






论文标题:Tri-Perspective View for Vision-Based 3D Semantic Occupancy Prediction
论文链接:https://arxiv.org/abs/2302.07817
代码链接:https://github.com/wzzheng/TPVFormer
前言
准确、全面地感知3D环境在自动驾驶系统中起着重要的作用。3D环形感知的核心在于如何有效地表示3D场景。
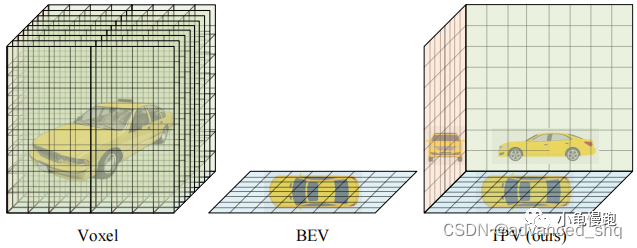
传统的方法将3D空间分割成体素,并为每个体素分配一个向量作为体素的特征。虽然体素表示的准确率很高,但它的存储成本和计算成本太大而且还需要专门的技术比如稀疏卷积。
在3D空间中,高度维度所包含的信息少于其他两个维度,现代的方法主要关注信息变化最大的地平面(鸟瞰图),它们在每个BEV网格的向量表示中隐式的编码3D信息。虽然BEV表示比体素表示效率高,但忽略高度维度的信息对它的表达性有不利影响,使得它很难描述场景中的细粒度3D结构。(作者认为,基于BEV的方法在3D目标检测中的性能好是由于3D目标检测只需要对常见的物体进行粗粒度的边界框预测。)
为了实现一个更安全、更健壮的以视觉为中心的自动驾驶系统,需要有对3D环境更全面、更精细的表示。为了解决这个问题,作者提出了TPV表示来描述3D场景,并进一步提出了一种基于transformer的TPV encoder(TPVFormer)来有效地得到TPV特征。
架构
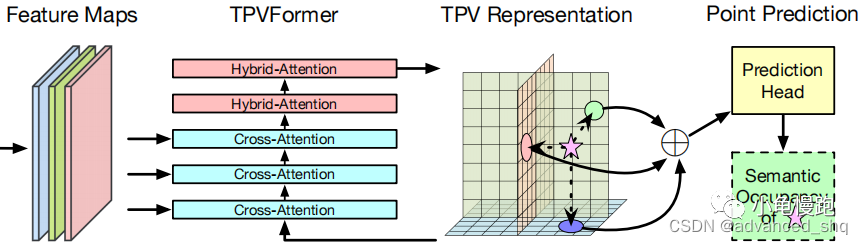
TPVFormer中引入了TPV queries, image cross attention(ICA)和cross view hybrid attention(CVHA)来有效地生成TPV平面。TPV queries和TPV平面指的是同一组特征向量。每个TPV query
t
∈
T
t\in T
t∈T 是TPV平面上的网格单元特征,用来编码对应柱状区域的信息。TPV queries使用CVHA获取上下文信息,使用ICA获取图像特征中的信息。
文中进一步提出的两种块:hybrid cross attention block(HCAB)和hybrid attention block(HAB)。HCAB由ICA和CVHA组成,用于TPVFormer的前半部分,可以有效地从图像特征中查询视觉信息。HAB只包含CVHA,专门进行上下文信息编码。
TPV Queries
TPV queries和TPV平面指的是同一组特征向量,但是他们的含义不同,前者用于注意力,后者用于上下文的表示。
T
=
[
T
H
W
,
T
D
H
,
T
W
D
]
,
T
H
W
∈
R
H
×
W
×
C
,
T
D
H
∈
R
D
×
H
×
C
,
T
W
D
∈
R
W
×
D
×
C
\begin{aligned} T = [T^{HW}, T^{DH}, T^{WD}], T^{HW}\in\mathbb{R}^{H\times W\times C}, T^{DH}\in\mathbb{R}^{D\times H\times C}, T^{WD}\in\mathbb{R}^{W\times D\times C} \end{aligned}
T=[THW,TDH,TWD],THW∈RH×W×C,TDH∈RD×H×C,TWD∈RW×D×C
每个TPV query表示相应平面
s
×
s
m
2
s\times s\ m^2
s×s m2的2D网格单元和与该网格单元垂直正交的3D柱状区域。TPV queries首先聚合HCAB中的图像特征,然后在使用HAB进行优化。
具体实现的时候,将TPV queries初始化为一组可学习参数,并在第一个编码器层之前添加3D位置编码。
ICA(Image Cross Attention)
为了降低计算成本,ICA是基于deformable attention实现的。
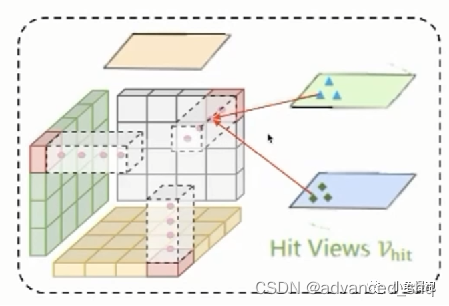
取top平面上位于(h, w)处的TPV query
t
h
,
w
t_{h,w}
th,w。首先,使用
P
h
w
−
1
\mathcal{P}_{hw}^{-1}
Phw−1计算该点投影到真实世界中的坐标,沿着平面的正交方向均匀采
N
r
e
f
H
W
N_{ref}^{HW}
NrefHW个点,得到真实世界中的坐标点
R
e
f
h
,
w
w
o
r
l
d
Ref_{h,w}^{world}
Refh,wworld。
(
x
,
y
)
=
P
h
w
−
1
(
h
,
w
)
=
(
(
h
−
H
2
)
×
s
,
(
w
−
W
2
)
×
s
)
R
e
f
h
,
w
w
o
r
l
d
=
(
P
h
w
−
1
(
h
,
w
)
,
Z
)
=
{
(
x
,
y
,
z
i
)
}
i
=
1
N
r
e
f
H
W
\begin{aligned} (x,y) = \mathcal{P_hw^{-1}}(h,w) = ((h - \frac{H}{2})\times s,(w - \frac{W}{2})\times s) \\ Ref_{h,w}^{world} = (\mathcal{P_hw^{-1}}(h,w), Z) = \{(x,y,z_i)\}_{i=1}^{N_{ref}^{HW}} \end{aligned}
(x,y)=Phw−1(h,w)=((h−2H)×s,(w−2W)×s)Refh,wworld=(Phw−1(h,w),Z)={(x,y,zi)}i=1NrefHW
然后,将真实世界中的坐标点使用
P
p
i
x
\mathcal{P}_{pix}
Ppix投影到图片特征上,得到像素坐标点
R
e
f
h
,
w
p
i
x
Ref_{h,w}^{pix}
Refh,wpix。
R
e
f
h
,
w
p
i
x
=
P
p
i
x
(
R
e
f
h
,
w
w
o
r
l
d
)
=
P
p
i
x
(
{
(
x
,
y
,
z
i
)
}
)
\begin{aligned} Ref_{h,w}^{pix} = \mathcal{P}_{pix}(Ref_{h,w}^{world}) = \mathcal{P}_{pix}(\{(x,y,z_i)\}) \end{aligned}
Refh,wpix=Ppix(Refh,wworld)=Ppix({(x,y,zi)})
最后,通过线性层计算偏移量和权重,求注意力得分加权和并更新TPV queries。
I
C
A
(
t
h
,
w
,
I
)
=
1
∣
N
h
,
w
v
a
l
∣
∑
j
∈
N
h
,
w
v
a
l
D
A
(
t
h
,
w
,
R
e
f
h
,
w
p
i
x
,
j
,
I
j
)
\begin{aligned} ICA(t_{h,w}, I) = \frac{1}{|N_{h,w}^{val}|}\sum_{j\in N_{h,w}^{val}}DA(t_{h,w}, Ref_{h,w}^{pix,j},I_j) \end{aligned}
ICA(th,w,I)=∣Nh,wval∣1j∈Nh,wval∑DA(th,w,Refh,wpix,j,Ij)
CVHA(Cross View Hybrid Attention)
同样,为了降低计算成本,CVHA也是基于deformable attention实现的。
取top平面上位于(h, w)处的TPV query
t
h
,
w
t_{h,w}
th,w,其参考点是由top面、side面和front面的参考点组成。
R
h
,
w
=
R
h
,
w
t
o
p
∪
R
h
,
w
s
i
d
e
∪
R
h
,
w
f
r
o
n
t
R_{h,w} = R_{h,w}^{top} \cup R_{h,w}^{side} \cup R_{h,w}^{front}
Rh,w=Rh,wtop∪Rh,wside∪Rh,wfront
首先,在top平面上的(h, w)位置附近随机取几个点作为 R h , w t o p R_{h,w}^{top} Rh,wtop。
然后,从(h, w)点处,沿着top平面的正交方向均匀地采点,并将它们投影到side面和front面,分别得到参考点
R
h
,
w
s
i
d
e
R_{h,w}^{side}
Rh,wside和
R
h
,
w
f
r
o
n
t
R_{h,w}^{front}
Rh,wfront。
R
h
,
w
s
i
d
e
=
{
(
d
i
,
h
)
}
i
,
R
h
,
w
f
r
o
n
t
=
{
(
w
,
d
i
)
}
i
R_{h,w}^{side} = \{(d_i, h)\}_i, R_{h,w}^{front} = \{(w, d_i)\}_i
Rh,wside={(di,h)}i,Rh,wfront={(w,di)}i
最后,通过线性层计算偏移量和权重,求注意力得分加权和并更新TPV queries。
C
V
H
A
(
t
h
,
w
)
=
D
A
(
t
h
,
w
,
R
h
,
w
,
T
)
CVHA(t_{h,w}) = DA(t_{h,w}, R_{h,w}, T)
CVHA(th,w)=DA(th,w,Rh,w,T)
TPV的应用
TPV表示可以有效地描述3D场景的细粒度结构,然而,目前没有支持TPV表示的检测头。作者将TPV表示转换成了点特征和体素特征。
Point Feature

对于任意给定的现实世界的位置。首先将这些点投影到TPV的三个平面,检索对应的特征 [ t h , w , t d , h , t w , d ] [t_{h,w},t_{d,h},t_{w,d}] [th,w,td,h,tw,d],并求和得到该位置处的特征。
t
h
,
w
=
S
(
T
H
W
,
(
h
,
w
)
)
=
S
(
T
H
W
,
P
h
w
(
x
,
y
)
)
t
d
,
h
=
S
(
T
D
H
,
(
d
,
h
)
)
=
S
(
T
D
H
,
P
d
h
(
z
,
x
)
)
t
w
,
d
=
S
(
T
W
D
,
(
w
,
d
)
)
=
S
(
T
W
D
,
P
w
d
(
y
,
z
)
)
f
x
,
y
,
z
=
A
(
t
h
,
w
,
t
d
,
h
,
t
w
,
d
)
\begin{aligned} &t_{h,w} = \mathcal{S}(T^{HW}, (h,w)) = \mathcal{S}(T^{HW}, \mathcal{P}_{hw}(x,y)) \\ &t_{d,h} = \mathcal{S}(T^{DH}, (d,h)) = \mathcal{S}(T^{DH}, \mathcal{P}_{dh}(z,x)) \\ &t_{w,d} = \mathcal{S}(T^{WD}, (w,d)) = \mathcal{S}(T^{WD}, \mathcal{P}_{wd}(y,z)) \\ \\ &f_{x,y,z} = \mathcal{A}(t_{h,w}, t_{d,h}, t_{w,d}) \end{aligned}
th,w=S(THW,(h,w))=S(THW,Phw(x,y))td,h=S(TDH,(d,h))=S(TDH,Pdh(z,x))tw,d=S(TWD,(w,d))=S(TWD,Pwd(y,z))fx,y,z=A(th,w,td,h,tw,d)
P
\mathcal{P}
P:投影函数,将真实世界的坐标点投影成TPV平面上的坐标点
S \mathcal{S} S:取样函数,获取TPV平面坐标点处的特征
A \mathcal{A} A:聚合函数,聚合三个平面的特征作为真实世界点的特征
Voxel Feature
沿着正交方向广播每个TPV平面,产生三个相同大小的 H × W × D × C H\times W\times D\times C H×W×D×C特征张量,求和得到体素特征。
结论
作者提出了TPV表示方法,能够有效地描述3D场景的细粒度结构。为了将图像提升到TPV空间,进一步提出了基于注意力机制的TPVFormer模型。
可视化结果表明,采用稀疏监督训练的模型可以有效地预测所有体素的语义占用率,并首次证明了,在nuScenes的LiDAR分割任务上,基于视觉的方法可以获得与基于LiDAR的方法相当的性能。
















 963
963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









