






 AnchorDETR提出了一种基于锚点的objectqueries设计,解决了传统Transformer检测器中query缺乏物理意义的问题。通过位置编码和多模式设计,模型能在一个位置预测多个目标。此外,Row-ColumnDecoupledAttention(RCDA)降低了内存消耗,同时保持了与DETR相当的性能。
AnchorDETR提出了一种基于锚点的objectqueries设计,解决了传统Transformer检测器中query缺乏物理意义的问题。通过位置编码和多模式设计,模型能在一个位置预测多个目标。此外,Row-ColumnDecoupledAttention(RCDA)降低了内存消耗,同时保持了与DETR相当的性能。
论文标题:Anchor DETR: Query Design for Transformer-Based Object Detection
论文链接:https://arxiv.org/abs/2109.07107
代码链接:https://github.com/megvii-research/AnchorDETR
前言
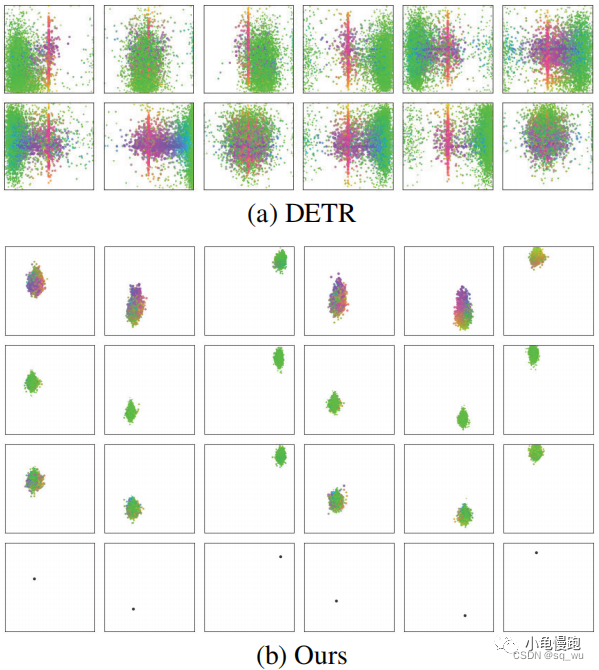
以前基于Transformer的检测器,object queries是一组可学习embeddings。但是,每个学习到的embedding并没有明确的物理意义,它们并没有聚焦于特定的区域。
为了解决这个问题,本文作者提出了基于锚点的object queries设计,而且,支持一个位置预测多个目标。此外,还设计了一种注意力变种,在降低了内存消耗的同时,保持性能与DETR中注意力持平或更好。
网络架构
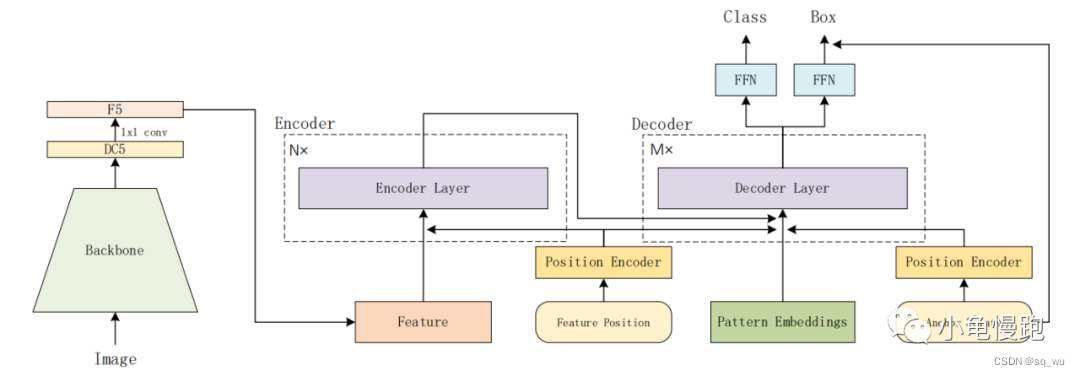
核心组件:
Feature Position Encoder:基于sine、cosine生成位置编码,在使用MLP微调Pattern Embeddings:支持一个位置多个目标Anchor Points Position Encoder:基于锚点生成query的位置编码
Backbone
使用resnet50返回DC5(Dilated Conv5)特征地图,经过1x1卷积生成最终的特征图。
# 1x1卷积
self.input_proj = nn.ModuleList([
nn.Sequential( # 2048 -> 256
nn.Conv2d(backbone.num_channels[0], hidden_dim, kernel_size=1),
nn.GroupNorm(32, hidden_dim),
)])
# resnet50 DC5(dilated C5 feature) 2048
features = self.backbone(samples)
# 1x1卷积生成最终特征地图 F5
srcs.append(self.input_proj[l](src).unsqueeze(1))
Position Encoder
Transformer中,使用不同频率的正弦和余弦函数生成位置编码。
# 使用sine、cosine函数生成位置编码
def pos2posemb1d(pos, num_pos_feats=256, temperature=10000):
scale = 2 * math.pi
pos = pos * scale
dim_t = torch.arange(num_pos_feats, dtype=torch.float32, device=pos.device)
dim_t = temperature ** (2 * (dim_t // 2) / num_pos_feats)
pos_x = pos[..., None] / dim_t
posemb = torch.stack((pos_x[..., 0::2].sin(), pos_x[..., 1::2].cos()), dim=-1).flatten(-2)
return posemb
公式如下:
P
E
(
p
o
s
,
2
i
)
=
s
i
n
(
p
o
s
1000
0
2
i
d
m
o
d
e
l
)
P
E
(
p
o
s
,
2
i
+
1
)
=
c
o
s
(
p
o
s
1000
0
2
i
d
m
o
d
e
l
)
PE_{(pos, 2i)} = sin(\frac{pos}{10000^{\frac{2i}{d_{model}}}}) \\ PE_{(pos, 2i+1)} = cos(\frac{pos}{10000^{\frac{2i}{d_{model}}}})
PE(pos,2i)=sin(10000dmodel2ipos)PE(pos,2i+1)=cos(10000dmodel2ipos)
本文对位置编码做了调整,使用正弦和余弦函数生成位置编码后,又使用一个MLP网络对位置编码进行调整。
# MLP对位置编码进行微调
self.adapt_pos1d = nn.Sequential(
nn.Linear(d_model, d_model),
nn.ReLU(),
nn.Linear(d_model, d_model),
)
# 生成行位置编码
posemb_row = self.adapt_pos1d(pos2posemb1d(pos_row))
Encoder
Transformer内存消耗大,无法使用高分辨率特征。Deformable Transformer可以降低内存消耗,但是采点数据未连续存放,影响读取性能。一些其他的具有线性复杂度的注意力模块,如Luna、Efficient attention,它们虽然不会对内存随机访问,但是,实验结果发现,这些注意力模块不能很好的处理类DETR的检测器。(It may be because the cross-attention in the DETR-like decoder is much difficult than the self-attention.)
本文作者提出了Row-Column Decoupled Attention(RCDA),它可以在降低内存消耗的同时,保持与DETR中标准的注意力相似或更好的性能。
RCDA的主要思想是通过1D全局平均池化将键特征
K
f
∈
R
H
×
W
×
C
K_f \in R^{H \times W \times C}
Kf∈RH×W×C拆分成行特征
K
f
,
x
∈
R
W
×
C
K_{f,x} \in R^{W \times C}
Kf,x∈RW×C和列特征
K
f
,
y
∈
R
H
×
C
K_{f,y} \in R^{H \times C}
Kf,y∈RH×C。
# 拆分键的行列特征
k_row = K_row.mean(1)
k_col = k_col.mean(2)
然后,依次执行行列注意力。
# 计算行列注意力权重Ax,Ay
scaling = float(head_dim) ** -0.5
q_row = q_row * scaling
q_col = q_col * scaling
attn_output_weights_row = torch.bmm(q_row, k_row.transpose(1, 2))
attn_output_weights_col = torch.bmm(q_col, k_col.transpose(1, 2))
attn_output_weights_col = softmax(attn_output_weights_col, dim=-1)
attn_output_weights_row = softmax(attn_output_weights_row, dim=-1)
# Z=Ax*V
attn_output_row = torch.matmul(attn_output_weights_row,v)
# Out=A_y*Z
attn_output = torch.matmul(attn_output_weights_col,attn_output_row)
行列注意力计算公式如下:
A
x
=
s
o
f
t
m
a
x
(
Q
x
K
x
T
d
k
)
,
A
x
∈
R
N
q
×
W
Z
=
w
e
i
g
h
t
e
d
_
s
u
m
W
(
A
x
,
V
)
,
Z
∈
R
N
q
×
H
×
C
A
y
=
s
o
f
t
m
a
x
(
Q
y
K
y
T
d
k
)
,
A
y
∈
R
N
q
×
H
O
u
t
=
w
e
i
g
h
t
e
d
_
s
u
m
H
(
A
y
,
Z
)
,
O
u
t
∈
R
N
q
×
C
A_x = softmax(\frac{Q_xK_x^T}{\sqrt{d_k}}), A_x \in R^{N_q \times W} \\ Z = weighted\_sumW(A_x, V), \ Z \in R ^{N_q \times H \times C} \\ A_y = softmax(\frac{Q_yK_y^T}{\sqrt{d_k}}), \ A_y \in R^{N_q \times H} \\ Out = weighted\_sumH(A_y, Z), \ Out \in R ^{N_q \times C}
Ax=softmax(dkQxKxT),Ax∈RNq×WZ=weighted_sumW(Ax,V), Z∈RNq×H×CAy=softmax(dkQyKyT), Ay∈RNq×HOut=weighted_sumH(Ay,Z), Out∈RNq×C
其中:
Q
x
=
Q
f
+
Q
p
,
x
,
Q
y
=
Q
f
+
Q
p
,
y
Q
p
,
x
=
g
1
D
(
P
o
s
q
,
x
)
,
Q
p
,
y
=
g
1
D
(
P
o
s
q
,
y
)
K
x
=
K
f
,
x
+
K
p
,
x
,
K
y
=
K
f
,
y
+
K
p
,
y
K
p
,
x
=
g
1
D
(
P
o
s
k
,
x
)
,
K
p
,
y
=
g
1
D
(
P
o
s
k
,
y
)
V
=
V
F
,
V
∈
R
H
×
W
×
C
Q_x = Q_f + Q_{p,x}, Q_y = Q_f + Q_{p,y} \\ Q_{p,x} = g_{1D}(Pos_{q,x}), Q_{p,y} = g_{1D}(Pos_{q,y}) \\ K_x = K_{f,x} + K_{p,x}, K_y = K_{f,y} + K_{p,y} \\ K_{p,x} = g_{1D}(Pos_{k,x}), K_{p,y} = g_{1D}(Pos_{k,y}) \\ V = V_F, V \in R^{H\times W\times C}
Qx=Qf+Qp,x,Qy=Qf+Qp,yQp,x=g1D(Posq,x),Qp,y=g1D(Posq,y)Kx=Kf,x+Kp,x,Ky=Kf,y+Kp,yKp,x=g1D(Posk,x),Kp,y=g1D(Posk,y)V=VF,V∈RH×W×C
在Encoder Layer中,以F5特征和行列位置编码为入参,使用RCDA做多头自注意力。
# 自注意力 src-F5 features; posemb_row - 行位置编码; posemb_col - 列位置编码
src2 = self.self_attn(src + posemb_row, src + posemb_col, src + posemb_row, src + posemb_col,
src, key_padding_mask=padding_mask)[0].transpose(0, 1).reshape(bz, h, w, c)
src = src + self.dropout1(src2) # self.dropout1 = nn.Dropout(dropout)
src = self.norm1(src) # self.norm1 = nn.LayerNorm(d_model)
# ffn
src = self.ffn(src) # self.ffn = FFN(d_model, d_ffn, dropout, activation)
Pattern Embeddings
每个锚点附近可能有多个目标,为了解决这个问题,本文作者对object queries进行改进,可以在每个锚点处预测多个目标。
以前初始化的object queries
Q
f
i
n
i
t
∈
R
N
q
×
C
Q_f^{init} \in R^{N_q \times C}
Qfinit∈RNq×C,其中每个query只有一种模式
Q
f
i
∈
R
1
×
C
Q_f^i \in R^{1 \times C}
Qfi∈R1×C。为了在每个锚点处预测多个目标,需要为每个query引入多种模式,即
Q
f
i
∈
R
N
p
×
C
Q_f^i \in R^{N_p \times C}
Qfi∈RNp×C。此时,
Q
f
i
n
i
t
∈
R
N
p
×
N
A
×
C
Q_f^{init} \in R^{N_p \times N_A \times C}
Qfinit∈RNp×NA×C,其中,
N
p
×
N
A
=
N
q
N_p \times N_A = N_q
Np×NA=Nq。(相当于以前的Q是900x256,现在的变成了3x300x256)
# 3, 256
self.pattern = nn.Embedding(self.num_pattern, d_model)
# object queries
# 由于平移不变性,每个object query的pattern的值应该是一样的
# For the property of translation invariance, the patterns are shared for all the object queries
tgt = self.pattern.weight.reshape(1, self.num_pattern, 1, c).repeat(bs, 1, self.num_position, 1).reshape(
bs, self.num_pattern * self.num_position, c)
Anchor Points
在基于Transformer的检测器中,锚点可以是可学习点、均匀网格点或其他手工锚点。本文作者选用了两种类型的锚点:可学习锚点和均匀网格锚点。
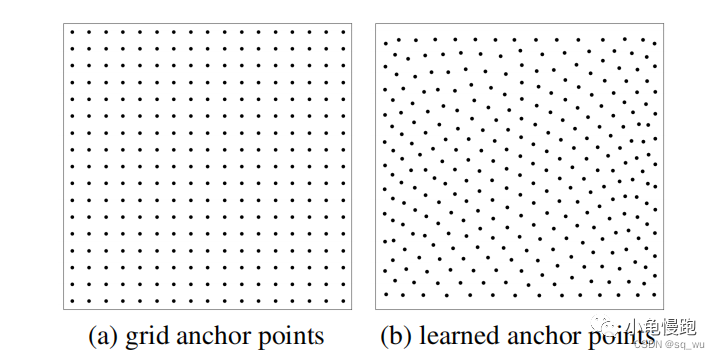
网格锚点是图像中均匀的网格点。
# 均匀网格锚点
nx=ny=round(math.sqrt(self.num_position))
self.num_position=nx*ny
x = (torch.arange(nx) + 0.5) / nx
y = (torch.arange(ny) + 0.5) / ny
xy=torch.meshgrid(x,y)
reference_points=torch.cat([xy[0].reshape(-1)[...,None],xy[1].reshape(-1)[...,None]],-1).cuda()
reference_points = reference_points.unsqueeze(0).repeat(bs, self.num_pattern, 1)
可学习锚点以0到1的均匀分布随机初始化。
# 可学习锚点
self.position = nn.Embedding(self.num_position, 2) # (300, 2)
# 0到1随机均匀分布
nn.init.uniform_(self.position.weight.data, 0, 1)
# 300个锚点,每个锚点3个模式 torch.Size([1, 900, 2])
reference_points = self.position.weight.unsqueeze(0).repeat(bs, self.num_pattern, 1)
Decoder中的
Q
p
Q_p
Qp(query embedding)被视为object query,它负责区分不同的对象。但是,很难解释它的物理意义。为了解决这个问题,本文作者提出了基于锚点
P
o
s
q
Pos_q
Posq生成object query。
# reference_points 锚点
# pos2posemb2d 使用sine、consine函数生成位置编码
# adapt_pos2d 使用MLP微调位置编码
query_pos = adapt_pos2d(pos2posemb2d(reference_points))
Decoder
Decoder使用前文生成的结果,经过多头自注意力(MultiHeadAttention)和多头交叉注意力(RCDA)后,产生最后的预测结果。
预测的边界框中心点 ( c x ^ , c y ^ ) (\hat{cx}, \hat{cy}) (cx^,cy^)添加锚点坐标得到最终的中心点。
# 预测边界框中心点
tmp = self.bbox_embed[lid](output)
tmp[..., :2] += reference
消融实验
模块有效性

- 1,6对比发现,
RCDA、anchors和patterns模块可以显著提升性能。 - 2,6对比发现,
RCDA与标准Attention性能持平(但是,RCDA训练时内存消耗显著减少)。 - 1,5对比发现,
anchors可以提升性能,anchors和patterns可以提升更多的性能。 DETR中引入patterns并不能提升性能,这是因为DETR的object query与位置没有高度相关,并不能从patterns中获益。
锚点与模式

- 经过对比实验发现(
300,3)时,性能最好。
不同模式预测边界框大小的直方图

- 模式
a关注大目标,模式b关注小目标,模式c介于a,b之间。 - 模式并不仅仅依赖于目标的大小,因为小目标也会出现在模式
a中。(作者认为图中有很多小目标,且小目标很可能出现在同一片区域,所以所有的模式都负责小目标。)
注意力模块比较

- 线性复杂度的
attention模块(Luna、Efficient-att)与标准注意力模块相比,显著减少了训练所需内存,然而,它们的性能也降低了将近10AP。(文中说似乎是因为这些模块不适用于类DETR的检测器) - 在使用高分辨率特征时,
RCDA与标准注意力模块相比,显著减少了训练所需内存,且性能基本持平。
结论
本文提出了一种基于anchor points的query设计,它具有明显的物理意义。此外,还在每个锚点中加入了多模式解决“一个区域多个目标”的问题。本文作者还提出了注意力的变种RCDA,它在减少内存成本的情况下获得了跟DETR中标准注意力相似或更好的性能。

参考资料
https://github.com/megvii-research/AnchorDETR
https://arxiv.org/abs/2109.07107

















 3077
3077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









