







目录
(2)、虚拟变量/哑变量 ( Dummy Variables)
(一)、什么是特征
在机器学习和模式识别中,特征是被观测对象的可测量性能或特性。在模式识别、分类和回归中,信息特征的选择、判别和独立特征的选择是有效算法的关键步骤。特征通常是数值型的,但语法模式识别可以使用结构特征(如字符串和图)。“特征”的概念与线性回归等统计技术中使用的解释变量有关。
(二)、特征分类
特征也就是我们常常说的变量/自变量,一般分为三类:
无序类别(离散)型
有序类别(离散)型
连续型
(三)、空值处理
1、去掉缺失值
处理缺失值最简单的手段无疑是直接将带有缺失值的特征(列)或样本(行)从数据集中去掉。去掉行可以通过dropna方法:df.dropna()
详细python代码如下:
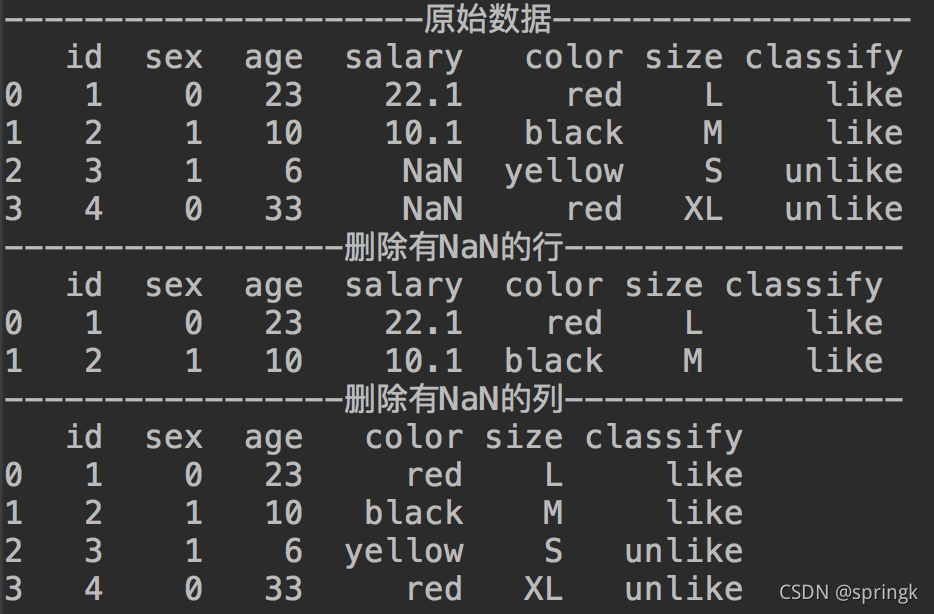
print('---------------------原始数据------------------')
path = './example.csv'
dataset=pd.read_csv(path,encoding='utf-8',sep='\t',header=0,engine='python') #参数为源文件,编码,分隔符
print(dataset)
print('-----------------删除有NaN的行-----------------')
dataset_no_na_row = dataset.dropna()
print(dataset_no_na_row)
print('-----------------删除有NaN的列-----------------')
dataset_no_na_colm = dataset.dropna(axis=1)
print(dataset_no_na_colm)结果信息如下:
另外也可以根据实际需求使用how、thresh参数(how="all"表示滤除全为NaN的行、thresh=n表示保留至少有n个非NaN数据的行)
2、改写缺失值
上面处理缺失值的缺点很明显,过于暴力,会丢掉很多数据信息。怎样保留那些非缺失值数据的同时处理缺失值呢?这就是插入法,用一个估计值来替代缺失值。最常用的是平均估计法,即用整个特征列的平均值代替这一列的缺失值。
详细python代码如下:
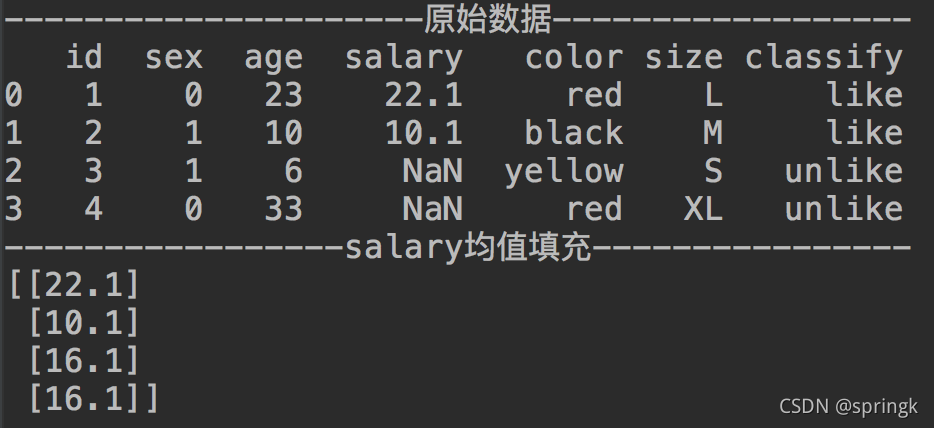
print('-----------------salary均值填充----------------')
imp_mean = SimpleImputer(missing_values=np.nan, strategy='mean', verbose=0)
dataset_imputer = imp_mean.fit_transform(dataset.loc[:, ['salary']])
print(dataset_imputer)结果信息如下:
当然使用SimpleImputer的同时。可以改变strategy对应的策略。目前支持如下四种方法:
"mean,使用该列的平均值替换缺失值。仅用于数值数据;
“median”,使用该列的中位数替换缺失值。仅用于数值数据;
“most_frequent”,使用每个列中最常见的值替换缺失值。可用于非数值数据;
“constant”,用fill_value替换缺失值。可用于非数值数据。
(四)、处理分类数据
分类数据分为有序和无序两种,针对这两种方式处理方式也不同。拿衣服尺寸为例,S、M、L尺寸是有次序的递增,可以直接映射为数字1、2、3……,但是衣服的颜色红色、黄色、蓝色这些色彩时,本身不存在相对的次序,如果映射成1、2、3的数字,就和原始的意义有偏差,影响了对应的特征计算准确性,基于此,针对有序、无序的分类数据处理方式也不相同。
1、映射有序特征
自定义编码
为了保证学习算法能够正确解释有序特征,我们需要将分类型字符串转为整型数值。不幸地是,并没有能够直接调用的方法来自动得到正确顺序的size特征。因此,我们要自己定义映射函数。在接下来的简单的示例,假设我们知道特征取值间的不同,比如 XL=L+1=M+2。
python代码实现方式:
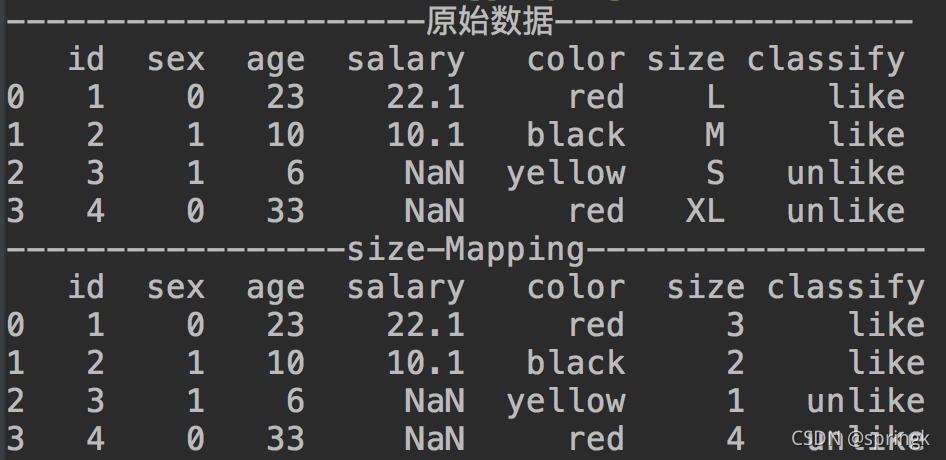
size_mapping = {'S':1,"M":2,"L":3,"XL":4}
dataset['size'] = dataset['size'].map(size_mapping)
print('-----------------size-Mapping-----------------')
print(dataset)结果信息如下:
2、对类别进行编码
上面是我们自己手动创建的映射字典,sklearn中提供了LabelEncoder类来实现类别的转换
python代码实现:
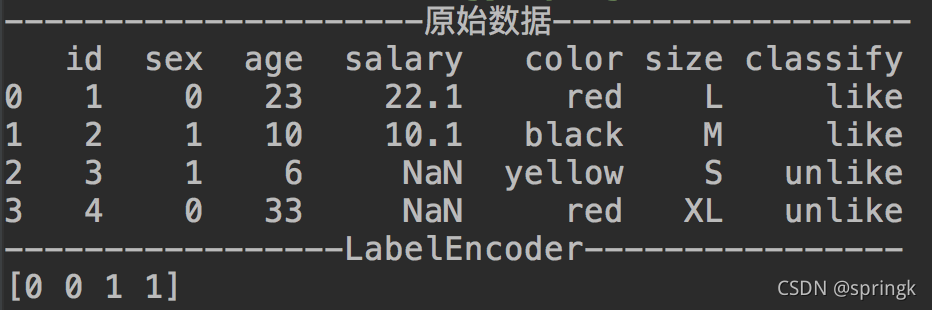
classLe = LabelEncoder()
dataset_cle = classLe.fit_transform(dataset.loc[:, ['classify']])
print('-----------------LabelEncoder----------------')
print(dataset_cle)结果信息如下:
3、无序离散特征
示例中,我们关注一下颜色这个属性,不同的颜色如果按照自定义编码设置成1、2、3,那这就犯了大错,当转换为数字之后,学习算法会认为‘green’比‘blue’大,‘red’比‘green’大。而这显然是不正确的,因为本身颜色是无序的!模型错误的使用了颜色特征信息,最后得到的结果肯定不是我们想要的。那么如何处理无序离散特征呢?下面给出一些方式:
(1)、独热编码
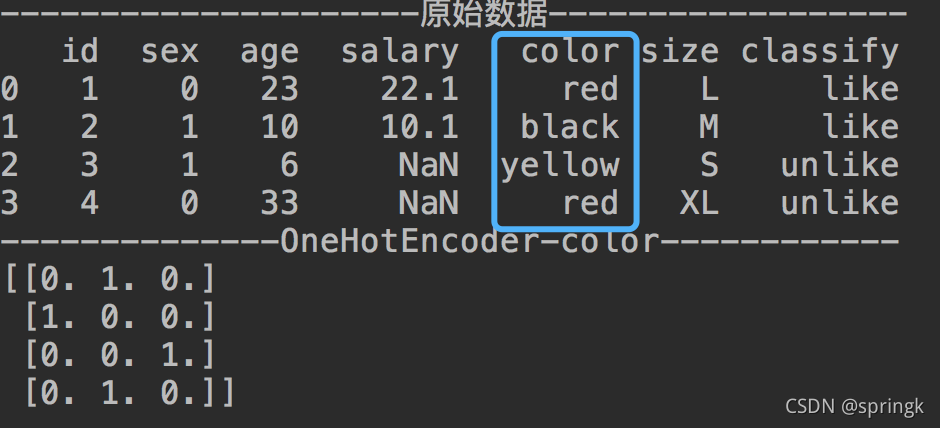
独热编码即One-Hot 编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。
在sklearn中,可以调用OneHotEncoder来实现独热编码:
ohe = OneHotEncoder() # 初始化独热编码
dataset_ohe = ohe.fit_transform(dataset.loc[:, ['color']]).toarray() # 拟合
print('--------------OneHotEncoder-color------------')
print(dataset_ohe)结果信息如下:
(2)、虚拟变量/哑变量 ( Dummy Variables)
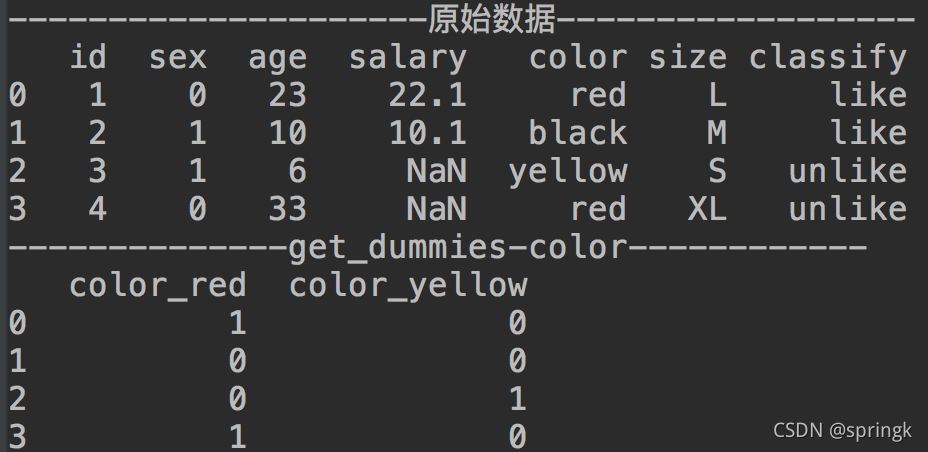
哑变量(Dummy Variable),又称为虚拟变量、虚设变量或名义变量,从名称上看就知道,它是人为虚设的变量,通常取值为0或1,来反映某个变量的不同属性。对于有n个分类属性的自变量,通常需要选取1个分类作为参照,因此可以产生n-1个哑变量。
oht = pd.get_dummies(dataset.loc[:, ['color']],prefix=None, prefix_sep='_', dummy_na=False,columns=None,sparse=False, drop_first=True, dtype=None)
print('--------------get_dummies-color------------')
print(oht)结果信息如下:
(1) prefix:表示列名的前缀,默认为None。
(2) prefix_sep:用于附加前缀作为分隔符使用,默认为“_”。
(3) dummy_na:表示是否为NaN值添加一列,默认为False。
(4) columns:表示DataFrame要编码的列名,默认为None。
(5) sparse:表示虚拟列是否是稀疏的,默认为False。
(6) drop_first:是否通过从k个分类级别中删除第一个级来获得k-1个分类级别,默认为False。
get_dummies使用drop_first参数,完成哑变量的信息
(3)、独热编码和虚拟变量区别:
独热编码( One Hot Encoding)比虚拟变量(Dummy Variable)多生成了一个变量。
1,如果有N个特征,已知前N-1个特征的特征值之后,第N个特征的特征值也就知道了,因此独热编码有冗余,虚拟变量没有冗余;
2,独热编码可以直接从激活状态看出所对应的类别,而虚拟变量需要进行推论,因此独热编码比较直观,虚拟变量没有那么直观。
(五)、特征缩放
特征缩放(feature scaling): 改变特征的取值范围,缩放到统一的区间,例如[ 0 , 1 ]
为什么要进行特征缩放?
数据集包含众多特征,每个特征的尺度(scale)不同,有的特征的单位是小时,有的特征的单位是公里,尺度不同也意味着变化的范围不同,有的特征的波动非常大,有的非常小。对大部分机器学习算法而言,特征取值越大或波动越大,在模型中获得的权重就越大,结果导致预测精度降低,最好的处理办法是将所有特征的尺度缩放到统一的区间。
特征缩放方式:
1、调节比例
这种方法是将数据的特征缩放到[0,1]或[-1,1]之间。缩放到什么范围取决于数据的性质
2、标准化
特征标准化使每个特征的值有零均值(zero-mean)和单位方差(unit-variance)。这个方法在机器学习地算法中被广泛地使用。
3、实现方式
sklearn提供了几个通用的接口:
- MinMaxScaler
- RobustScaler
- StandardScaler
(六)、数据变换方式
在进行数据预处理中经常用到数据变换,通过相应的变换操作,能够将数据变换到正态分布中,消除数据之间的量纲问题,使数据看起来更加的规整,这样建模得出来的结果才会更准确。
1、z-score变换
z-score变换通常用于将数据变换为正态分布,因为一般的统计分析方法都在假设数据服从正态分布,所有有的模型要求输入数据需为正态分布,遇到这类的模型时需要应用z-score变换
iris =load_iris()
iris_x = iris['data']
#z-score
standar_scaler = StandardScaler()
standar_scaler.fit(iris_x)
iris_x_scala1 = standar_scaler.transform(iris_x)
print('--------------z-score : test1------------')
print(iris_x_scala1)
#z-score
iris_x_scala2 = scale(iris_x)
print('--------------z-score : test2------------')
print(iris_x_scala2)2、对数变换
对数变换能够缩小数据的绝对范围,取乘法操作相当于对数变换后的加法操作。
iris_log = FunctionTransformer(log1p).fit_transform(iris)
print(iris_log)3、box-cox变换
box-cox变换是统计建模中常用的数据变换方法,用于连续的响应变量不满足正态分布的情况。Box-Cox变换之后,可以一定程度上减小不可观测的误差和预测变量的相关性。
Python中的scipy.stats.boxcox() 定义了boxcox变换,直接调用该函数实现。
参考文章:
Python机器学习实战:特征缩放的3个方法_数据工程与机器学习的博客-CSDN博客_python特征缩放
虚拟变量和独热编码的区别(Difference of Dummy Variable & One Hot Encoding)_weixin_30273931的博客-CSDN博客
数据挖掘中常用的数据变换方法总结 - 知乎
example.csv文件内容:

python文件内容如下:
import pandas as pd
import numpy as np
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
from sklearn.datasets import load_iris
from sklearn.preprocessing import scale,StandardScaler
from sklearn.preprocessing import FunctionTransformer
from numpy import log1p
print('---------------------原始数据------------------')
path = './example.csv'
dataset=pd.read_csv(path,encoding='utf-8',sep='\t',header=0,engine='python') #参数为源文件,编码,分隔符
print(dataset)
print('-----------------删除有NaN的行-----------------')
dataset_no_na_row = dataset.dropna()
print(dataset_no_na_row)
print('-----------------删除有NaN的列-----------------')
dataset_no_na_colm = dataset.dropna(axis=1)
print(dataset_no_na_colm)
print('-----------------salary均值填充----------------')
imp_mean = SimpleImputer(missing_values=np.nan, strategy='mean', verbose=0)
dataset_imputer = imp_mean.fit_transform(dataset.loc[:, ['salary']])
print(dataset_imputer)
size_mapping = {'S':1,"M":2,"L":3,"XL":4}
dataset['size'] = dataset['size'].map(size_mapping)
print('-----------------size-Mapping-----------------')
print(dataset)
classLe = LabelEncoder()
dataset_cle = classLe.fit_transform(dataset.loc[:, ['classify']])
print('-----------------LabelEncoder----------------')
print(dataset_cle)
ohe = OneHotEncoder() # 初始化独热编码
dataset_ohe = ohe.fit_transform(dataset.loc[:, ['color']]).toarray() # 拟合
print('--------------OneHotEncoder-color------------')
print(dataset_ohe)
oht = pd.get_dummies(dataset.loc[:, ['color']],prefix=None, prefix_sep='_', dummy_na=False,columns=None,
sparse=False, drop_first=True, dtype=None)
print('--------------get_dummies-color------------')
print(oht)
# 测试数据
iris =load_iris()
iris_x = iris['data']
#z-score
standar_scaler = StandardScaler()
standar_scaler.fit(iris_x)
iris_x_scala1 = standar_scaler.transform(iris_x)
print('--------------z-score : test1------------')
print(iris_x_scala1)
#z-score
iris_x_scala2 = scale(iris_x)
print('--------------z-score : test2------------')
print(iris_x_scala2)
iris_log = FunctionTransformer(log1p)
print('--------------对数变换------------')
print(iris_log)

















 1230
1230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











