







C++中字符有所谓宽窄之分,其中窄字符(narrowchar)就是用8bit来表示的字符,最典型的就是ASCII码。而宽字符(wide char)在Windows中用16bit表示,在Linux中则占用32bit,典型的有UNICODE。
关于宽字符,百科如是说。
| 宽字符是双字节多语言字符代码。在当今的全球计算业内使用的大多数字符(包括技术符号和特殊的发布字符),都可以根据 Unicode 规范表示为宽字符形式。无法以 1 个宽字符表示的字符可以通过 Unicode 的代理项功能以 Unicode 对表示。由于每个宽字符总是以固定的 16 位大小表示,因此使用宽字符可以简化使用国际字符集进行的编程。
宽字符字符串表示为一个 wchar_t[] 数组并由 wchar_t* 指针指向它。可以通过用字母 L 作为字符的前缀将任何 ASCII 字符表示为宽字符形式。例如,L'\0' 是终止宽(16 位)NULL 字符。同样,可以通过用字母 L 作为 ASCII 字符串的前缀 (L"Hello") 将任何 ASCII 字符串表示为宽字符字符串形式。
通常,宽字符在内存中占用的空间比多字节字符多,但处理速度更快,因为很多系统的内核包括Windows NT内核都是从底层向上使用Unicode编码的。另外,在多字节编码中一次只能表示一个区域设置,Unicode编码可以毫无障碍地在世界上任何书面语言的字符中转换。 |
为了说明这narrow&wide二者在编码上的区别,本文先引入一个bug,业务背景是这样的——在一台主机名包含中文的Windows机器上安装被测软件client端,安装成功后在软件support dialog中发现主机名显示为乱码。
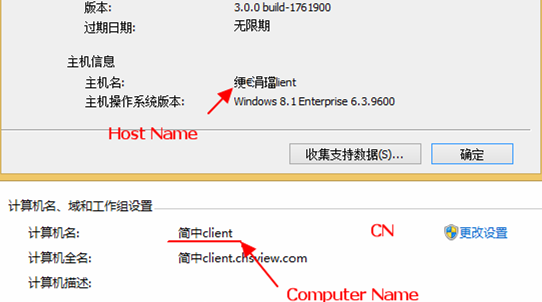
关于support dialog的示意代码块如下。
CString
SupportDialog::GetHostName()
const
{
char *hostname = CdkClientInfo_GetHostname();
CString str = CString (hostname);
g_free(hostname);
return str;
} 读到这里,其实就可以将该问题定位在UTF-8 char*向CString宽字符的转化问题上了。
关于char*和CString,简单介绍如下。
char* 是一个指向字符的指针,是一个内置类型。可以指向一个字符,也可以表示字符数组的首地址(首字符的地址)。更多的时候是用的它的第二个功能来表示一个字符串,功能与字符串数组 char ch[n] 一样,表示字符串时,最后有一个 '\0'结束符作为字符串的结束标志.
CString(typedef CStringT> CString) 为 MFC中最常用的字符串类,极大地简化了字符串操作。他继承自 CSimpleStringT,主要应用在 MFC 和ATL 编程中,使用CString 时要#include afx.h文件
为了解决该问题,本文引入两个工具方法。
CString
UTF8ToCString(constchar *utf8Str) // IN: UTF8 string to convert to UTF16
{
std::vector<wchar_t> utf16Str;
if (ConvertUTF8ToUTF16(utf8Str, utf16Str)) {
return &utf16Str[0];
} else {
return _T("");
}
}
bool
ConvertUTF8ToUTF16(constchar *utf8Str, // IN:
std::vector<wchar_t>&utf16Str) // OUT:
{
int len = MultiByteToWideChar(CP_UTF8, 0,utf8Str, -1, NULL, 0);
if (len > 0) {
utf16Str.resize(len);
if (MultiByteToWideChar(CP_UTF8, 0,utf8Str, -1, &utf16Str[0], len)) {
return true;
}
}
return false;
}修改之前hostname的代码为CString str = UTF8ToCString(hostname);再次进行测试,问题解决!















 595
595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









