






TGRS2022/云检测:Category Correlation and Adaptive Knowledge Distillation for Compact Cloud Detection in Remote Sensing Images类别相关和自适应知识蒸馏在遥感图像致密云检测中的应用
0.摘要
基于深度卷积神经网络(DCNNs)的云检测获得了显著的精度,但代价是高昂的计算和存储成本,这很难部署到资源受限的设备,如智能卫星。近年来,知识蒸馏(KD)已经成为一种很有前途的解决紧凑模型的方法。然而,现有的KD方法大多只传递成对像素的特征关系,无法处理复杂场景中的薄云和类云物体。此外,这些KD方法直接模拟复杂模型的输出,而不考虑其正确性。在本文中,我们提出了一种新的类别相关和自适应KD (CAKD)框架用于轻量级云检测网络。我们设计了一个类别关系上下文(CRC)模块,从教师和学生网络中提炼结构化的像素-类别相关性。然后,我们进行类别相关蒸馏(CCD),使学生模型更好地解决类内一致性和类间差异,从而减少类别混淆。此外,利用像素自适应蒸馏(PAD)模块提取教师的像素预测概率,自适应地传递教师模型的软输出知识。在Landsat 8、Landsat 7、高分2、高分1和google Earth数据集上的大量实验报告了我们的蒸馏方法的有效性和普遍性。CAKD允许具有2.31 m参数和4.63G浮点运算(flop)的MobileNetV2在不增加附加开销的情况下优于先进的云检测方法
1.概述
最近,知识蒸馏(KD)[18]被证明是一个有前途的解决方案,以其简单和高效的保持紧凑模型的性能。KD可以使轻量级的学生网络模仿复杂的教师网络的建设性知识,提高学生网络的泛化能力。继KD算法用于图像分类[18]-[22]之后,KD算法在密集语义分割中的应用越来越受到关注。云检测对图像中的云进行标记可以看作是一项语义分割任务。使用师生kd进行语义分割已经取得了许多令人印象深刻的结果。表al.[23]结合预先训练的特征编码器来提取任意两个位置之间的亲和性。Liuet al.[24]提出了两两蒸馏,它在特征的空间位置上转移两两关系。Fenget al.[25]利用跨层空间注意提取像素相似性。上述方法已被证明在自然场景中训练紧凑的语义分割网络是有效的。

图1所示。云探测中的困境例子。(a)具有一定背景信息的半透明薄体在不同场景中具有复杂而多样的目标特性。(b)背景中的云状物体常常被错误地归类为云。
与自然场景中的物体不同,不规则形状的云更具挑战性,以下事实说明了云检测的困境。一方面,薄云在RSIs中呈现半透明,造成薄云包含一些来自地面物体的信息。如图1(a)所示,受森林、城市、水域等不同场景的影响,薄云通常表现出复杂多样的目标特征。因此,为了学习更准确的特征表示,轻量级网络应该增强薄云的类内特征一致性,以捕获不同上下文中的共同特征。另一方面,如图1(b)所示,类似云的物体,如沙、冰和高亮显示的物体,会干扰云的检测,经常被错误地分类为云。在这种情况下,学生网络容易在云和云类物体之间产生特征混淆。因此,增强类别之间的特征差异,从而区分易混淆的目标是轻量级网络的关键。然而,现有的kd方法主要利用中间特征的空间像素-像素关系,而没有考虑特征图中像素的类别依赖性,导致性能较差。虽然已经提出了一种双向自蒸馏方法[26]用于紧凑云的检测,但紧凑模型抽象能力较低,本质上难以捕捉复杂场景下的薄云。总之,探索特征的类别相关性是一种有利于致密云检测精馏的建议
此外,目前的蒸馏方法都是在像素级直接模仿教师分数图。然而,网络老师可能并不总是像地面真理一样给出正确的指导,尤其是在不规则和复杂的云的边缘。教师网络的像素分类错误会导致学生网络用错误的软标签更新梯度。因此,教师网络以其独特的辨别能力对学生模型进行自适应的指导是很有必要的
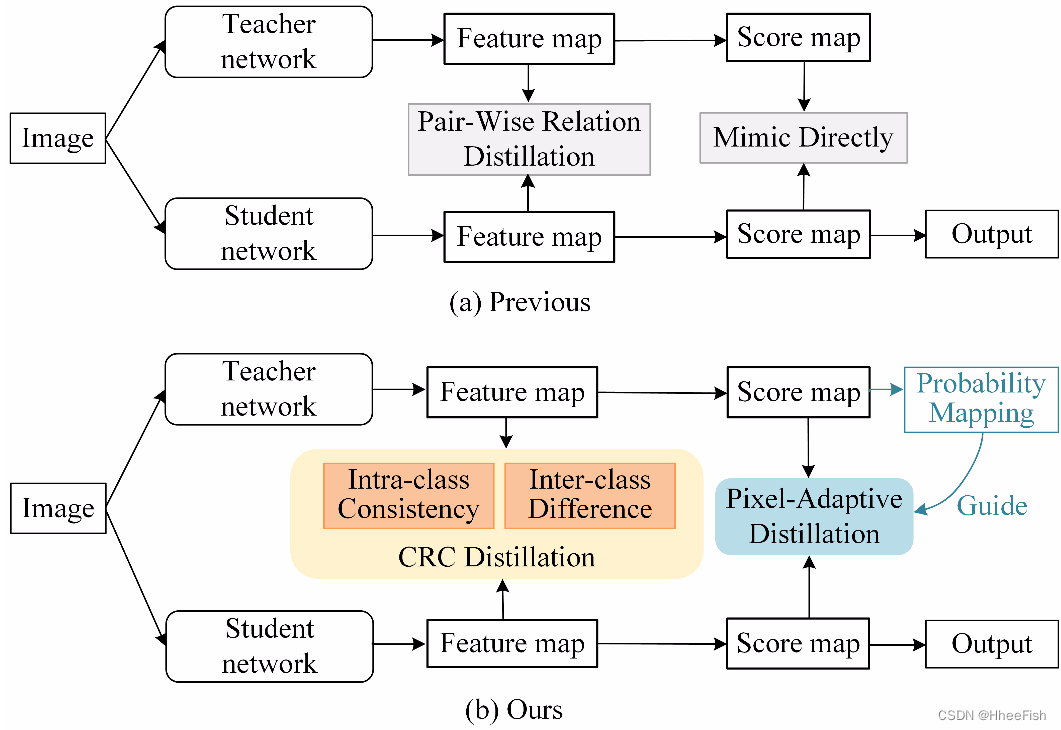
图2所示。KD在云检测中的管道。(a)以前的方法只计算像素分类信息的成对关系。(b)提出了CAKD蒸馏框架。CRC蒸馏转移特征图的类间关系和类间关系。该算法提取出自适应蒸馏的教员的概率值。
为了克服云检测中的这些挑战,我们提出了一种新的类别相关和自适应KD (CAKD)方法对轻量级云检测模型进行改进,如图2,我们在网络特征图中设计了一个类别关系上下文(CRC)模块。CRC模块计算每个像素和类别特征的相似度分布,体现了特征的像素-类别相关性。然后,通过类别相关蒸馏(CCD)传递CRC知识,即属于同一类别的特征的一致性和不同类别之间的可变性。它使学生网络学习到丰富而强大的分类结构化知识,增强复杂背景影响下云检测的鲁棒性。此外,一个像素自适应蒸馏(PAD)模块辅助自适应提取教师网络的分数图。PAD模块利用教师网络的像素级预测概率映射来引导蒸馏,从而避免了教师网络的错误知识
总的来说,我们的工作贡献总结如下:
1)我们提出了一个有效的蒸馏框架CAKD,用于轻量级和精确的云检测模型。与其他云检测方法相比,我们的精馏方法以较少的参数和计算复杂度使模型达到最佳性能。
2)提出了CRC模块来构建特征图的类别关系。通过CCD,学生捕捉到薄云的共同特征表示,避免了云类物体的混淆。
3)PAD模块自适应传输教师网络的评分图,避免了负性软输出知识。基于教师网络的预测置信度对蒸馏损失进行自适应加权。
2.相关工作(略)
3.方法
在本节中,我们首先描述了所提出的CAKD框架,并分别介绍了两个蒸馏模块。最后,介绍了我们的蒸馏框架的训练过程。
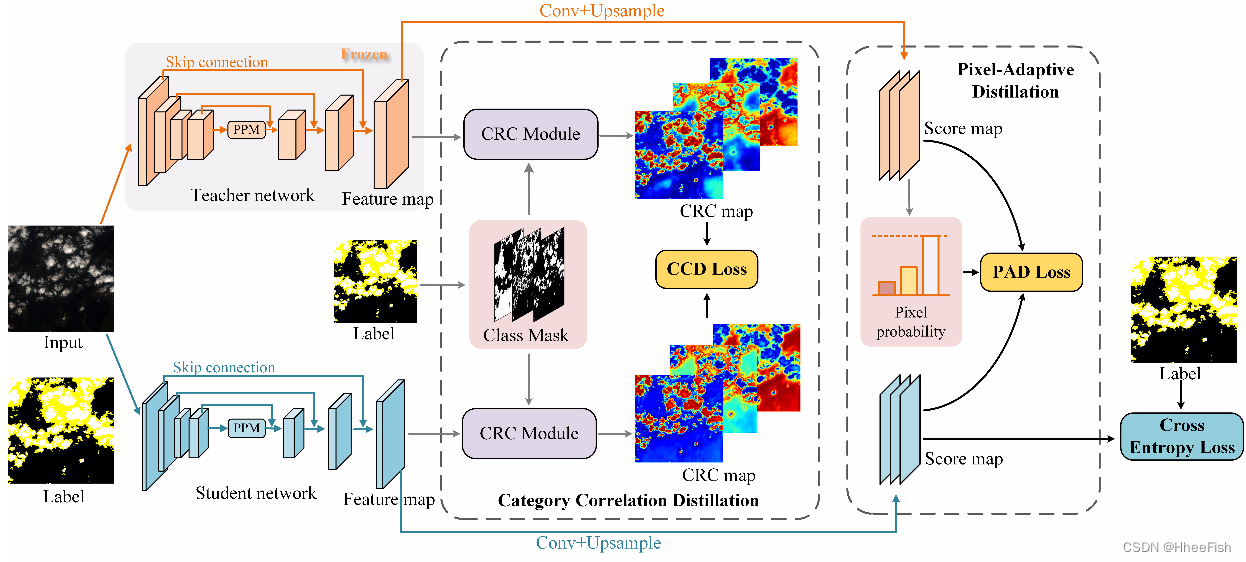
图3所示。CAKD框架的整体架构。学生网络不仅受到标签的监督,也受到来自教师网络的知识的约束。CCD传输经过CRC模块细化的特征图的CRC。PAD自适应地模仿教师的软输出。
3.1.概述
KD的工作原理是将性能良好的教师网络的建设性信息传输到紧凑的学生网络,提高云检测性能。输入影像X = {x1, x2,…,xN},我们的框架旨在为具有参数θ的学生网络模拟教师T的行为。从极大似然的角度来看,KD任务的优化问题可以表示为
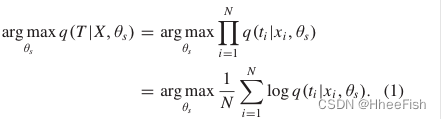
假设输入图像和相应教师行为的联合概率分布为p(x,t),对教师网络进行预先训练和固定。根据大数定律,(1)可近似转化为
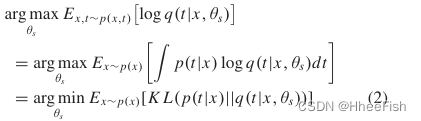
其中p(x)表示输入图像X 的分布,KL表示Kullback-Leibler散度。
因此,我们建立了基于KL divergence的KD目标,帮助学生模仿老师的行为
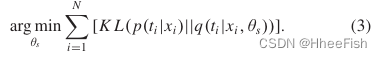
基于上述表示,我们为紧凑云检测模型设计了一个有效的师生蒸馏框架CADE,如图3所示。在训练紧凑网络时,教师的权重是冻结的,没有梯度传播。我们考虑来自特征图和软输出的构造知识来定义教师的行为,记为

其中G(·)被构想为从特征图A中提取结构化信息。特别地,CRC模块用于构建云特征的类内一致性和类间差异。CCD将CRC图从老师传输到学生,从而为学生网络提供了更紧凑的薄云分类描述,并减少了云和类云对象之间的特征混淆。PAD模块提取教师的每个像素概率值,以自适应的方式指导软输出(评分图)的蒸馏。详细操作将在第3.2 3.4节单独描述
3.2.特征CCD(Feature CCD)
在RSIs中,薄半透明云所覆盖的区域可以解释为云层和地面反射的能量综合[9]。紧凑的学生网络特征的缺乏降低了薄云特征的一致性。此外,学生所研究的薄云特征与背景相似,使得薄云像素不易被检测到。此外,云状物体的出现会引起对云目标的详细描述的混淆。现有的蒸馏方法在细化空间位置关系方面取得了一定的进展。他们计算像素与周围相邻像素的成对关系,甚至与完整特征图中的所有像素的关系。该方法对特征图的空间相关性建立非常简单。然而,在计算相对关系时,他们并没有明确地考虑一个像素来自哪个类别。在下采样的特征表示下,网络需要恢复像素的类别信息;因此,像素特征和类别之间的内在联系是必不可少的
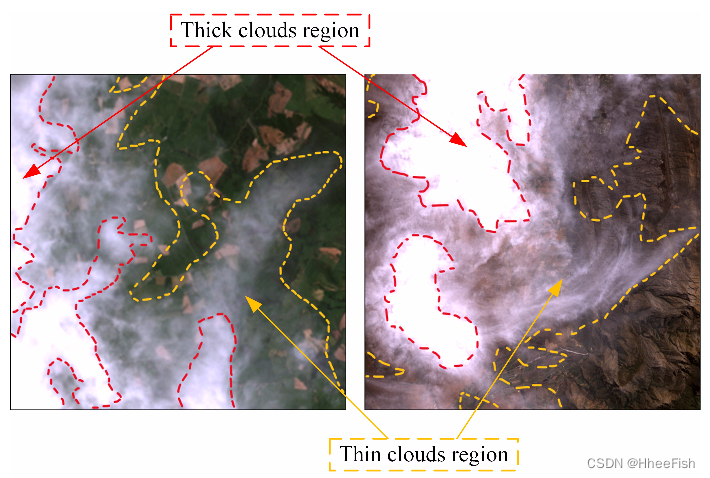
图4所示。RSIs中厚云和薄云区域的插图。厚云呈现出均匀高亮的色彩特征,薄云呈现出模糊的视觉。红色和黄色虚线分别表示厚云区和薄云区。
如图4所示,在RSIs中,厚云表现出均匀的白色和突出的颜色特征,而薄云则表现出模糊的视觉表征,影响了观测。神经网络在云的视觉均匀性下抽象出云的特征描述,从而对不同的云进行分割。通过给具有ground truth的特征区域赋值correct class属性,计算类原型(类中心)[44]来统一属于同一像素类的特征。为了利用网络细化的云特征的特征类别相关性,提出了CRC模块。如图5所示,CRC 模块测量像素特征与不同类别原型之间的相似度,进一步得到的类别之间的相似度分布图描述了特征图的类别相关性
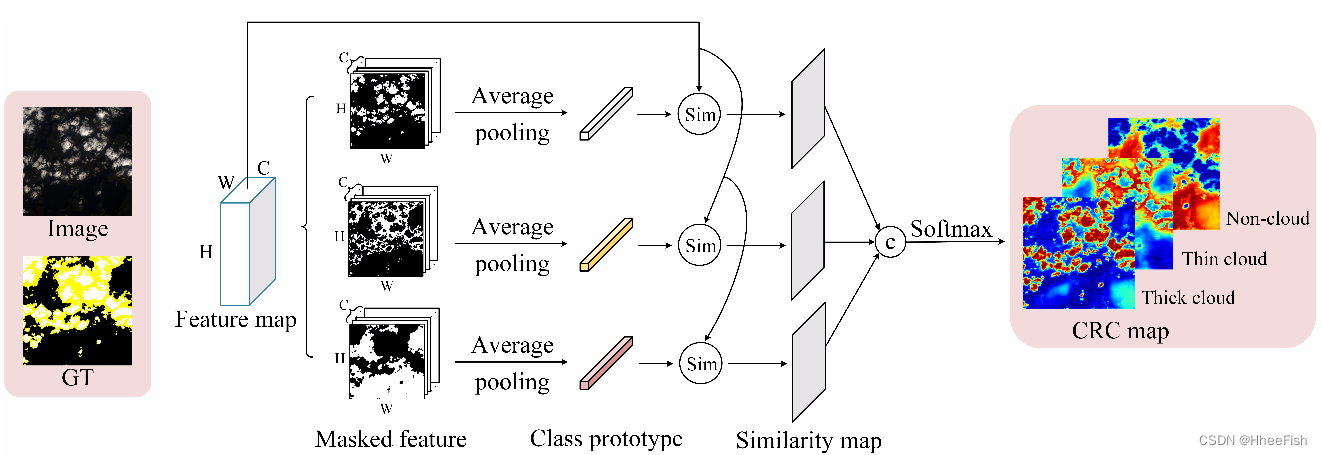
图5所示。CRC模块的详细信息。它计算特征图与不同类原型之间的相似度关系。归一化的CRCmap集合了类内和类间的结构化知识
首先,我们对相同的类特征进行类中心提取,即类原型。给定特征A∈RC×H×W,其中C、H和W分别表示通道的数量、高度和宽度。为了匹配相同类别的区域,我们将ground truth下采样到与特征映射相同的大小,以获得属于不同类别的遮蔽区域特征,并将类别区域记为R。一般的看法是,网络在同一类区域保持输入图像的一致语义描述。因此,我们依赖于使用平均池的类别区域来聚合来自同一类别的特征。在n个类别原型中,第i∈RC×1×1的特征中心表示表示为
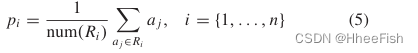
num(Ri)表示属于第i类的像素数。
然后,我们计算每个像素j类原型pi和特征aj∈A之间的余弦相似度Si∈RH×W,si,j∈Si记为
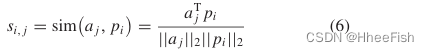
其中aj∈A,j∈(1、2、……,H×W]是A的第j个位置。因此,Si隐含了第i类的特征 像素-区域 相似图
最后,通过合并属于类原型的相似映射,得到特征像素-区域相似度S∈Rn×H×W,sj∈S记为

Cat(·)表示连接操作。为了提取网络的通用结构化知识,我们沿着信道维数应用softmax函数,得到归一化的特征像素-区域相似度,公式如下:
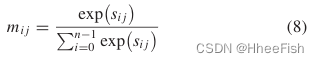
mij∈M。M∈Rn×H×W代表我们提出的CRC知识,记为CRC图
与之前的方法[24]、[38]将关系度量直接视为知识相比,我们将像素和类原型的相似性归一化为概率分布。由于特征图深度不同,直接拟合相似度值对于特征深度较浅的学生网络是不合适的指导方法。需要从特征图中挖掘结构化的知识,期望这些知识在不同网络的特征图中是一致的。我们在第四部分验证了我们创新的有效性。
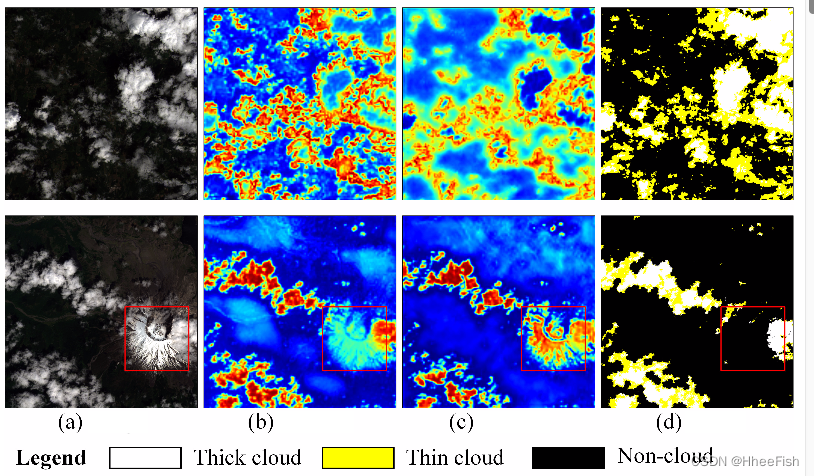
图6所示。CRC的可视化。顶部代表薄云的CRC。底部代表厚云的CRC,红色框表示雪区。(一)image。(b)老师。©学生。(d)标签
在图6中,我们分别提取和可视化薄云和厚云的CRC。顶部RSI显示薄云的典型存在。薄云像素具有模糊性,导致学生网络在某些背景区域具有较高的相似性。相比之下,教师网络有着更为同质的品类描述薄云。我们可视化crc描述的厚云场景与云一样的背景(雪)在底部。教师网络在雪地区域对相似度较低的易混淆背景具有较强的识别能力。因此,我们匹配网络之间的CRC映射来实现CCD,优化学生网络的班级内一致性和类别间差异,如图3所示
为了更好地传递CRC知识,利用KL散度计算网络的CRC图之间的损耗。CCD 损失LCCD如下所示
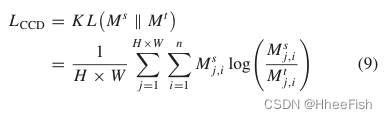
其中,
M
j
,
i
t
M^t_{j,i}
Mj,it和
M
j
,
i
s
M^s_{j,i}
Mj,is分别表示特征图A的第j个像素与教师和学生网络的第i个类别原型之间的CRC。
3.3.Pixel-Adaptive蒸馏
CCD在高嵌入空间上完成表示学习。正如最初提出的蒸馏,教师网络的softmax输出包含负样本的信息,这有助于学生网络的泛化能力。同样,语义分割通常被视为像素级的分类任务,KD执行像素级的知识模仿
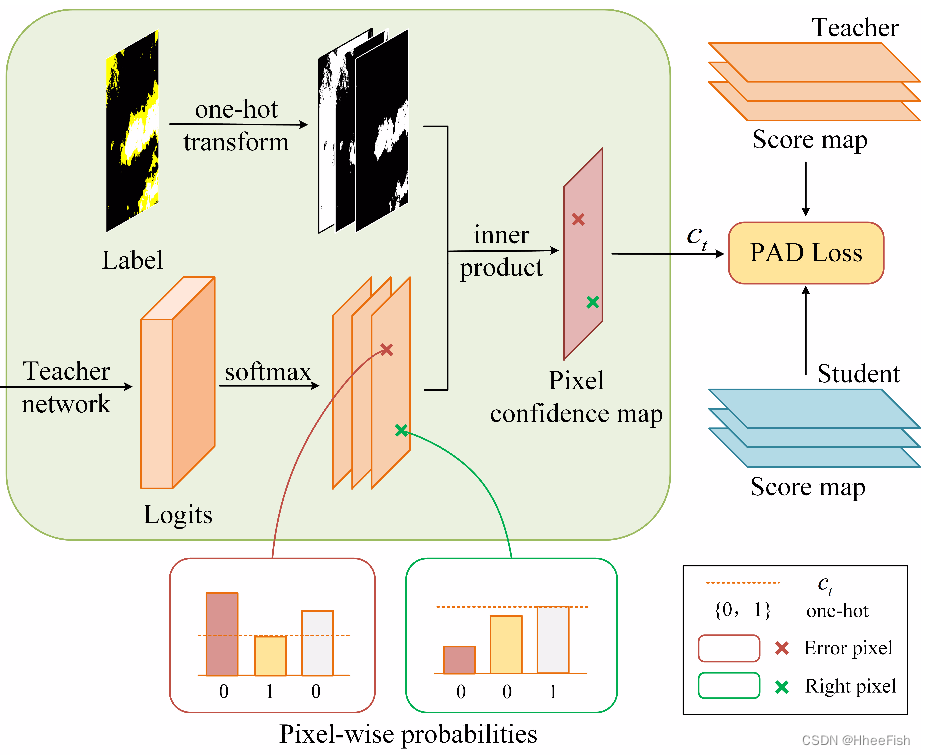
图7所示。PAD模块的插图。提取教师网络的像素预测概率来衡量蒸馏损失
然而,对于复杂的遥感场景,教师网络具有对不同像素的可变预测能力。正确的预测分布的注入对学生网络的训练是积极的。但是,对于困难的像素,特别是在不规则和复杂的云的边缘,教师网络可能并不总是提供正确的指导与标签相比。如图7所示,教师网络可以在绿色框内的概率边际值较小的情况下进行正确预测,甚至在红色框内给出的指导值为负值。因此,我们提出了自适应教学的PAD损失,以避免局部像素错误
自适应蒸馏过程描述如下。假设网络的像素级概率z,使用softmax函数计算属于第i类的概率。此外,对温度参数τ进行了调整以软化概率分布,公式为
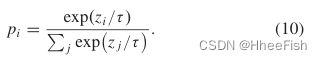
对于密集的预测任务,τ的增大会引入噪声,不利于学习。在我们的研究中,τ被设为1
图7显示了我们的PAD模块。通过softmax给定教师的输出分数图O和标签G,我们通过像素-像素的内乘积Ct=Inner(Ot,TOneHot(G))提取像素置信图Ct。对于每个像素j cj∈Ct表示为:

Gj是第j个像素的标签。换句话说,cj的值等于概率分布pj中第i类的概率值
随后,我们引入KL散度来实现分数图的蒸馏,定义如下:
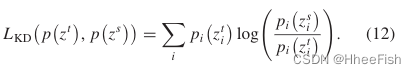
我们将提取的像素置信度图作为教师的教学能力。然后,利用像素预测概率Ct对蒸馏损失函数进行重加权,PAD可表示为
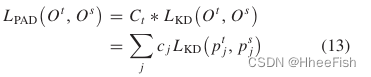
Ot和Os分别表示教师网络和学生网络的分数图。
3.4.优化过程

在预训练的教师网络的基础上,训练紧密型学生网络,优化过程如算法1所示。CCD和PAD分别只在训练过程中在特征和像素级实现知识转移。轻量级学生网络在推理阶段不需要附加参数和计算。总体目标函数由三个部分组成:标准交叉熵lossLCE、CCD损失LCCD(9)和PAD 损失LPAD(13)

α和β为损失权重,使损失值范围具有可比性。
4.实验
本节在多个数据集中综合评估我们的CAKD框架。具体介绍了系统的数据集、实现细节和实验结果
4.1.数据

表1:实验中使用了大量的云探测数据集。*请注意在实验中实际使用的图像的大小
我们对具有不同空间分辨率的多个光学卫星图像进行了一系列实验,如表I所示。它们是公开发布的Landsat 8[46]和Land sat 7[47]的云覆盖评估验证数据集、AIR-CD数据集[36]、HRC-WHU数据集[6]、,以及高分一号(GF-1)宽视野(WFV)云和云阴影覆盖验证数据[30]。
1) Landsat 8云覆盖评估验证数据:1级多光谱数据由Landsat8卫星操作陆地成像仪(OLI)和热红外传感器(TIRS)捕获,包括96幅空间分辨率为30m的场景图像。它涵盖了八种自然场景,包括贫瘠、草/作物、森林、灌木地、城市、雪/冰、湿地和水域。它们被数字化为晴空、薄云、厚云和云影,其中薄云在视觉上是半透明的。在我们的实验中,我们将晴空和云影视为非云,分为三类:厚云、薄云和非云。为了确保数据集的合理分布,我们选择了64幅云百分比为5%-100%的图像,并将它们按2:1:1的比例分成训练集、验证集和测试集。我们在训练和测试阶段将原始图像分割为512×512像素。实验将可见波段作为网络的输入。由于数据集包含丰富的多光谱波段信息,除了空间分辨率为15m的全色波段外,我们还利用了近红外(NIR)、短波红外(SWIR)和热红外(TIR)波段,这些波段有利于进一步实验的云提取
2) 陆地卫星7云覆盖评估验证数据:有206个陆地卫星7增强专题地图加(ETM+)1G级场景。这些场景是根据不同的纬度带分布的。为了避免标记不耐受问题,我们从这些图像中选择了44幅具有相对精确注释的图像用于我们的实验,并将它们分为三个部分:23幅、10幅和11幅图像,分别用于训练、验证和测试。我们在实验中选择的场景包括贫瘠、水、城市、冰雪、湿地和植被。数据预处理和类别设置与Landsat 8数据集一致。我们使用该数据集的波段1–4进行了比较实验,其中波段1-3是可见波段,波段4是NIR波段,这有利于云检测。
3) AIR-CD数据集:AIR-CD数据库包含来自高分二号卫星的34个高分辨率RSI,空间分辨率为4m。这些图像收集于中国不同地区,并按像素标记为云和背景。在我们的实验中,所有34张图像被随机分成25张用于训练,9张用于测试。原始图像被切成512×512像素的大小,我们将可见光波段和近红外波段作为网络的输入
4) HRC-WHU数据集:高分辨率云层覆盖验证数据集由150幅来自谷歌地球(谷歌股份有限公司)的高分辨率图像组成,分辨率为0.5至15米。它覆盖了全球不同地区,包括贫瘠、植被、城市、雪/冰和水。这些图像包括RGB通道,并标记有云和晴空。在我们的实验中,我们将它们按3:1的比例分成训练集和测试集,以验证我们的方法在高分辨率卫星图像上的有效性
5) GF-1 WFV云和云阴影覆盖验证数据:GF-1数据集包括高分一号卫星WFV成像系统中的108个2A级场景,涵盖了不同云条件下的不同全球土地覆盖类型。这些图像的空间分辨率为16,由四个光谱带组成,包括可见和近红外光谱区。这些imageslabel云、云阴影和非云区域的参考遮罩。为了评估我们的云阴影检测方法的有效性,我们将其分为42、38和28个场景,分别进行训练、验证和测试
4.2.应用
1) 网络结构:使用基于全卷积的编码器-解码器模型来实现端到端云检测,如图3所示。输出步长为8的网络通过跳过连接以连接方式融合多尺度特征。解码器利用双线性插值对特征的逐层上采样进行解码,并输出像素级预测结果。PPM[39]用于使教师网络实现更好的性能。教师和学生之间的区别在于骨干网络的选择。教师网络使用扩展的ResNet50作为骨干网络。同时,我们验证了我们的蒸馏方法,将不同权重的网络结构作为学生网络,即具有一半信道数的ResNet18[48](命名为ResNet18-h)和MobilenetV2[16]。将ResNet18中的信道数量减半,将模型参数减少3.3倍,仅为3.29M。MobilenetV2设计了反向剩余块,以通过减少的计算获得更好的性能,在我们的任务中只有2.31M的参数。
2) 训练设置:教师网络和MobiletV2都使用在ImageNet上预先训练的网络[49],ResNet18-h是从头开始训练的。当网络由多个波段输入时,我们加载使用RGB数据预训练的三个通道的权重并初始化具有正态分布的其他波段的权重。
根据前面的工作[25],[38],损失权重α和β分别设置为600和20,以保持与交叉熵损失的平衡。随机梯度下降(SGD)作为优化器用于训练动量为0.9的网络。我们的网络用一批八幅图像训练了300个时期。初始学习率设置为0.002,使用“多”学习率更新策略[50],功率为0.9,衰减为0.0001。实现了一些通用数据增强,包括随机旋转、随机水平和随机垂直翻转。我们的实验是在RTX-2080Ti GPU上使用PyTorch 1.3框架进行的。
3)评估指标:我们使用常用的准确性评估指标定量评估云检测结果,包括平均像素交叉过并(mIoU)、总像素精度(OA)、F1得分、召回率或用户精度(UA)和精度或生产者精度(PA)。具体计算如下

TP、TN、FP、FN分别为真阳性、真阴性、假阳性、假阴性的个数。
为了比较不同方法的效率,我们评估了模型的参数数量(表示为asParams)和模型计算512×512像素分片图像的FLOPs数量。此外,还在原始分辨率图像和with512×512像素的切片图像上评估每个模型的推断时间(记为推断时间)。
4.3.消融实验
我们首先从定量和定性两个方面验证了不同蒸馏组分对基线的提升。然后,我们分别分析了两种蒸馏组成的效果。
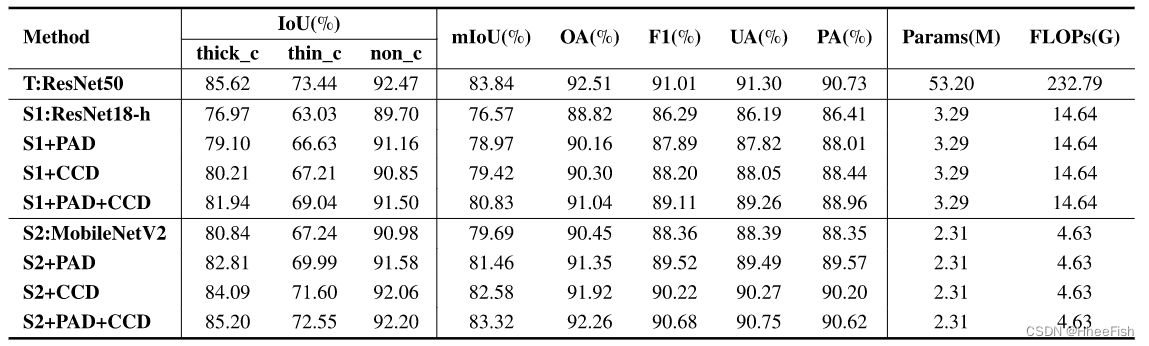
表2:在地面和卫星数据平台上的消融实验结果
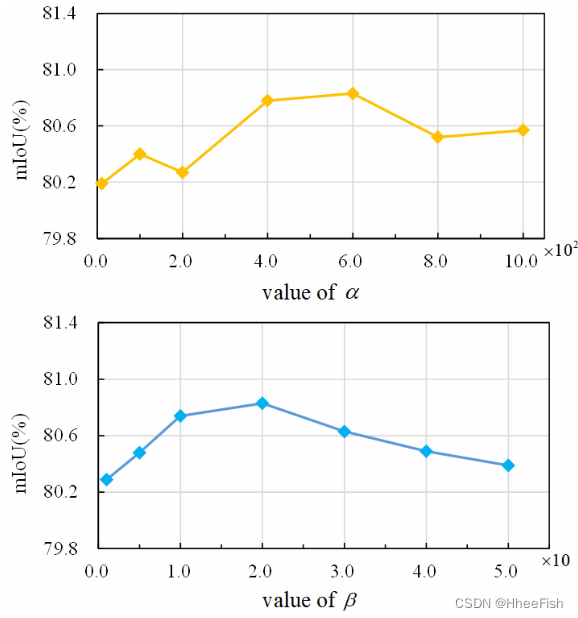
图8所示。在Landsat 8数据集上用ResNet18-h研究α和β的超参数敏感性
1) 定量结果:为了验证我们的特征级(CCD)和像素级(PAD)蒸馏方法的有效性,我们依次添加蒸馏组件进行实验。我们在表II中报告了两个学生网络的蒸馏模块的结果。在CCD和PAD的知识转移下,ResNet18-h和MobileNetV2的mIoU度量分别提高了4.26%和3.63%。特别是,对于中厚云的探测精度的提高更为明显。对于MobileNetV2,厚云和薄云分别增加4.36%和5.31%mIoU。MobileNetV2与教师之间的云计算差距从6.20%降至0.89%。这证实了我们对难以分割类别蒸馏的效果。同时,CDD和PAD的结合应用为网络带来了最大的效益。特别是,特征级知识比像素级知识具有更强大的输出,反映了KD中特征表示对于分割网络的重要性。值得注意的是,MobileNetV2在模型参数和FLOP大幅降低的情况下,实现了与教练网络相当的检测精度。此外,我们通过几个实验分析了权重超参数α和β对模型的敏感性。图8显示了每个超参数的鲁棒性。
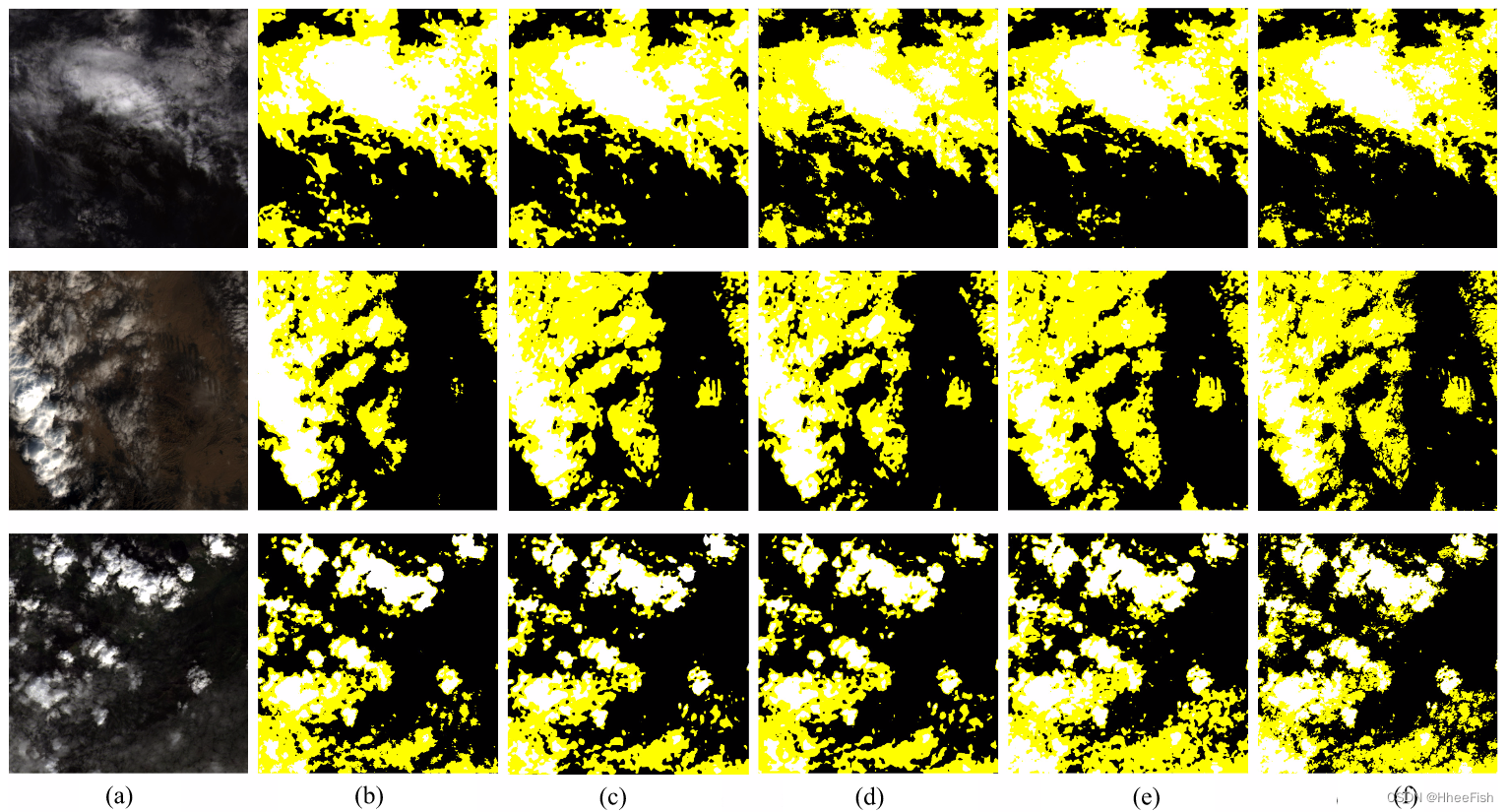
图9所示。Landsat 8数据集上不同蒸馏组分的预测结果。(一)原图。(b) ResNet18-h的结果。© PAD患者resnet18小时的结果。(d) CCD的ResNet18-h结果。(e) ResNet18-h添加PAD和CCD的结果。(f)标签。面具中的白色、黄色和黑色分别表示厚云、薄云和晴空。
2) 定性结果:通过添加蒸馏组件对切片图像进行云检测的可视化结果如图9所示。在图9(c)中,PAD模块提取教师的像素级预测输出,允许学生捕获不明显的薄云像素。图9(d)表明,通过提取特征类别相关性,CCD增强了复杂背景下薄云检测的性能。学生网络能够更准确地捕获较小的薄云碎片,并对薄云边界进行更详细的预测。这验证了CCD在帮助学生网络捕捉薄云的共同特征以及检测在背景中不容易看到的薄云方面是有效的。如图9(e)所示,与静止前的结果相比,我们的提取框架有效地改进了学生网络的预测,特别是对于不明显的薄云和不规则的云边界
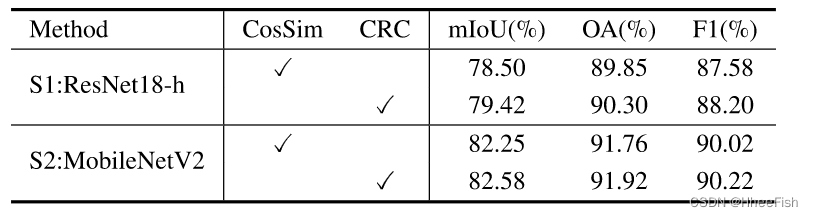
表3:与直接蒸馏法相比,在Landsat8上对特征进行规范化的有效性
3) 特征CCD分析:所提出的CCD通过蒸馏CRC特征来优化学生网络的特征表示。从表3中,用于特征级蒸馏的CCD分别为ResNet18手持MobileNetV2带来2.85%和2.89%的mIoU。特别是对于厚云和薄云,在ResNet18-h的示例中,CCD分别提高了3.24%和4.18%mIoU
在我们的CCD中,为了消除不同特征深度之间的差距,需要对特征相似度进行归一化。先前的提取直接匹配像素对的相似性,通常使用L2损失。表III中的结果报告了CRC图的有效性。CosSim使用L2损失对特征类别余弦相似性的提取进行去噪。我们的CCD计算由KL散度提取的归一化CRC,并为知识传递产生更高的增益。
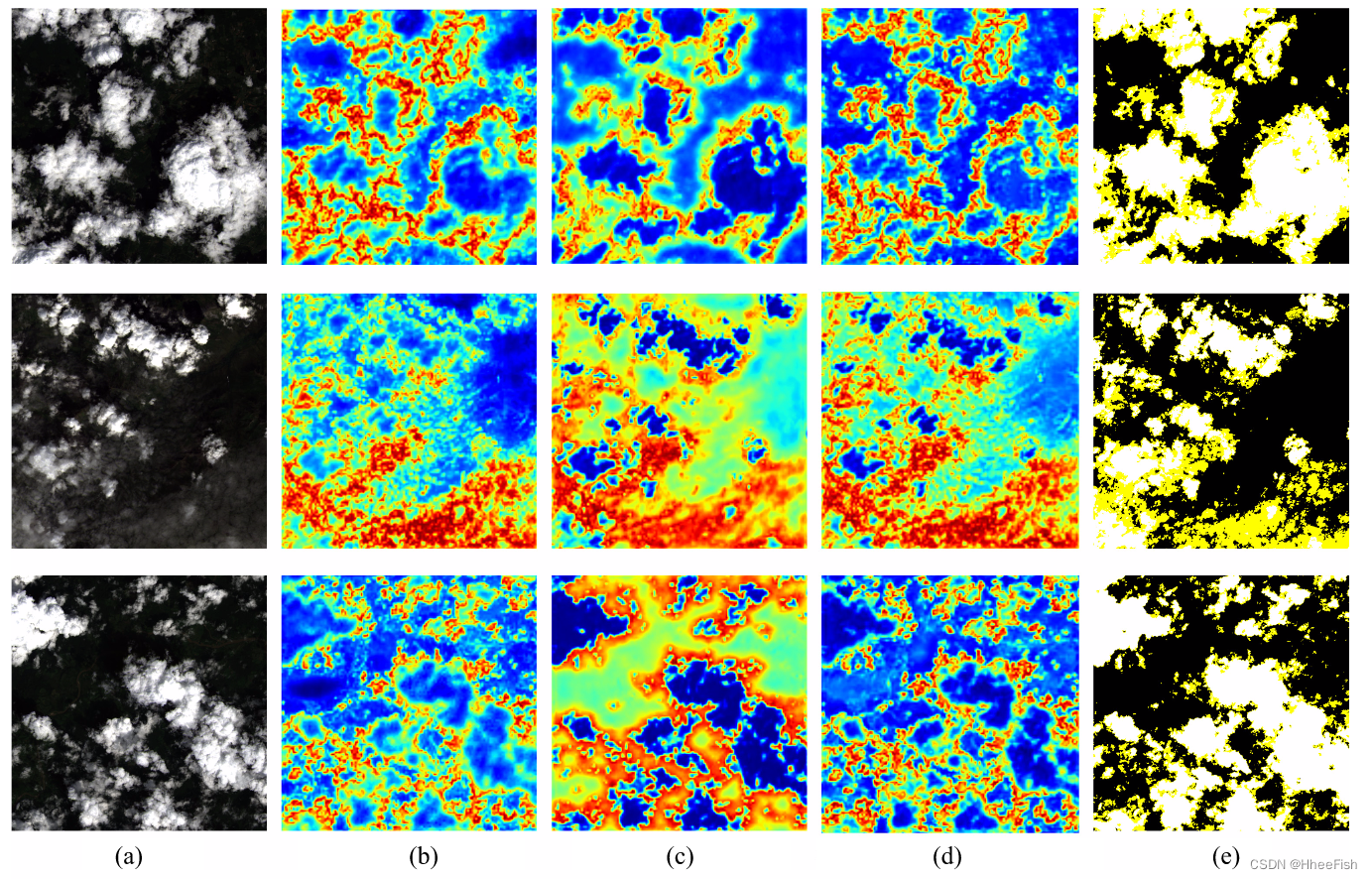
图10.Landsat 8数据集上不同网络的薄层CRC图的可视化。(a) 图像。(b) 教师网络的薄层CRC图。(c) 作为学生网络的ResNet18-h的薄层CRC图。(d) 带有CCD的ResNet18-h的薄层CRC图。(e) 标签。遮罩中的白色、黄色和黑色分别表示厚云、薄云和晴空。
为了证明CCD在特征图上的改进,我们在图10中可视化了不同图像的薄云的特征CRC图。特征CRC是在像素和不同类别区域之间的相似性映射上构建的。众所周知,特征表示的高类内紧凑性和类间分散性可以导致更好的分割结果。与Fig.10(b)中的教师网络相比,图10(c)中作为学生网络的ResNet18-h的CRC图与背景区域特征具有相对较高的置信值。正如预期的那样,薄云的不明显目标特征可能导致薄云像素容易与背景混淆,从而使薄云难以检测。相反,在图1中CCD的情况下。10(d),薄云的特征类内一致性描述显著改善。在大多数背景像素上,天云和背景的特征相似性明显降低。通过从老师那里学习更密集的特征类别相关性,可以细化学生网络的细云特征描述。此外,我们注意到原始学生网络体现了薄云和厚云之间的高类别特征差异,而CCD之后特征差异减弱。我们认为本地相关性更改是可以接受的,因为学生网络中类别特性的关系已经在整个图像上得到了改进,这对预测更为重要
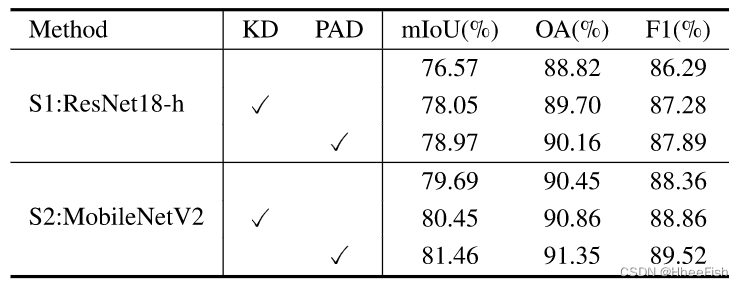
表4
4) PAD分析:PAD模块修复了教师网络中不正确的像素知识,避免了对难以预测的像素的误导。我们比较了直接像素级模拟[18](表示为KD)方法,以验证PAD模块的效果。表4显示,与KD相比,PAD模块使像素级蒸馏在两个学生网络上分别提高0.92%和1.01%mIoU。因此,用预测的置信度重新加权像素级蒸馏损失是有利的
4.4.与最先进方法的比较
我们将我们的蒸馏方法与Landsat 8数据集上的其他蒸馏方法进行了比较。我们还展出轻量级学生网络与我们的蒸馏方法和其他先进的云检测方法之间的比较。
1) 与其他蒸馏方法的比较:我们将所提出的蒸馏方法与蒸馏方法:KD、FitNet和成对蒸馏进行了比较。Hinton提出的KD用于直接提取网络的像素级得分图。FitNet在分类任务中提出,将教师的中间层表示作为提示进行区分。此外,还引入了其他参数来调整网络之间的空间尺度和中间层的深度。在[20]之后,我们在FinNet实验中使用1×1卷积来对齐学生和老师的特征通道。[24]中提出了用于自然场景的图像分割的成对蒸馏,其计算像素的成对相似度以构建亲和图。特别是,我们计算了整个图像的全局像素亲和度,像素蒸馏也适用于
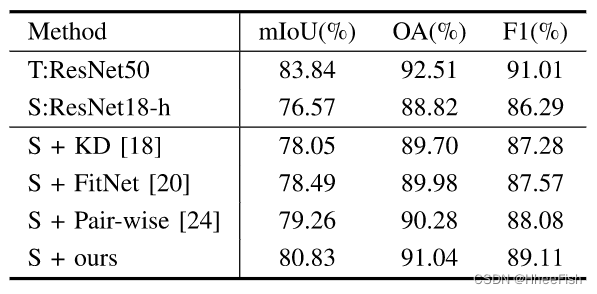
表5:实验结果与先进的蒸馏方法进行了比较
表5表明,我们的方法比其他蒸馏策略更有效。KD有效地提高了性能,但增益有限。由于FitNet直接匹配网络的中间特征,因此它忽略了不同深度的特征表示能力,从而导致较小的精度增益。成对蒸馏的像素成对相似关系是紧密的,而我们的方法结合了像素的类别标签来构建一种紧凑的像素类别关系,更适合云检测任务
2) Landsat 8数据集的云检测结果:我们将在Landsat8卫星图像上与其他先进的云检测网络进行比较。我们的比较方法包括经典的语义分割网络,如ENet、DeepalabV3和PSPNet,其中ENet是一个轻量级的实时语义分割网络。其他云检测网络,如L-Unet、CDnet和多尺度特征卷积神经网络(MFCNN)也用于比较,其中L-Unet是一种轻量级云检测网络。与我们的工作类似,MFCNN也被提议探测薄云和厚云。
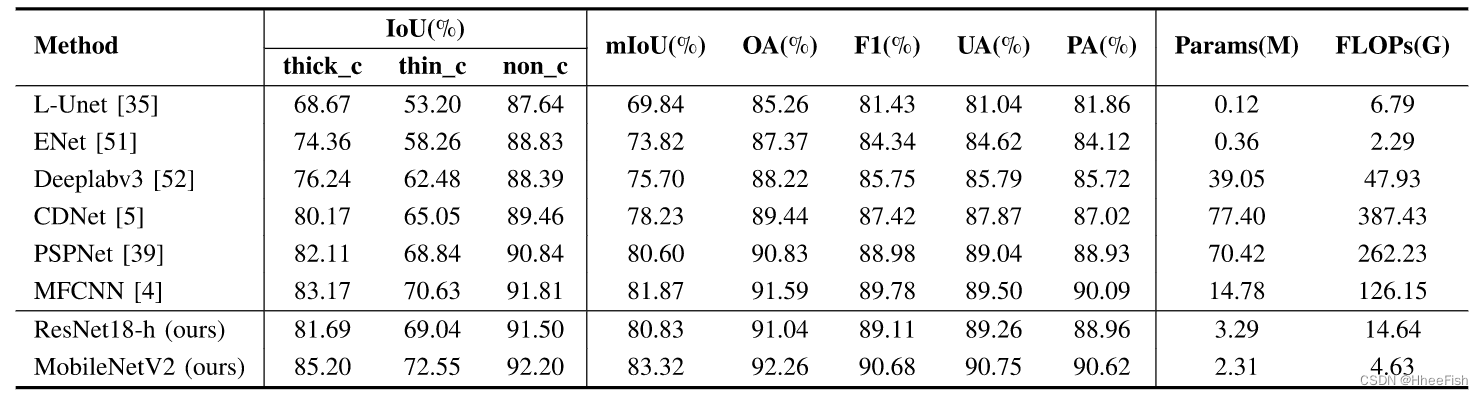
表6:与其他云探测方法的实验结果比较
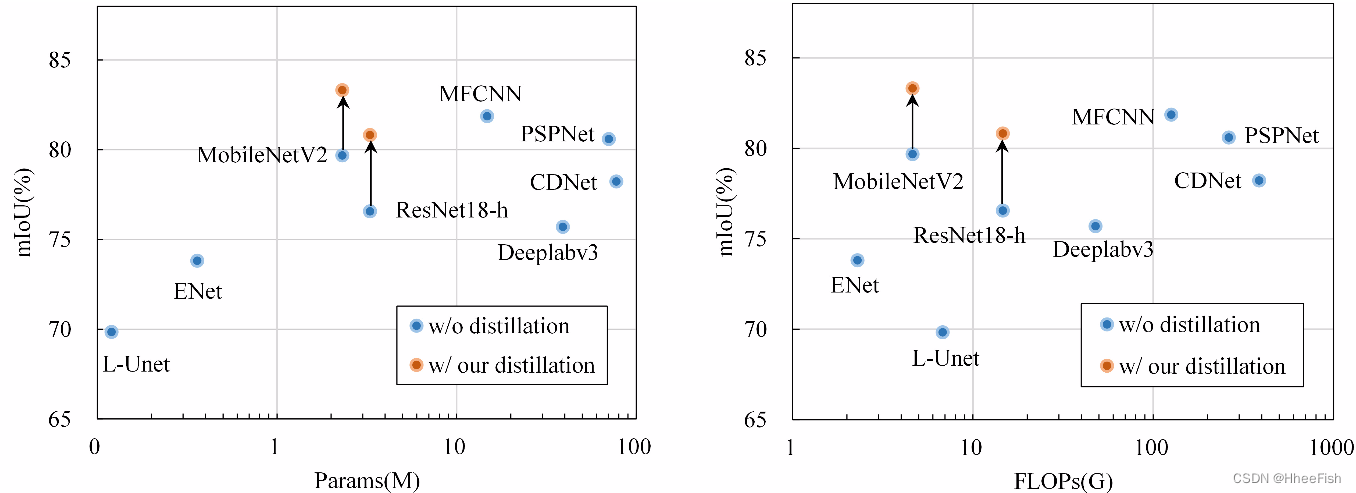
图11.Landsat 8数据集上不同模型的参数、FLOP和mIoU的比较
我们考虑网络模型的检测精度、参数数量和计算量(即FLOP),以全面比较不同的云检测方法。在表6中,MobileNetV2与我们的分离在所有网络中实现了83.32%mIoU的最高精度。此外,通过输入多频带图像,学生网络的性能进一步提高。对于网络的效率,L-Unet和ENet都使用具有较少参数和FLOP的轻量级网络,但实现的检测精度不令人满意。与cumber某些模型Deepalabv3、PSPNet、CDNet和MFCNN相比,我们的蒸馏方法允许轻量级MobileNetV2仅使用16%的模型参数和4%的MFCNN FLOP来执行这些模型,这在cumber模型中表现最好。图11显示了不同云检测方法的准确性和效率。我们的方法有效地提高了轻量级网络的准确性,而红点指示了我们的方法的轻量级模型。此外,MobileNetV2以较少的参数和复杂性实现了最高的精度
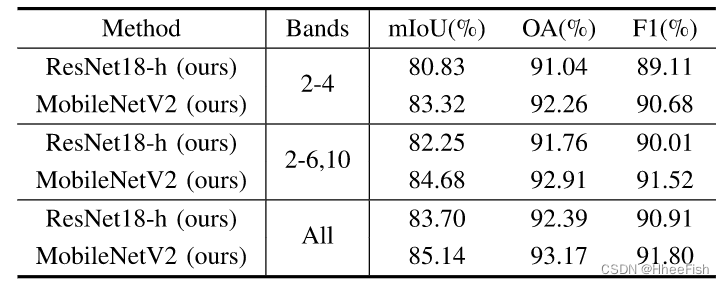
表7:不同波段的实验结果
云探测的精度也受到输入光谱带的影响。为了比较我们模型在不同波段条件下的性能,我们评估了RGB、NIR、SWIR和TIR波段(2–6和10)的输入以及我们模型的所有可用波段。表7给出了结果,模型的精度评估结果表明,所有可用波段的输入都达到了Landsat 8测试集中的最高mIoU。与仅使用RGB波段(2–4)相比,添加红外波段(5、6和10)进一步提高了模型的准确性。因此,我们的方法在不同的频带设置下是有效的,并且频带越多,精度增益越大

图12.Landsat 8图像预测结果的可视化。(a) 草/作物区域(场景ID:LC81320352013243LGN00)。(b) 贫瘠地区(场景ID:LC81990402014267LGN00)。面具中的白色、黄色和黑色分别表示厚云、薄云和晴空。
Landsat 8图像的可视化结果如图12所示。在不同的场景下,使用我们的蒸馏方法的紧凑网络(ResNet18-h和MobileNetV2)显示了在薄云、破碎云和云边界的精确检测。与轻量级网络相比,我们的MobileNetV2模型捕捉到了不易察觉的薄云。与基于DCNN的方法相比,我们的模型实现了可比的竞争性检测结果。
3) Landsat 7数据集的云检测结果:我们在Landsat 7卫星图像上验证了蒸馏方法的有效性。我们比较了与Landsat 8数据集相同的云检测方法。我们训练和测试不同的网络使用波段1-4图像(RGB和NIR)。此外,我们与直接像素级模仿18进行了比较。
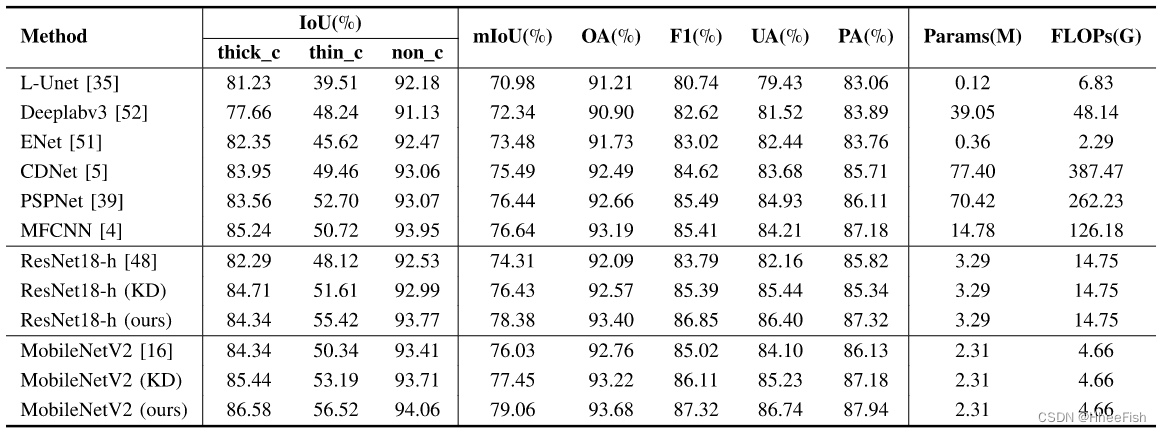
表8:与其他云探测方法的实验结果对比
表8报告了不同方法的预测结果。我们使用我们的蒸馏方法对Landsat 7数据集上的resnet18手MobileNetV2学生网络进行蒸馏,在mIoU指标方面带来了4.07%和2.91%的改进,优于KD。薄云的mIoU显著改善,分别提高了7.3%和5.9%。与其他云检测方法相比,我们的方法还允许学生网络以更少的参数和FLOPs实现最佳性能
4)高分辨率RSIs的云检测结果:为了验证我们方法的泛化性能,我们在高分辨率卫星数据air - cd和HRC-WHU上进行了实验。表9显示,使用我们的CAKD框架的mobilenetv2在mIoU和AIR-CD数据集上的F1得分分别为91.42%和95.45%,优于其他云检测方法
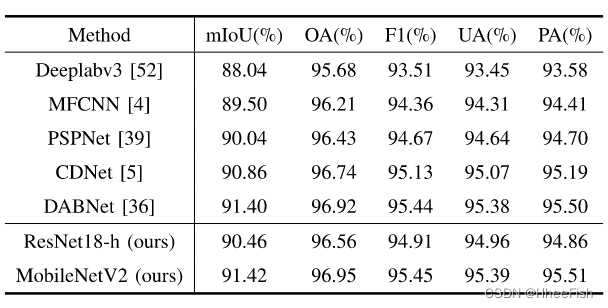
表9:将实验结果与其他测云方法的结果进行了比较

图13所示。HRC-WHU数据集云探测结果的可视化(a)图像。(b) MobileNetV2的结果。©使用CAKD的MobileNetV2的结果。(d)标签
HRC-WHU数据集上不同方法的精度比较结果见表x。我们的方法对ResNet18-h和MobileNetV2的miou分别提高了2.26%和1.74%。使用我们的CAKD的mobilenetv2实现了89.31%的mIoU准确率,高于其他云检测网络。HRC-WHU数据集高分辨率卫星图像上的云检测示例如图13所示,分别是来自冰雪、城市和水域的场景。可以观察到,MobileNetV2基线方法倾向于不正确地检测地物。此外,MobileNetV2和我们的CAKD可以提供相对更准确的云检测结果,并减少在局部区域的明显错误
5)gf -1数据集的云和云阴影检测结果:为了验证我们的方法对云和云阴影检测的适用性,我们在GF-1数据上应用了我们的蒸馏方法。表XI报告了不同方法的精度评估结果,其中多特征组合(MFC)方法是GF-1WFV数据集的基线方法。一方面,我们的蒸馏方法在ResNet18-h和MobileNetV2上应用时是有效的,其mIoU分别提高了2.4%和2.13%。另一方面,我们的MobileNetV2优于其他云检测方法,并且与传统的MFC方法相比,准确度显著提高

图14所示。GF-1数据集云检测结果的可视化。(a)图像。(b) MFC方法的结果。© MobileNetV2的结果。(d)使用我们的CAKD的mobilenetv2的结果。(e)标签。面具中的白色、灰色和黑色分别表示云、云影和晴空
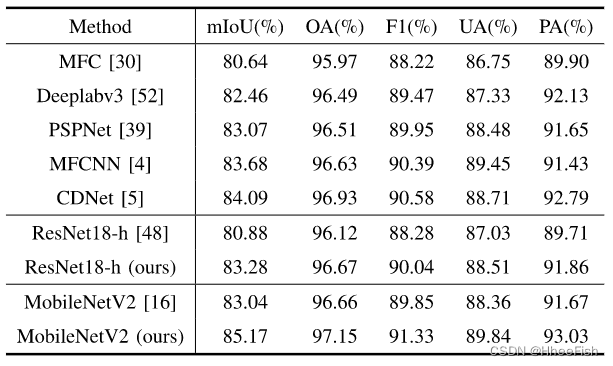
利用gf -1卫星数据将实验结果与其他云检测方法进行了比较
图14显示了GF-1数据集上云检测结果的一些示例。前两行显示,在云阴影检测中,图14(d)中使用我们的CAK的MobileNetV2改进了图14(c)中基线方法的不准确边界结果。此外,与图14(b)中的MFC方法相比,我们的结果对云阴影的错误检测更少。图14的最后两行显示了冰雪场景中的检测结果。我们可以看到MFC方法很容易将雪/冰和山脉阴影误认为云和云阴影,应用我们的CAKD后,MobileNetV2可以更好地区分雪/冰、云和云阴影。我们分析了我们方法的有效性,通过我们的CAKD,学生网络增强了云和云阴影区域的类别一致性表示,这表明我们的CAKD也适用于云阴影检测
4.5.时间效率
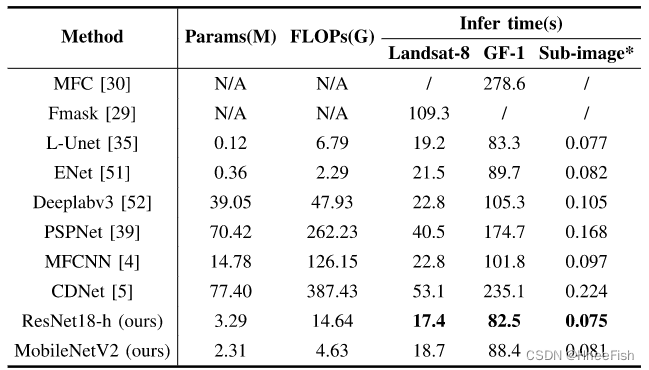
表12:不同方法推断时间的比较。实验所用的子图像来自于Landsat8卫星数据
在本节中,我们评估了不同云检测方法的时间效率。特别是,我们测试了不同大小图像的推断时间。在我们的实现中,我们从陆地卫星8号和高分一号卫星中随机选择了两个RSI,大小分别为7581×7751像素和17116×15309像素。Landsat 8的基准方法Fmask和GF-1的MFC使用Intel Core i7-7700在CPU模式下执行,而基于DCNN的方法使用NVIDIA Tesla-P100 GPU进行测试。基于DCNN的方法基于512×512像素的子图像进行推理,然后缝合子图像的结果以获得整个图像的最终结果。因此,我们还报告了基于DCNN的方法预测子图像的时间
表12列出了不同方法的参数、FLOP和推断时间。以三个频带作为输入对基于DCNN的方法的度量进行测试。我们测试了来自Landsat 8数据集的100张切片子图像,并报告了平均推断时间。显然,由于GPU的高效计算,基于DCNN的方法比传统的Fmask和MFC方法花费更少的时间。我们的ResNet18 hmodel对Landsat 8、高分一号图像和子图像的推断时间分别为17.4、82.5和0.075秒,这比其他方法更短。L-Unet和ENet的推断时间与ResNet18-h相当,但其云检测精度较差(如第IV-D节所示)。我们还观察到,虽然MobileNetV2具有较少的参数和FLOP,但由于其特殊的深度可分离卷积,它比ResNet18-h稍慢。然而,我们认为MobileNetV2的检测精度优于其他模型是可以接受的。综合而言,与其他云检测网络相比,我们的ResNet18-h和MobileNetV2模型以相对较短的推断时间实现了令人满意的准确性。
4.6.讨论

图15所示。我们的MobileNetV2在其他卫星图像上的云检测例子。面具中的白色、黄色和黑色分别代表厚厚的云层、薄云和晴朗的天空。(a) Sentinel-2(10米)。(b) ASTER(15米)。
1) 可移植性:在第IV-D节中,我们在各种数据集上训练并测试了我们的云检测模型,以证明我们的方法的有效性,说明了我们的CAKD在不同卫星、不同解决方案和不同光谱设置下云检测的可扩展性。此外,我们在其他卫星上测试了我们的模型,而没有对其进行培训,以验证我们模型的可移植性。我们的MobileNetV2模型在Landsat 8个标记有薄云和厚云的卫星样本上训练,并应用于其他卫星图像上的云检测。测试图像分别是Sentinel-2卫星的可见图像和高级星载热发射和反射辐射计(ASTER)卫星传感器的可见-近红外(VNIR)图像。如图15所示,我们的模型在分辨率为10m的Sentinel-2图像和分辨率为15m的ASTER卫星图像上生成了令人满意的云掩模结果。此外,我们的模型是在全球不同的土地覆盖类型上训练的,训练数据是多样的
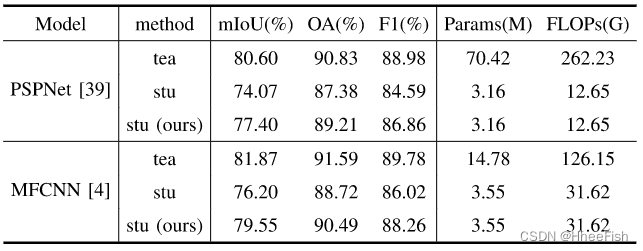
表13:用我们的方法提取不同的模型(Landsat8)
2) 通用性:为了证明我们的CAKD的通用性,我们将我们的方法应用于不同的基于DCNN的云检测模型。Landsat8数据集的蒸馏结果如表13所示。我们用PSPNet和MFCNN模型作为教师模型进行了实验。对于PSPNet,我们将教师网络(ResNet101)的主干替换为ResNet18-h作为轻量级学生网络。对于MFCNN,我们将拥有一半波段的MFCNN作为学生网络。可以看出,我们的方法对于不同类型的云检测模型都取得了很好的性能

图16所示。教师模型在HRC-WHU数据集高分辨率rsi上的云检测误差
3)局限性:虽然提出的CAKD框架可以提高轻量化模型在复杂场景下的精度,但对于高分辨率卫星图像的云检测仍然存在一些难以应对的情况。图13中HRC-WHU数据集上的样本结果表明,我们的方法可以增强轻量模型在一些复杂场景下的检测结果。然而,由于高分辨率rsi的云检测任务容易受到地物和光照的影响,因此在复杂场景下,我们的教师模型可能会产生预测误差,如图16所示。教师模型的明显错误会影响KD的结果。未来,我们将优化复杂教师模型的性能,以提高轻量化模型对高分辨率RSIs的鲁棒性
5.结论
在这篇文章中,我们提出了一个有效的CAKD框架为紧凑的云检测模型量身定制。提出的crc模块测量像素-类别的相关性网络特征图。CCD使紧凑的网络能够通过CRC知识的提取来学习云的连贯共同特征,并强化云与类云物体之间的特征差异。pad模块提取教师的像素预测值,对蒸馏损失进行加权自适应蒸馏,减轻了来自教师网络的负面引导。我们在Landsat 8、Landsat 7、高分2、高分1和谷歌地球数据集上验证了我们的提取方法的有效性和普适性。我们的方法比其他蒸馏方法更适合云检测任务,并允许轻量级MobileNetV2优于流行的云检测方法,具有更好的效率。在未来的工作中,我们打算优化复杂教师模型的性能,以进一步提高轻量化网络在高分辨率RSIs复杂场景中的准确性。此外,我们希望利用多光谱或高光谱卫星捕获的丰富光谱波段来提高复杂场景下的云探测结果
参考文献
[1] M. Shi, F. Xie, Y. Zi, and J. Yin, “Cloud detection of remote sensingimages by deep learning,” inProc. IEEE Int. Geosci. Remote Sens. Symp.(IGARSS), Jul. 2016, pp. 701–704.
[2] K. Yuan, G. Meng, D. Cheng, J. Bai, S. Xiang, and C. Pan, “Efficientcloud detection in remote sensing images using edge-aware segmentationnetwork and easy-to-hard training strategy,” inProc. IEEE Int. Conf.Image Process. (ICIP), Sep. 2017, pp. 61–65.
[3] Z. Yanet al., “Cloud and cloud shadow detection using multilevel featurefused segmentation network,”IEEE Geosci. Remote Sens. Lett., vol. 15,no. 10, pp. 1600–1604, Oct. 2018.
[4] S. Zhenfenget al., “Cloud detection in remote sensing images based onmultiscale features-convolutional neural network,”IEEE Trans. Geosci.Remote Sens.vol. 57, no. 6, pp. 4062–4076, Jun. 2019.
[5] J. Yang, J. Guo, H. Yue, Z. Liu, H. Hu, and K. Li, “CDNet: CNN-based cloud detection for remote sensing imagery,”IEEE Trans. Geosci.Remote Sens., vol. 57, no. 8, pp. 6195–6211, Aug. 2019.
[6] Z. Li, H. Shen, Q. Cheng, Y. Liu, S. You, and Z. He, “Deep learningbased cloud detection for medium and high resolution remote sensingimages of different sensors,”ISPRS J. Photogramm. Remote Sens.,vol. 150, pp. 197–212, Apr. 2019.
[7] J. Guo, J. Yang, H. Yue, H. Tan, and K. Li, “CDnetV2: CNN-basedcloud detection for remote sensing imagery with cloud-snow coexis-tence,”IEEE Trans. Geosci. Remote Sens., vol. 59, no. 1, pp. 700–713,Jan. 2021.
[8] X. Wu, Z. Shi, and Z. Zou, “A geographic information-driven methodand a new large scale dataset for remote sensing cloud/snow detection,”ISPRS J. Photogramm. Remote Sens., vol. 174, pp. 87–104, Apr. 2021.
[9] W. Li, Z. Zou, and Z. Shi, “Deep matting for cloud detection in remotesensing images,”IEEE Trans. Geosci. Remote Sens., vol. 58, no. 12,pp. 8490–8502, Dec. 2020.
[10] S. Han, J. Pool, J. Tran, and W. J. Dally, “Learning both weights andconnections for efficient neural networks,” 2015,arXiv:1506.02626.
[11] P. Molchanov, S. Tyree, T. Karras, T. Aila, and J. Kautz, “Pruningconvolutional neural networks forresource efficient inference,” 2016,arXiv:1611.06440.
[12] S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressingdeep neural networks with pruning, trained quantization and Huffmancoding,” 2015,arXiv:1510.00149.
[13] I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y. Bengio,“Quantized neural networks: Training neural networks with low pre-cision weights and activations,”J. Mach. Learn. Res., vol. 18, no. 1,pp. 6869–6898, 2017.
[14] M. Jaderberg, A. Vedaldi, and A. Zisserman, “Speeding up convolutionalneural networks with low rank expansions,” 2014,arXiv:1405.3866.
[15] E. L. Denton, W. Zaremba, J. Bruna, Y. LeCun, and R. Fergus, “Exploit-ing linear structure within convolutional networks for efficient evalua-tion,” inProc. Adv. Neural Inf. Process. Syst., 2014, pp. 1269–1277.
[16] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen,“MobileNetV2: Inverted residuals and linear bottlenecks,” inProc.IEEE/CVF Conf. Comput. Vis. Pattern Recognit.,Jun.2018,pp. 4510–4520.
[17] X. Zhang, X. Zhou, M. Lin, and J. Sun, “ShuffleNet: Anextremely efficient convolutional neural network for mobile devices,”inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018,pp. 6848–6856.
[18] G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neuralnetwork,” 2015,arXiv:1503.02531.
[19] W. Park, D. Kim, Y. Lu, and M. Cho, “Relational knowledge distilla-tion,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR),Jun. 2019, pp. 3967–3976.
[20] A. Romero, N. Ballas, S. E.Kahou, A. Chassang, C. Gatta, andY. Bengio, “FitNets: Hints for thin deep nets,” 2014,arXiv:1412.6550
[21] S. Zagoruyko and N. Komodakis, “Paying more attention to attention:Improving the performance of convolutional neural networks via atten-tion transfer,” 2016,arXiv:1612.03928.
[22] J. Yim, D. Joo, J. Bae, and J. Kim, “A gift from knowledge distillation:Fast optimization, network minimization and transfer learning,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017,pp. 4133–4141.
[23] T. He, C. Shen, Z. Tian, D. Gong, C. Sun, and Y. Yan, “Knowledgeadaptation for efficient semantic segmentation,” inProc. IEEE/CVFConf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019, pp. 578–587.
[24] Y. Liu, C. Shu, J. Wang, and C. Shen, “Structured knowledge distillationfor dense prediction,”IEEE Trans. Pattern Anal. Mach. Intell., earlyaccess, Jun. 12, 2020, doi:10.1109/TPAMI.2020.3001940.
[25] Y. Feng, X. Sun, W. Diao, J. Li, and X. Gao, “Double similarity distil-lation for semantic image segmentation,”IEEE Trans. Image Process.,vol. 30, pp. 5363–5376, 2021.
[26] Y. Chaiet al., “Compact cloud detection with bidirectional self-attention knowledge distillation,”Remote Sens., vol. 12, no. 17, p. 2770,Aug. 2020.
[27] R. A. Freyet al., “Cloud detection with MODIS—Part I: Improvementsin the MODIS cloud mask for collection 5,”J. Atmos. Ocean. Technol.,vol. 25, no. 7, pp. 1057–1072, 2008.
[28] J. Weiet al., “Dynamic threshold cloud detection algorithms for MODISand Landsat 8 data,” inProc. IEEE Int. Geosci. Remote Sens. Symp.(IGARSS), Jul. 2016, pp. 566–569.
[29] Z. Zhu and C. E. Woodcock, “Object-based cloud and cloud shadowdetection in Landsat imagery,”Remote Sens. Environ., vol. 118,pp. 83–94, Mar. 2012.
[30] Z. Li, H. Shen, H. Li, G. Xia, andL. Zhang, “Multi-feature combinedcloud and cloud shadow detection in GaoFen-1 wide field of viewimagery,”Remote Sens. Environ., vol. 191, pp. 342–358, Mar. 2017.
[31] G. J. Jedlovec, S. L. Haines, and F.J. LaFontaine, “Spatial and temporalvarying thresholds for cloud detection in GOES imagery,”IEEE Trans.Geosci. Remote Sens., vol. 46, no. 6, pp. 1705–1717, Jun. 2008.
[32] P. Li, L. Dong, H. Xiao, and M. Xu, “A cloud image detection methodbased on SVM vector machine,”Neurocomputing, vol. 169, no. 2,pp. 34–42, Dec. 2015.
[33] N. Ghasemian and M. Akhoondzadeh, “Introducing two random forestbased methods for cloud detection in remote sensing images,”Adv. SpaceRes., vol. 62, no. 2, pp. 288–303, Jul. 2018.
[34] Y. Yuan and X. Hu, “Bag-of-words and object-based classification forcloud extraction from satellite imagery,”IEEE J. Sel. Topics Appl. EarthObserv. Remote Sens., vol. 8, no. 8, pp. 4197–4205, Aug. 2015.
[35] Z. Zhaoxiang, A. Iwasaki, X. Guodong, and S. Jianing, “SmallSatellite Cloud detection based on deep learning and imagecompression,”Preprints,2018,Art.no.2018020103,doi:10.20944/preprints201802.0103.v1.
[36] Q. He, X. Sun, Z. Yan, and K. Fu, “DABNet: Deformable contextualand boundary-weighted network for cloud detection in remote sensingimages,”IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–16, 2022.
[37] F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally,and K. Keutzer, “SqueezeNet: AlexNet-level accuracy with 50x fewerparameters and <0.5MB model size,” 2016,arXiv:1602.07360.
[38] Y. Wang, W. Zhou, T. Jiang, X. Bai,and Y. Xu, “Intra-class featurevariation distillation for semantic segmentation,” inProc. Eur. Conf.Comput. Vis., Cham, Switzerland: Springer, 2020, pp. 346–362.
[39] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsingnetwork,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR),Jul. 2017, pp. 2881–2890.
[40] L.-C. Chen, Y. Zhu, G. Papandreou, F. Schroff, and H. Adam, “Encoder-decoder with atrous separable convolution for semantic image segmenta-tion,” inProc. Eur. Conf. Comput. Vis. (ECCV), Sep. 2018, pp. 801–818
[41] J. Fuet al., “Dual attention network for scene segmentation,” inProc.IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019,pp. 3146–3154.
[42] H. Zhang, H. Zhang, C. Wang, and J. Xie, “Co-occurrent features insemantic segmentation,” inProc. IEEE/CVF Conf. Comput. Vis. PatternRecognit. (CVPR), Jun. 2019, pp. 548–557.
[43] Y. Yuan, L. Huang, J. Guo, C. Zhang, X. Chen, and J. Wang, “OCNet:Object context network for scene parsing,” 2018,arXiv:1809.00916.
[44] F. Zhanget al., “ACFNet: Attentional class feature network for semanticsegmentation,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV),Oct. 2019, pp. 6798–6807.
[45] Y. Yuan, X. Chen, and J. Wang, “Object-contextual representations forsemantic segmentation,” inProc. Eur. Conf. Comput. Vis.,Glasgow,U.K.: Springer, Aug. 2020, pp. 173–190.
[46] S. Fogaet al., “Cloud detection algorithm comparison and validationfor operational Landsat data products,”Remote Sens. Environ., vol. 194,pp. 379–390, Jun. 2017.
[47] P. L. Scaramuzza, M. A. Bouchard, and J. L. Dwyer, “Development ofthe Landsat data continuity mission cloud-cover assessment algorithms,”IEEE Trans. Geosci. Remote Sens., vol. 50, no. 4, pp. 1140–1154,Apr. 2012.
[48] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning forimage recognition,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit.(CVPR), Jun. 2016, pp. 770–778.
[49] O. Russakovskyet al., “ImageNet large scale visual recognition chal-lenge,”Int. J. Comput. Vis., vol. 115, no. 3, pp. 211–252, Dec. 2015.
[50] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille,“DeepLab: Semantic image segmentation with deep convolutional nets,atrous convolution, and fully connected CRFs,”IEEE Trans. PatternAnal. Mach. Intell., vol. 40, no. 4, pp. 834–848, Apr. 2016.
[51] A. Paszke, A. Chaurasia, S. Kim, and E. Culurciello, “ENet: A deepneural network architecture for real-time semantic segmentation,” 2016,arXiv:1606.02147.
[52] L.-C. Chen, G. Papandreou, F. Schroff, and H. Adam, “Rethinking atrousconvolution for semantic image segmentation,” 2017,arXiv:1706.05587.















 1417
1417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









