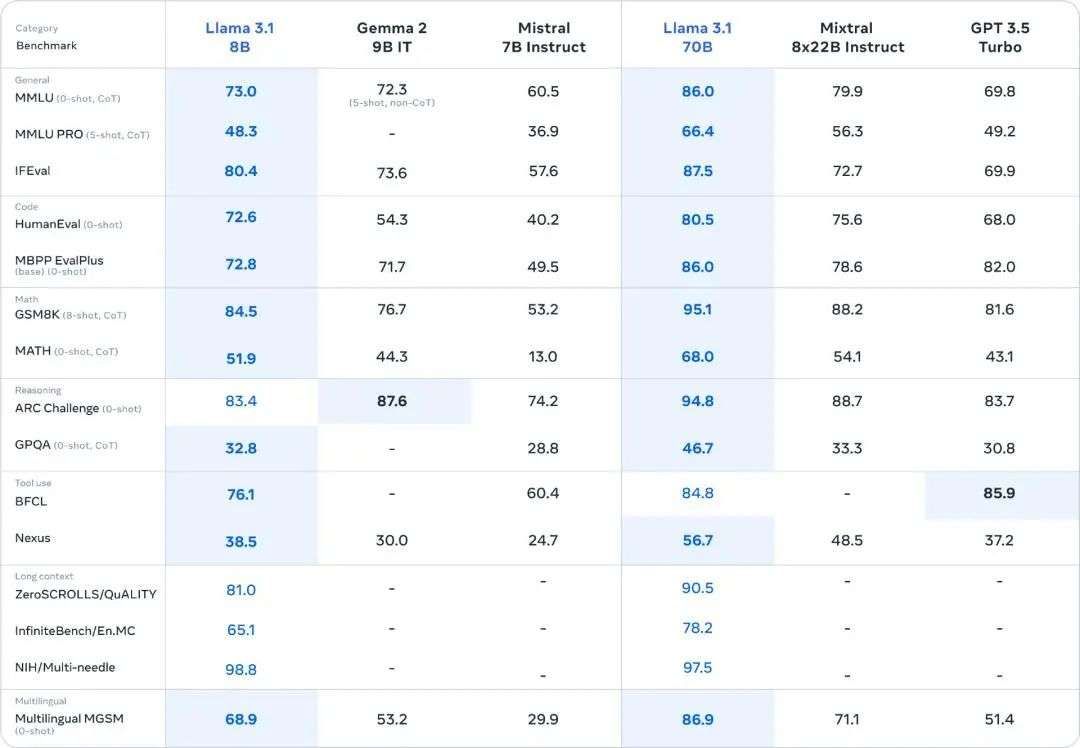
作为最新版本的一部分,他们推出了 8B 和 70B 模型的升级版本。这两个版本支持多种语言,相比于同样参数大小的模型性能表现也更好。上下文长度大大增加,达到 128K,工具使用 SOTA,整体推理能力更强。
这使得 Llama 3.1 系列模型能够支持高级用例,如长文本摘要、多语言对话智能体和编码助手。值得一提的是,Meta 还修改了许可证,允许开发人员使用 Llama 模型(包括 405B 模型)的输出结果来改进其他模型,并在 llama.meta.com 和 Hugging Face 上向社区提供这些模型的下载。
模型架构
作为 Meta 迄今为止最大的模型,在超过 15 万亿个 token 上训练 Llama 3.1 405B 是一项重大挑战。为了在合理的时间内完成如此大规模的训练运行并取得这样的结果,Meta 对整个训练堆栈进行了大幅优化,并将模型训练推送到 1.6 万多个 H100 GPU 上,使 405B 成为第一个以如此规模训练的 Llama 模型。
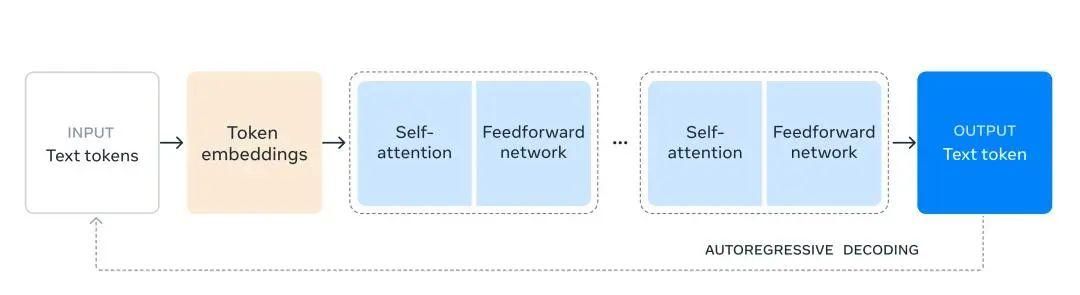
为了解决这个问题,Meta 在设计时选择了保持模型开发过程的可扩展性和直接性(straightforward)。为了最大限度地提高训练的稳定性,他们选择了标准的仅解码器 transformer 模型架构,并作了较小的调整,而没有采用混合专家模型。
他们采用了迭代后训练程序,每一轮都使用监督微调和直接偏好优化。这使得他们能够为每一轮训练创建最高质量的合成数据,并提高每种能力的性能。与以前版本的 Llama 相比,Meta 改进了预训练和后训练所用数据的数量和质量。
这些改进包括为预训练数据开发了更细致的预处理和整理管道,为后训练数据开发了更严格的质量保证和过滤方法。正如语言模型的缩放规律所预期的那样,Llama 3.1 405B 优于使用相同程序训练的较小模型。他们还利用 Llama 3.1 405B 提高了小型模型的后期训练质量。为了支持 Llama 3.1 405B 的大规模生产推理,他们将模型从 16 位(BF16)量化为 8 位(FP8)数值,有效降低了所需的计算要求,使模型可以在单个服务器节点内运行。
开放推动创新
Meta 在官方博客中写道,与封闭的模型不同,Llama 模型权重可供下载。
开发人员可以完全根据自己的需求和应用定制模型,在新的数据集上进行训练,并进行额外的微调。
这使得更广泛的开发者社区和全世界都能更充分地发挥生成式人工智能的能力。开发人员可以根据自己的应用进行完全定制,并在任何环境中运行,包括预置环境、云环境,甚至是笔记本电脑上的本地环境,而无需与 Meta 共享数据。
Meta 也表示,虽然很多人可能会认为封闭模型更具成本效益,但根据 Artificial Analysis 的测试,Llama 模型的单位 token 成本在业内最低。正如 Mark Zuckerberg 所指出的那样,开源将确保全世界更多的人能够享受到人工智能带来的好处和机会,确保权力不会集中在少数人手中,确保这项技术能够在全社会范围内得到更均衡、更安全的部署。
高性价比GPU算力:https://www.ucloud.cn/site/active/gpu.html?ytag=gpu_wenzhang_0729_shemei















 4832
4832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









