







一.安装weaviate客户端
1.Dify 0.6.9中weaviate信息
在Dify 0.6.9版本中weaviate容器信息如下:
# The Weaviate vector store.
weaviate:
image: semitechnologies/weaviate:1.19.0
restart: always
volumes:
# Mount the Weaviate data directory to the container.
- ./volumes/weaviate:/var/lib/weaviate
environment:
# The Weaviate configurations
# You can refer to the [Weaviate](https://weaviate.io/developers/weaviate/config-refs/env-vars) documentation for more information.
QUERY_DEFAULTS_LIMIT: 25
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'false'
PERSISTENCE_DATA_PATH: '/var/lib/weaviate'
DEFAULT_VECTORIZER_MODULE: 'none'
CLUSTER_HOSTNAME: 'node1'
AUTHENTICATION_APIKEY_ENABLED: 'true'
AUTHENTICATION_APIKEY_ALLOWED_KEYS: 'WVF5YThaHlkYwhGUSmCRgsX3tD5ngdN8pkih'
AUTHENTICATION_APIKEY_USERS: 'hello@dify.ai'
AUTHORIZATION_ADMINLIST_ENABLED: 'true'
AUTHORIZATION_ADMINLIST_USERS: 'hello@dify.ai'
ports:
- "8080:8080"
- "50051:50051"
2.weaviate客户端版本
使用weaviate客户端版本为weaviate-client~=3.21.0如下:
-
~=是一种版本兼容性运算符,表示兼容特定版本的微版本更新。 -
3.21.0表示该依赖项的最低版本要求。 -
具体来说,
~=3.21.0表示兼容任何大于等于 3.21.0 但小于 3.22.0 的版本。也就是说,它会匹配 3.21.x 系列中的所有版本,但不会匹配 3.22.0 或更高版本。
安装命令为pip install weaviate-client~=3.21.0。
二.Dify测试知识库
1.创建知识库和上传文档
在Dify中创建测试知识库:
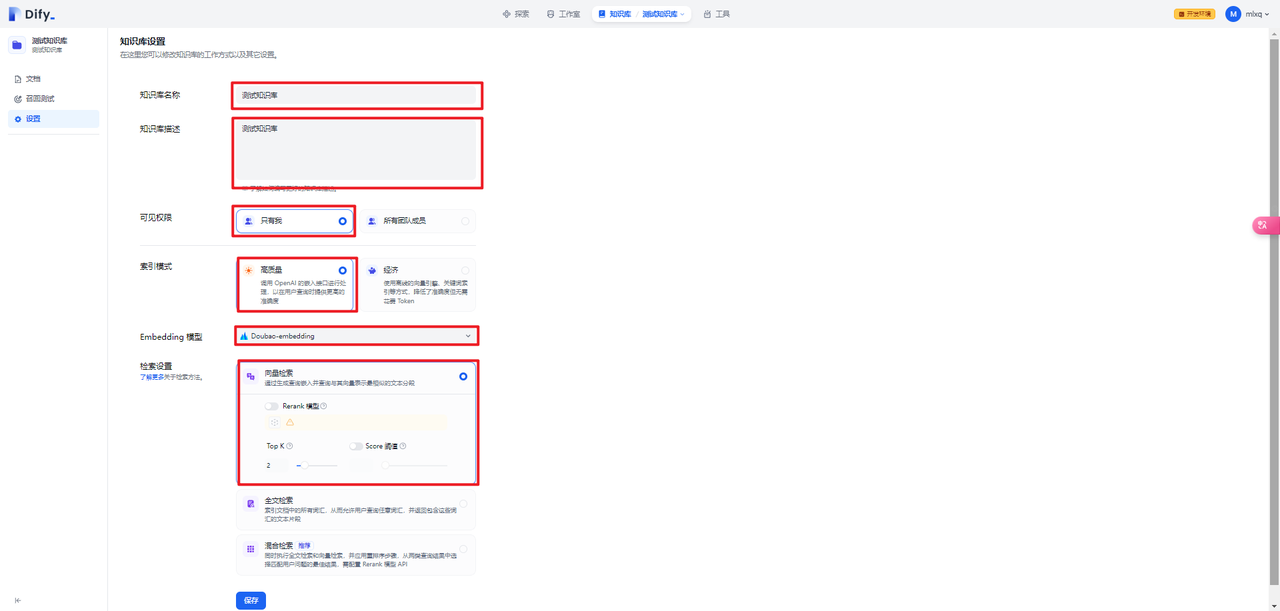
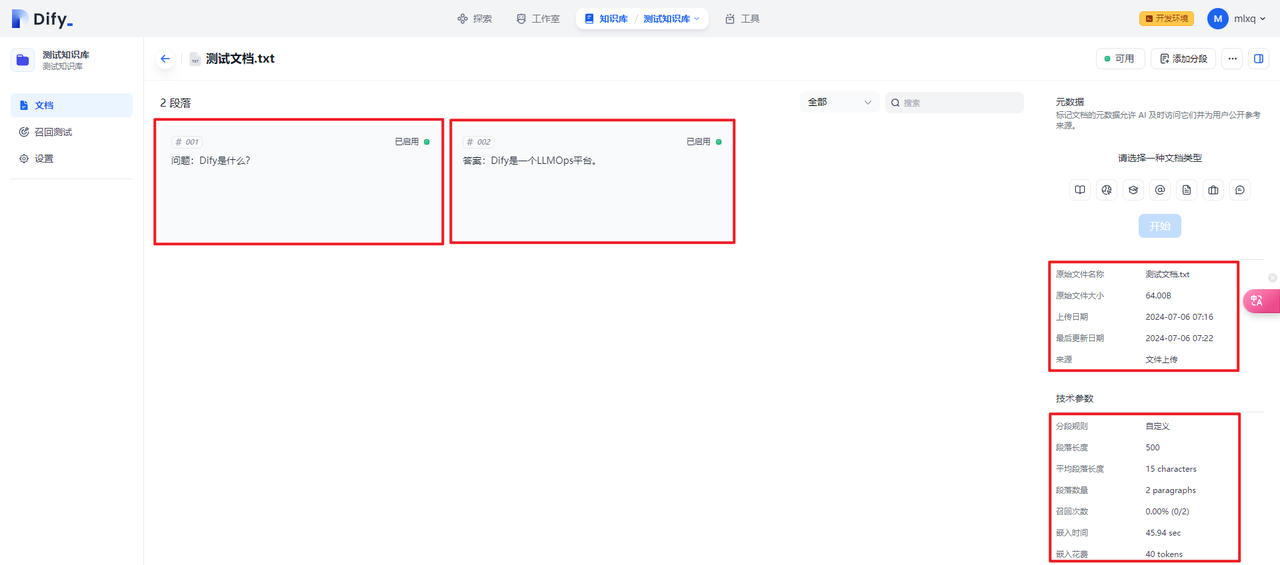
然后上传测试文档:

使用自定义分段规则,得到2个段落:
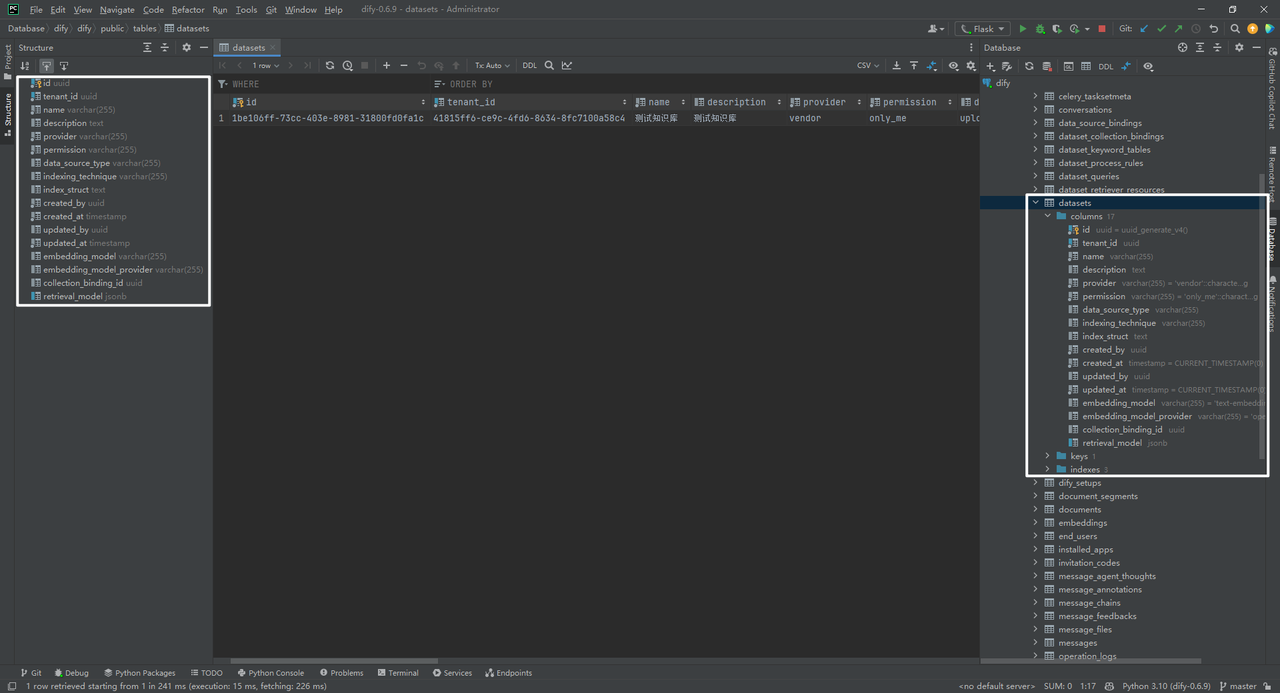
2.datasets数据表
datasets数据表:即知识库。
(1)index_struct
{
"type": "weaviate",
"vector_store": {
"class_prefix": "Vector_index_1be106ff_73cc_403e_8981_31800fd0fa1c_Node"
}
}
其中,1be106ff_73cc_403e_8981_31800fd0fa1c是datasets表中id,即知识库id。
(2)retrieval_model
{
"top_k": 2,
"search_method": "semantic_search",
"reranking_model": {
"reranking_model_name": "",
"reranking_provider_name": ""
},
"score_threshold": null,
"reranking_enable": false,
"score_threshold_enabled": false
}
3.documents数据表
documents数据表:即知识库中的每个文档。
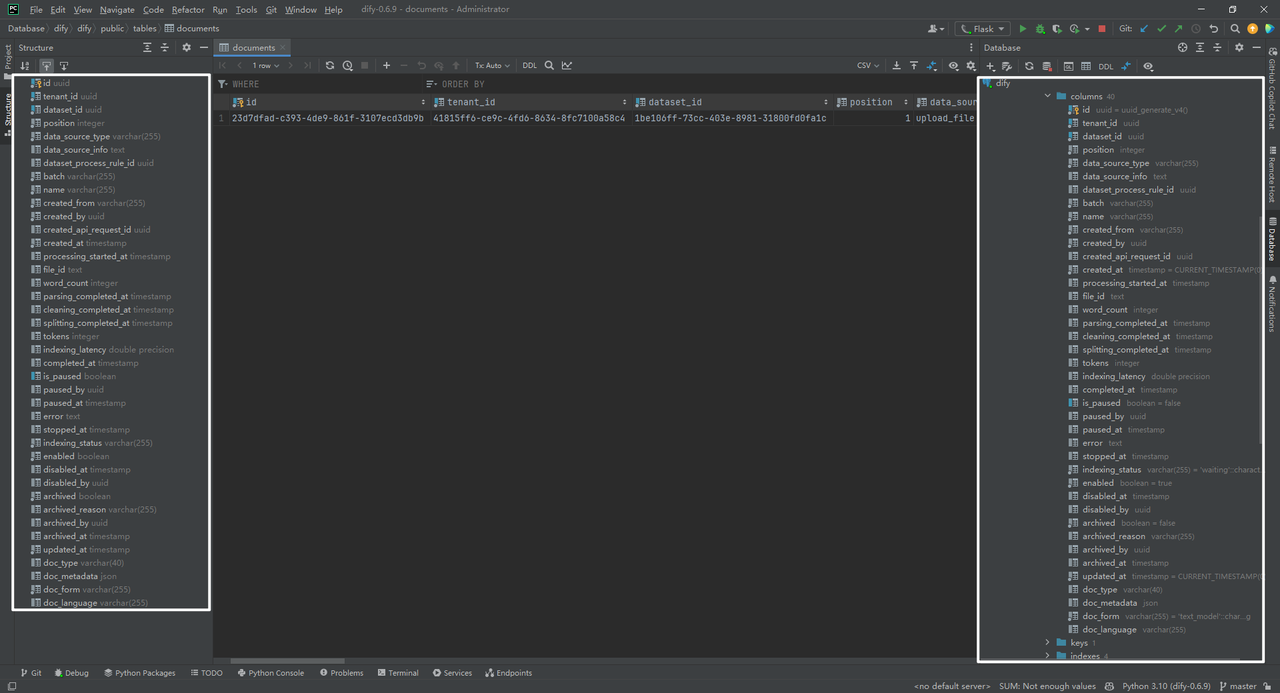
(1)dataset_process_rule_id
619efb69-aa7f-4546-ae3a-c59e5eb4a106
对应dataset_process_rules数据表内容为
{
"pre_processing_rules": [{
"id": "remove_extra_spaces",
"enabled": true
}, {
"id": "remove_urls_emails",
"enabled": true
}],
"segmentation": {
"separator": "\n",
"max_tokens": 500,
"chunk_overlap": 50
}
}
(2)doc_form
text_model
4.document_segments数据表
document_segments数据表,即知识库中每个文档的每个分段。
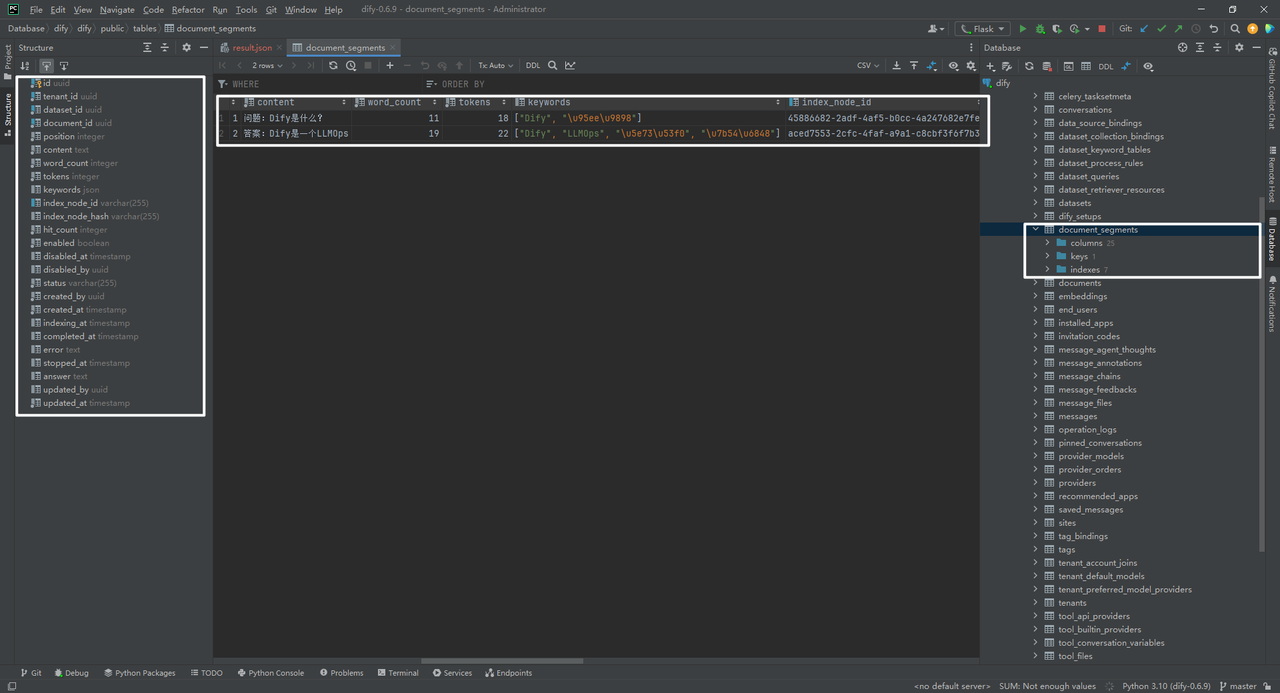
(1)index_node_id
索引节点id如下:
45886682-2adf-4af5-b0cc-4a247682e7fe
aced7553-2cfc-4faf-a9a1-c8cbf3f6f7b3
(2)index_node_hash
索引节点哈希值如下:
5.embeddings数据表
embeddings数据表:即知识库中每个文档的每个分段的嵌入编码。
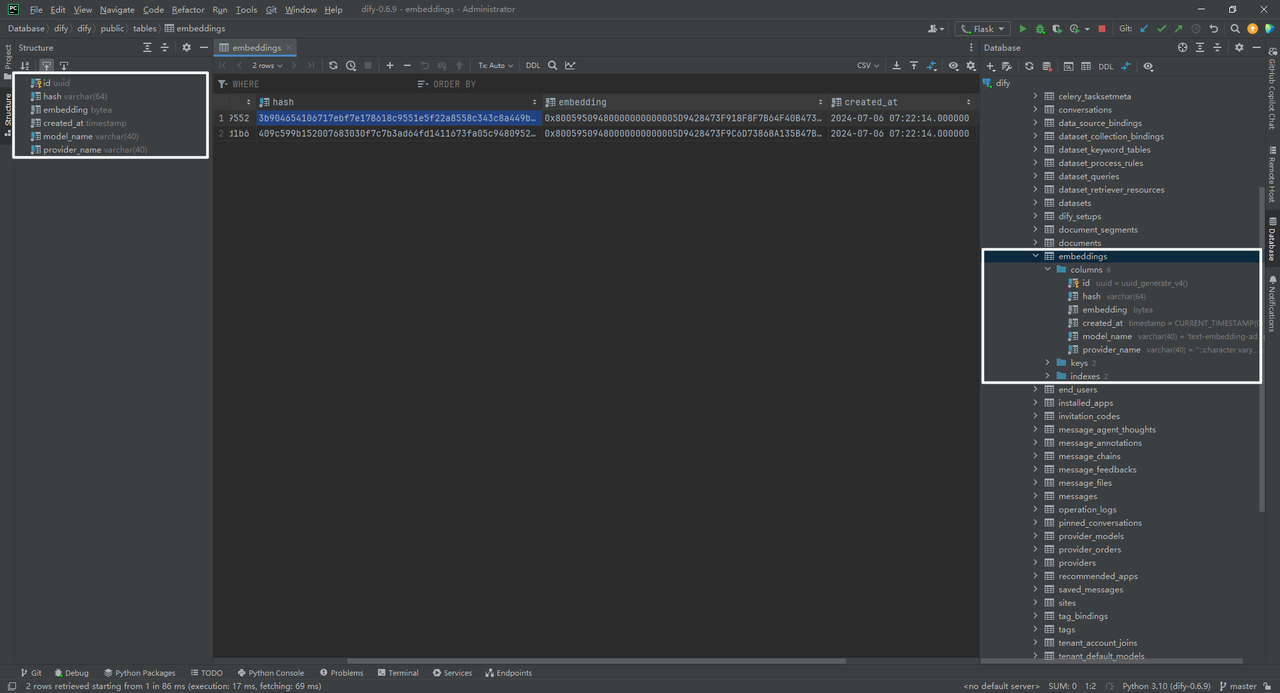
(1)embedding是什么
0x80059509480000000000005D942847......575481EC68652E
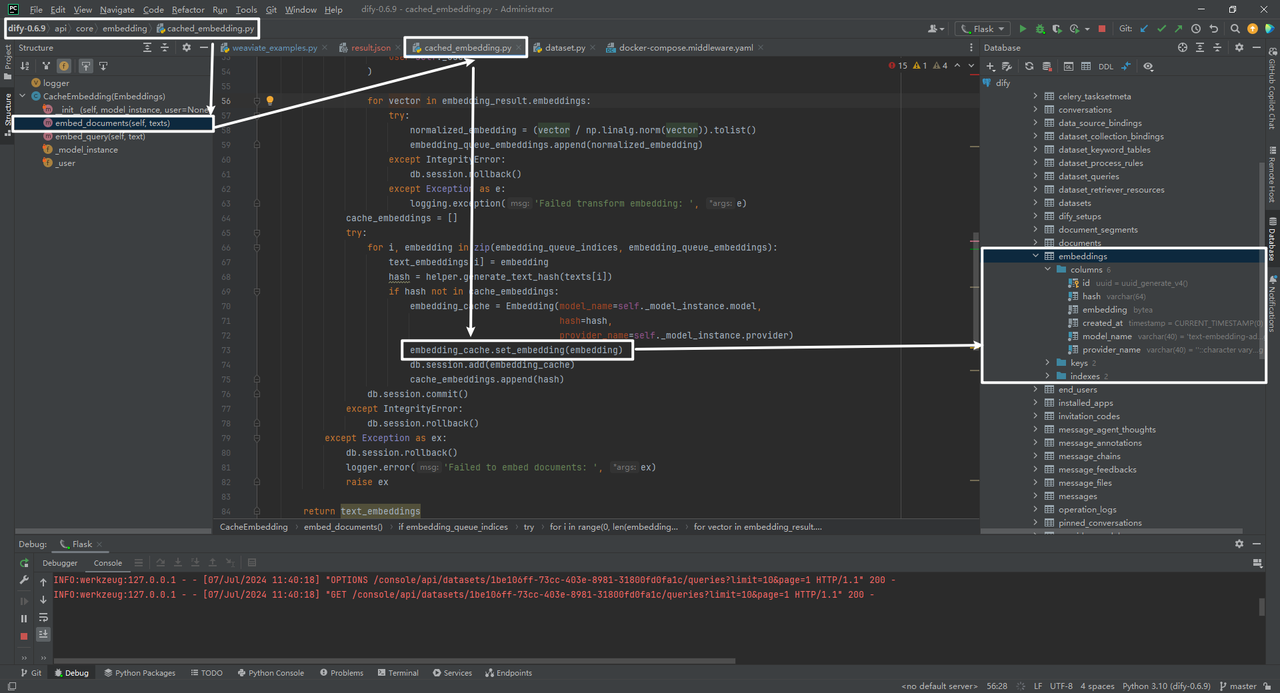
def set_embedding(self, embedding_data: list[float]):
self.embedding = pickle.dumps(embedding_data, protocol=pickle.HIGHEST_PROTOCOL)
这行代码使用 Python 的 pickle 模块将 embedding_data 对象序列化为一个字节流,以便于存储或传输。
-
pickle.dumps(embedding_data):pickle.dumps函数将embedding_data对象转换为一个字节流。这个字节流可以被存储或者传输,然后在需要的时候通过pickle.loads函数重新转换(反序列化)为原始对象。 -
protocol=pickle.HIGHEST_PROTOCOL:protocol参数是一个可选参数,用于指定序列化和反序列化时使用的协议版本。pickle.HIGHEST_PROTOCOL表示使用pickle模块当前支持的最高协议版本。不同的协议版本在功能和效率上有所不同,使用最高版本的协议通常可以获得最好的性能。
三.weaviate基本操作
1.weaviate连接和操作
首先连接weaviate客户端,然后查询指定class_name的schema和data_object。
import weaviate
WEAVIATE_URL = "http://127.0.0.1:8080"
WEAVIATE_API_KEY = "WVF5YThaHlkYwhGUSmCRgsX3tD5ngdN8pkih"
client = weaviate.Client(
url = WEAVIATE_URL, # 指向weaviate的url
auth_client_secret = weaviate.AuthApiKey(WEAVIATE_API_KEY) # 使用API k 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 380
380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











