






数据合并
数据合并join
示例
# coding: utf-8
import pandas as pd
import numpy as np
df1 = pd.DataFrame(np.ones((2, 4)), index= ["A", "B"], columns=list("abcd"))
df2 = pd . DataFrame(np.zeros((3,3)),index=["A", "B", "C"], columns=list("xyz"))
print(df1)
print(df2)
print(df1.join(df2))
print(df2.join(df1))
结果

数据合并merge
默认合并方式inner 并集 outer交集nan补全 left左边为准,nan补全 right右边为准,nan补全
# coding: utf-8
import pandas as pd
import numpy as np
df1 = pd.DataFrame(np.ones((2, 4)), index= ["A", "B"], columns=list("abcd"))
df2 = pd . DataFrame(np.zeros((3,3)),index=["A", "B", "C"], columns=list("xyz"))
df3 = pd. DataFrame(np.zeros((3,3)),columns=list("fax"))
print(df1. merge(df3,on="a",how= "outer"))
结果

分组聚合
数据集下载:Starbucks Locations Worldwide | Kaggle
示例
# coding: utf-8
import pandas as pd
import numpy as np
file_path = "D:/pythonProject1/DataScience/pandas/starbucks.csv"
df = pd.read_csv(file_path)
# print(df.head(1))
# print(df.info())
grouped = df.groupby(by="Country")
print(grouped)
print(grouped["Brand"].count()) # 统计各国家门店数量
# 调用聚合方法
country_count = grouped["Brand"].count()
print(country_count["US"]) # 统计美国星巴克门店数量
print(country_count["CN"]) # 统计中国星巴克门店数量
# 统计中国各省星巴克数量
china_data = df [df ["Country"]=="CN"]
grouped1 = china_data.groupby(by="State/Province") .count()["Brand"]
print(grouped1)
# 数据按照多个条件分组
grouped2 = df ["Brand"].groupby(by= [df["Country"],df["State/Province"]]).count()
print(grouped2)
结果
各国门店数量

美国中国星巴克门店数量
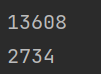
各省门店数量

多个条件分组结果
















 284
284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









