







数据湖和湖格式
- 数据湖就是可以存放各种数据的地方,既有格式化数据又有非格式化数据,比如表,视频,图片这些,可以理解成一个文件系统,比如 hdfs,s3,cos。数据湖的对比是传统的数据表。
- 有些说法是说 Iceberg 和 Hudi这些是数据湖,这个是大家为了方便的一个叫法,如果严谨一点的话,hudi这些是应该是湖格式,它是建立在 hdfs 或者 cos 之上的一个管理数据的东西。
一、基于Hive数仓存在的问题
1.1 不支持ACID
- hive写动态分区的时候,不是原子性的,如果一个任务写多个分区,可能会出现有些分区已经就绪了,但是在生成剩余分区的时候任务失败了,这个时候下游如果配置的是表依赖,就会通过依赖检查,查出来部分数据
- 读操作和写操作没有隔离性,我们在读数据时,如果上游重写表,会把我们正在读的文件删除,这个时候我们的读任务就失败了
1.2不支持版本查询
- hive中的重写操作,都是直接将这个分区目录下所有的文件都删除了,然后再将新数据写入,这样存在一个问题是如果我们再重写完数据后,如果还想查之前的数据,就查不到了。这种情况一般用于验证数据的情景。
1.3 时效性与维护性不可兼得
etl链路是解析kafka数据落到cos,这个时候会生成很多小文件,等一小时数据全部就绪,再将之前落盘的数据做合并后生成hive的小时级分区,这时才可以用这一小时的数据,这一小时内最早的数据从产生到可用几乎延迟2小时。

那我们如果想早一点查到前5分钟的数据,基于这条etl链路是做不到的,我们需要新起一条实时链路来直接消费kafka中的数据,那么整体链路就会变成这样
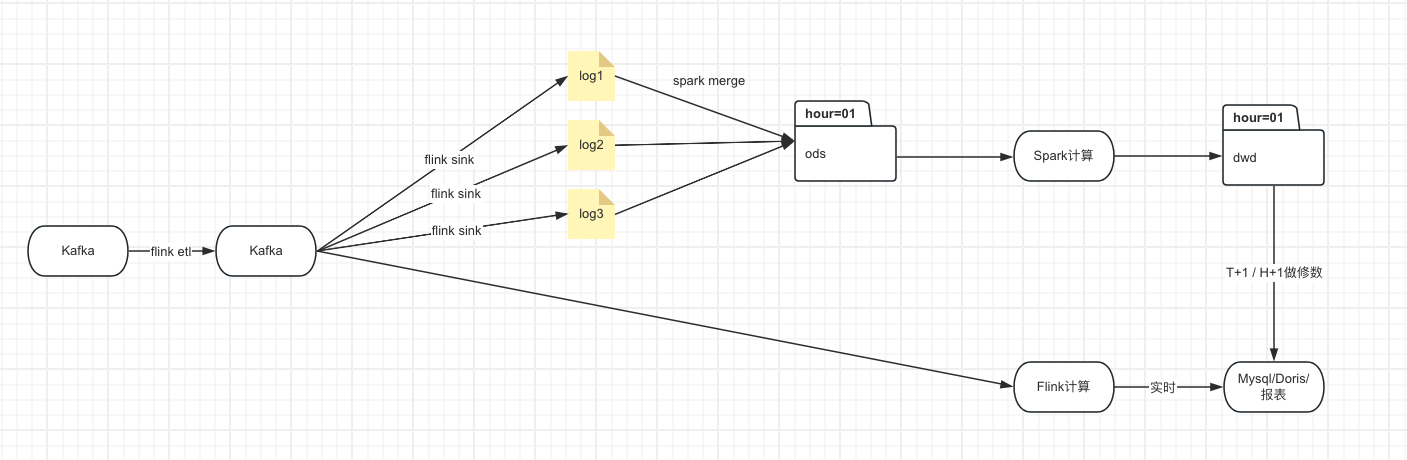
这样做存在的问题就是我们维护了两条相同的计算逻辑,一套在Spark,一套在Flink,每次改都需要改两个地方,维护成本高
1.4 查询优化不够
- 查询大量分区时list执行太长,对对象存储的压力很大
- min/max索引和布隆索引需要在读取出来文件后才能用。基于目前hive的功能,spark或者mr在启动任务切分task的时候,是基于文件级别切的。假设我们的日志数据是1T,在查询的point_name根据min/max索引过滤后只命中了10个文件,占1G,但是切文件的时候并不知道1G这个统计信息,它只知道总文件大小是1T,所以会产生 1T / 128MB = 8192个task,但其实只需要8个task
1.5 数据存储成本高
数据库入hive每天都全量
二、湖格式的解决方案
2.1 通过元数据实现ACID和多版本
2.1.1 ACID
-
湖格式将分区信息记录在了一个单独的表中,而不是仅仅依赖于存储目录,这样可以做到只有在任务完全跑成功后,才在元数据表中添加分区,可以避免只生成部分分区的问题。
例如Iceberg的原数据信息:
|file_path |file_format|partition | -------------------------------------------------------------------------|-----------|---------------| |action_logs/data/event_time_hour=2020-06-04-19/action=view/log1.parquet |PARQUET |[442027, view] | |action_logs/data/event_time_hour=2020-06-04-19/action=click/log2.parquet|PARQUET |[442027, click]| |action_logs/data/event_time_hour=2020-06-04-20/action=click/log3.parquet|PARQUET |[442028, click]|上表中action_logs表的partition字段(event_time_hour,action),第一个文件的对应partition是[442027, view],即[event_time_hour=442027, action=“view”],其他文件对应的partition以此类推。
-
湖格式在重写数据的时候,并不是直接重写以前的目录,而是将新数据写入新的目录,从而避免重写数据导致读任务失败。
-
Iceberg的实现
写入引擎调用Iceberg的commit接口,Iceberg主要会做如下几个事情:
- 会根据提交的文件解析出对应的文件元数据生成一个manifest文件,manifest文件中包含所有提交的数据文件的统计信息 (如文件大小、min/max索引等),每个数据文件在manifest文件中就是一条记录。
- manifest文件生成之后,会紧接着生成一个manifests文件。manifests文件中每条记录是这个表当前所有manifest文件统计信息集合。
- manifests文件生成之后,再紧接着生成一个snapshot文件(文件名为:v2-metadata.json,其中v2是当前snapshot的版本号snapshot文件记录这个snapshot对应的表schema信息、partition spec信息以及manifests文件的路径等。
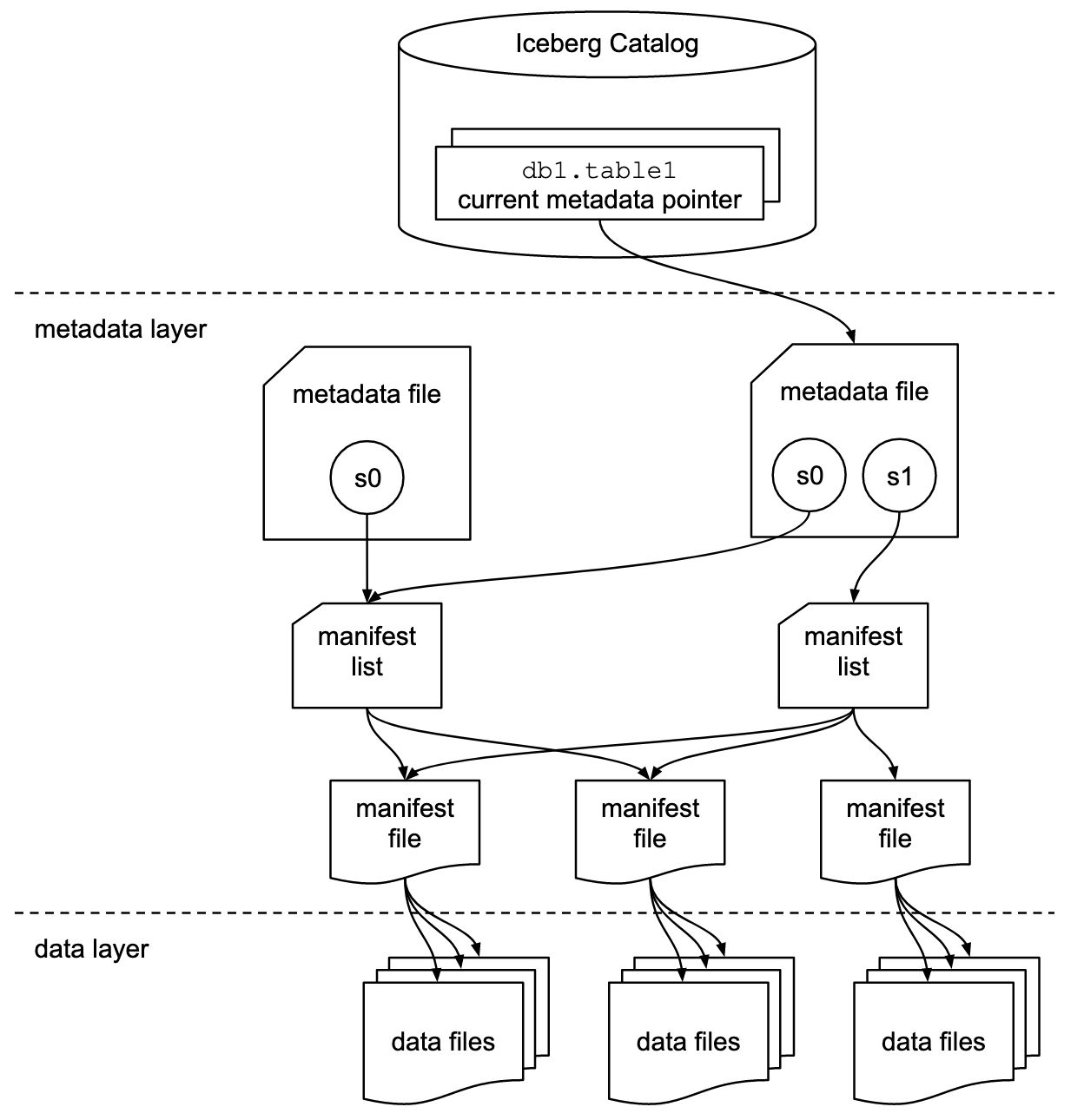
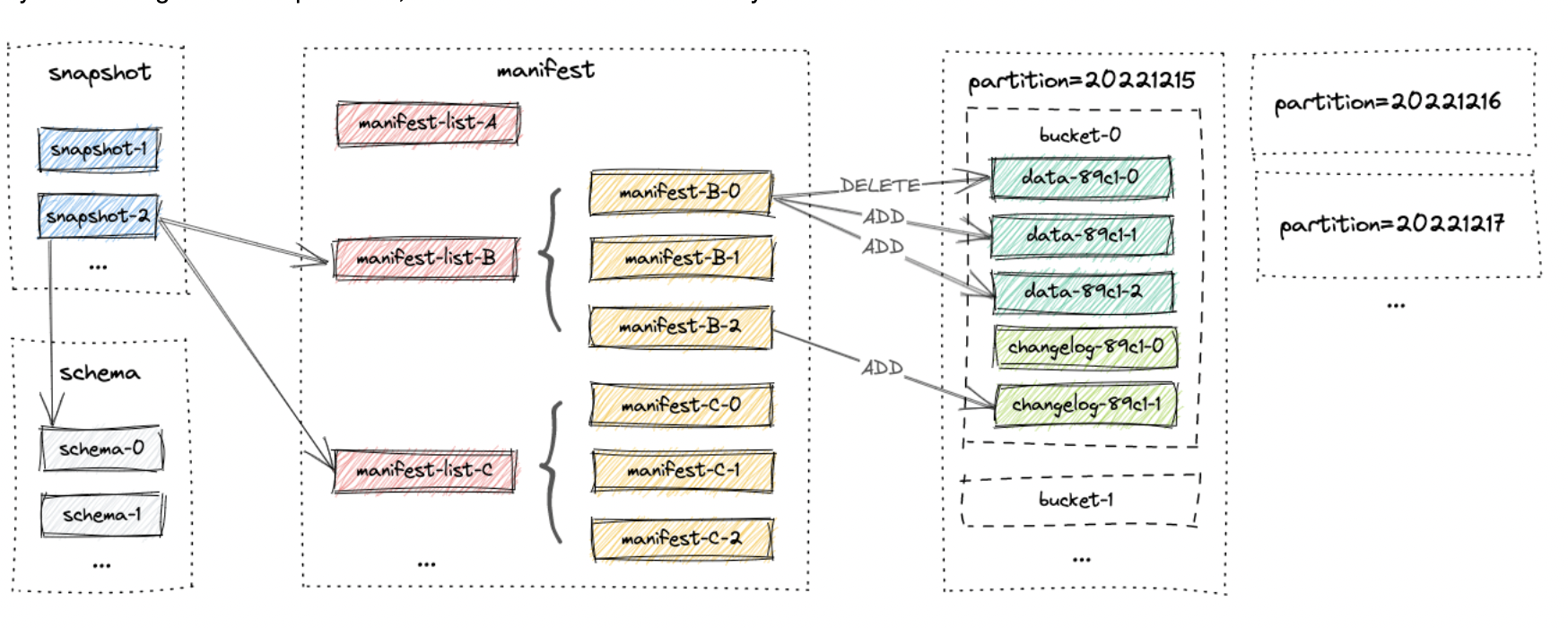
如下图是Iceberg文件的组织形式,在Catelog中记录了要指向的metadata file,metada file中记录了当前所有的版本snapshot,每个snapshot是独立的,一个snapshot对应着一个manifest list,这个list中包含了当前版本下所有提交的manifest file(多个list共用file),每个manifest file中存储着这次提交的data file。Iceberg的元数据相当于是有3层:manifest file -> manifest list -> metadata file。
-
Hudi的实现
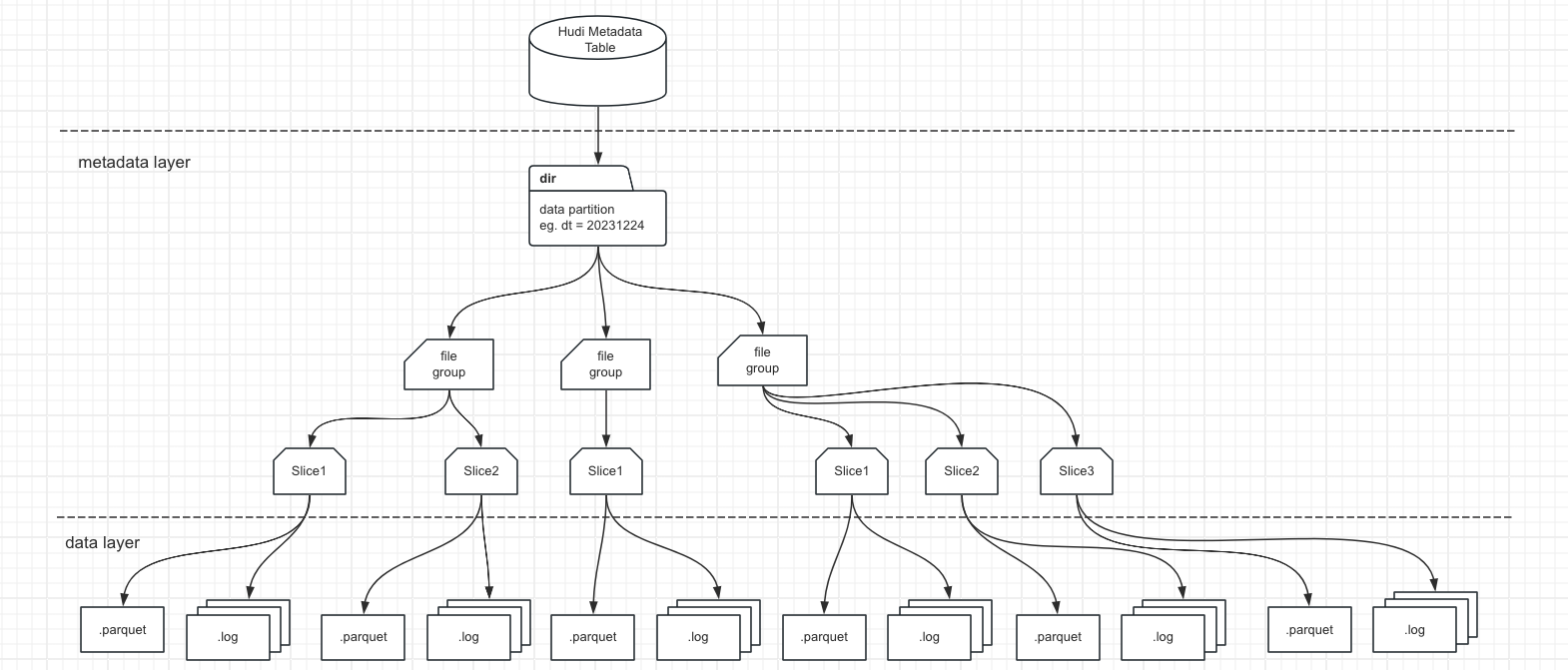
Hudi upsert数据的流程如下:
- 通过查找索引确定该数据所在的File Group,如果是MOR表,会在log文件中追加记录,如果是COW表,会直接重写parquet文件(这里用parquet来代替列式存储文件,也可能是orc文件)。
- Hudi会在固定的时间间隔来合并parquet和日志文件,避免读性能太差,在合并完之后,会生成新的Slice。
-
二者对比
- Hudi的版本控制是在文件级别的,Iceberg的版本控制是在snapshot级别的,一个snapshot下面会有很多文件
- 可以看出来Iceberg更适合insert模式,在upsert模式下,Merge On Read成本太大;而Hudi在upsert和insert模式下都可以用,insert就是跳过索引的upsert。
2.1.2 多版本
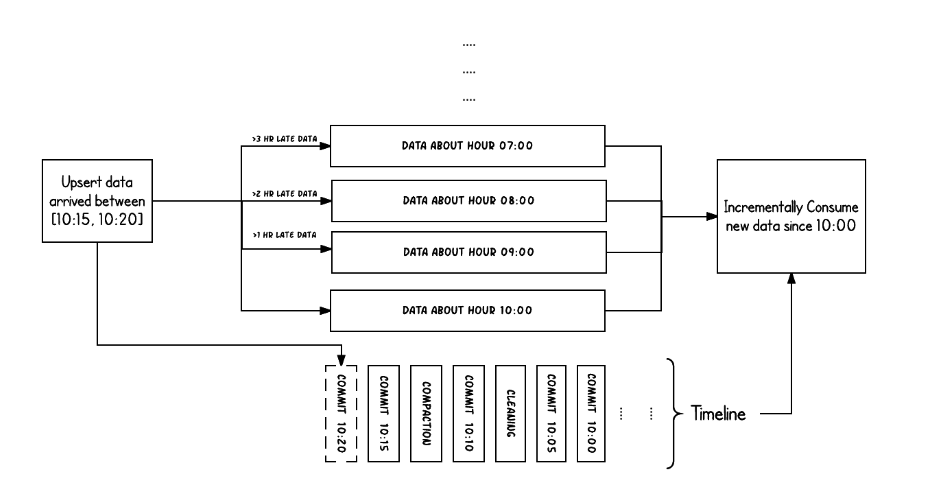
通过上文可以看到,在Iceberg中每次提交会生成新的snapshot,Hudi会每次生成新的Slice,那么在读的时候就可以指定要读取那个版本或者在什么时间以后提交的数据。
多版本的实现会和文件合并产生冲突,比如在Iceberg中,我们每次提交就会生成新manifest file,一个manifest file里又存储了这次提交的数据文件,如果提交频繁会产生很多小文件,所以必须定期将文件做合并,合并之后会生成新的manifest file,它可能是从之前多个manifest file生成出来的,然后再生成新的snapshot,这个时候就是一个新的版本。而之前的数据文件还不能删,因为可能有其他版本在用,所以必须定期清理过期的数据。
Hudi的slice同理。与Iceberg直接可以通过snapshot实现多版本不同的是,Hudi还需要一个时间轴来记录什么时候产生过提交以及影响的文件。
2.2 添加多种结构来优化查询
2.2.1 热数据缓存
把对象存储上的热数据缓存到执行节点的SSD或者内存中,可以提高查询效率。在事务保证的机制下可以容易地确定哪些缓存数据是失效的。
2.2.2 元数据中记录更多的索引信息
2.2.2.1 分区信息
试想,对于一个多级分区的大表来说,比如我们的点位日志表,一级分区是小时时间分区,二级分区是plat分区,有app和h5,三级分区是业务线定义的product分区,我们假设是10个,那么一天的分区个数就是480个。基于Metastore的partition方案,如果一个SQL想查这个表一天的数据的话,就需要向NameNode发480次list请求,如果是扫描一天或者一个月的数据,请求数就更夸张了。这样会导致两个问题,一方面是NameNode压力太大,另一方面是SQL请求响应延迟。我们写的Hive Sql经常会出现任务总执行时间是一小时,其中任务初始化就占了20多分钟。
在湖格式中,它在元数据表中存储了所有分区下的所有文件,这种就可以省去list操作。
2.2.2.2 文件信息、 min / max信息和布隆过滤器
min/max索引和布隆索引需要在读取出来文件后才能用。基于目前hive的功能,spark或者mr在启动任务切分task的时候,是基于文件级别切的。假设我们的日志数据是1T,在查询的point_name根据min/max索引过滤后只命中了10个文件,占1G,但是切文件的时候并不知道1G这个统计信息,它只知道总文件大小是1T,所以会产生 1T / 128MB = 8192个task,但其实只需要8个task。
在湖格式中,它在元数据表中存储了所有文件的文件统计信息以及列统计信息,包括文件大小、min/max索引和布隆过滤器,这样就可以在任务初始化生成task之前,就精准确定下来要读那些文件了。
2.2.2.3 key映射文件的索引
上一节中提到的min/max索引是一个范围的查询,可能我们要查的key在很多文件中都满足[min, max]的范围,那我们怎么能精确的定位到这个key到底是在哪个文件中呢?这个需要模仿数据库的实现,就建立key到文件的索引(目前只有Hudi有)
建立key到文件的索引意味着我们需要把所有key存下来,那么在存储的时候就需要考虑读性能与索引代价的权衡,Hudi目前支持以下几种索引(用的最多的是BLOOM、BUCEKT、RECORD_INDEX):
-
BLOOM:使用record key来构建一个布隆过滤器,还可以支持min/max机制,从而使用record key的范围来减少候选文件。在每个分区内要求Key是唯一的。然后当有新key要插入的时候,通过元数据文件检索那些文件可以命中布隆过滤器,如果命中,再做真实查找,所以如果假阳性高的话,会导致查文件的次数变多。(字节实践中发现在5000亿条数据的情况下,假阳性严重拖垮任务)
参考:https://www.cnblogs.com/bytedata/p/15945254.html -
GLOBAL_BLOOM:构建方式及min/max机制与BLOOM索引一样,区别在于GLOBAL BLOOM要求Key在整个表内唯一。
-
SIMPLE(default for Spark):Spark的默认索引。将已到达的Key存储在表中,新来的Key与历史Key做join。在每个分区内要求Key是唯一的。
-
GLOBAL_SIMPLE:与SIMPLE索引一样,区别在于GLOBAL SIMPLE要求Key在整个表内唯一。
-
HBASE:将索引存储在HBase表中,要求Key在整个表内唯一。
-
INMEMORY(default for Flink and Java):在Spark和Java程序中,使用内存中的hashmap;在Flink程序中,使用内存中的状态。
-
BUCKET:字节贡献的一个索引机制,它是一种基于哈希的索引,借鉴了数据库里的 Hash Index。给定 n 个桶, 用 Hash 函数决定某个记录属于哪个桶。最终所有分区被分成 N 个桶,每个桶对应一个 File Group。
相比较 Bloom Filter Index 来说,Hash Index 在逻辑层面提供了 Record Key 跟 File Group 的映射关系, 不存在假阳性问题。相同 key 的数据一定是落在同一个桶里面。
-
RECORD_INDEX:Hudi将元数据信息存到一个MOR表中,这个表的底层实现是HFile(数据文件和log文件都用HFile,而不是Parquet+Avro,可以提升查询效率),用来模拟HBASE来提供内置高效的索引服务。元数据表中存储record key和文件组的映射关系。Record index是一个全局索引,要求表中所有分区的key必须唯一。
| 索引 | 优点 | 缺点 |
|---|---|---|
| BLOOM | 轻量级,默认的索引方式,包含在数据文件的footer中,不依赖外部系统 | 可能发生假阳性,当假阳性高时,查询成本变大 |
| SIMPLE | Spark默认,使用简单 | 当插入较为频繁时,join的次数太多,效率降低 |
| HBASE | 对于小批次的keys,查询效率高 | 依赖外部系统,提升运维代价 |
| INMEMORY | Flink默认,使用简单,在hashmap中存储查找效率也高 | 对内存的压力太大 |
| BUCKET | 轻量级,spark和flink都支持,在大数据量下没有BLOOM假阳性的问题 | Shuffle数据量大 |
| RECORD_INDEX | Hudi内置的高效的查询索引,可以替代HBASE | 按照官方所说,是综合性能做好的 需要把每个Key都存下来,存储占用大 |
2.2.2.4 支持更高级的数据分布
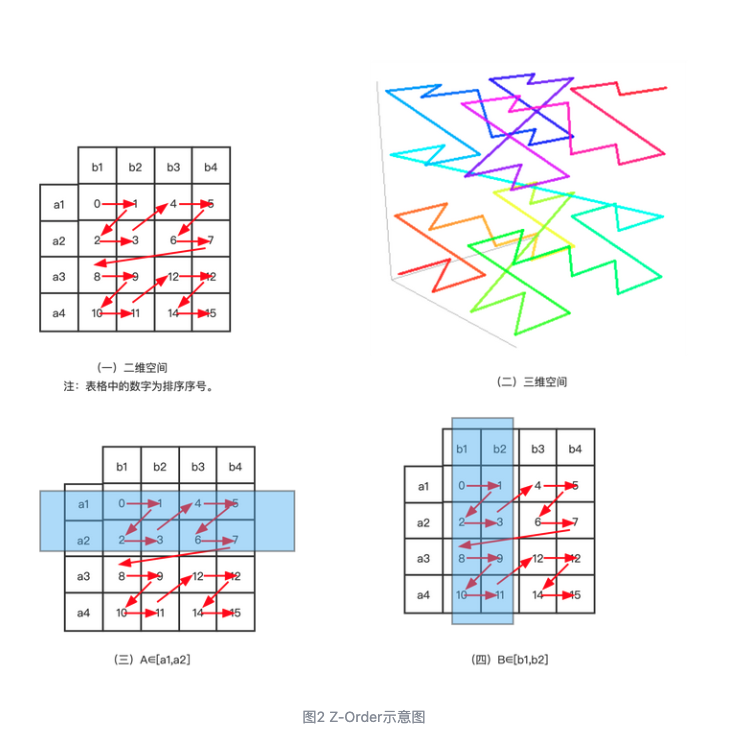
Z-Order和Hilbert曲线,把二维数据映射到一维的一种思路
假设我们有数据
| uid | score |
|---|---|
| 1 | 10 |
| 1 | 20 |
| 1 | 30 |
| 2 | 10 |
| 2 | 20 |
| 2 | …很多行 |
| 3 | 10 |
| 3 | 20 |
| 3 | 30 |
| 4 | 20 |
按照上面的按照uid + score排序,我们在查询uid = 2 and score >= 10 and score <= 20这样的语句时很有用,相同的uid已经放在一起了,但如果我们要查socre = 10 and uid >= 2 and uid <= 3这样的语句时就不行了,因为相同的score间隔太远了;同理,如果按照score + uid做排序,如果查socre = 10 and uid >= 2 and uid <= 3这样的语句很有用,但是如果查uid = 2 and score >= 10 and score <= 20就不行了,因为相同的uid间隔太远了。那么有没有一种把相同的uid和相同的score都放的聚集的思路呢?就是把二维映射到一维做排序。
Z-order是一种折衷的排序算法,在用的时候需要考虑自己的场景
2.3 基于增量查询实现流批一体
2.3.1 流读的时效性
在2.1.1中,我们看到了湖格式会记录每次在提交后都会有相应的snapshot或者在时间轴上有记录,那么我们就可以通过这个点来实现增量式读取,比如读取从哪个版本以后的,或者是从哪个时间戳提交的以后的数据。
我目前的理解是在insert的场景下,Iceberg和Hudi都可以做到分钟级延迟,但是在upsert的场景下,Iceberg因为没有索引,会导致合并数据的成本很大,肯定无法做到分钟级延迟。
2.3.2 批读的吞吐量
回到1.3中的架构图,我们会发现在实时场景下面,离线链路充当的作用是给实时数据做修数用的,修数的原因是可能有乱序问题导致实时数据算的不准,这种方案被称为Lambda架构。
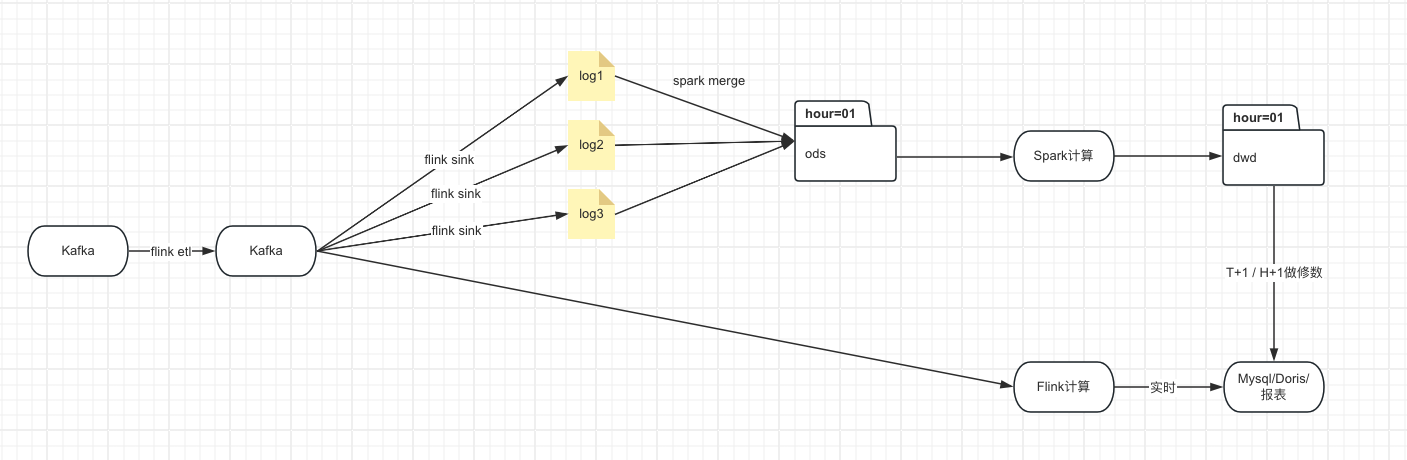
可以看到Lambda其实就是一个重跑机制,为了保障数据的准确性我们需要维护两条链路,那么我们如果实时链路可以重跑的话,是不是可以把只保留一条链路呢?比如像是下图的这种,在kafka里保存历史数据,把离线链路砍掉,在重新运行的时候直接重跑实时程序,也可以实现Lambda架构的效果。参考:Kappa架构
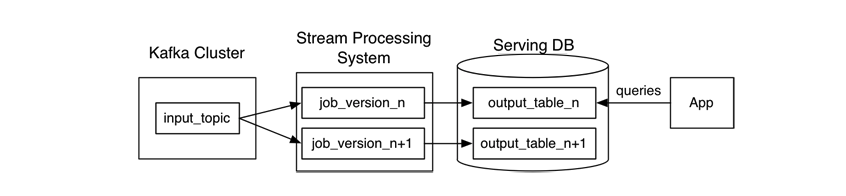
但是这种存在问题:
- Kafka中保留的数据太多,贵
- Kafka的吞吐量不够大
- 实时程序框架需要既支持批处理功能,又支持流处理功能
因为上述的三个问题(主要是1和2)导致基于Kafka的流批一体没有做起来,现在有了湖格式,基于湖格式的增量读取,我们就可以实现一个近实时的数据拉取(近实时是因为对于insert数据源,它需要上游做commit才能落表;对于upsert数据源,既需要commit,又需要做merge)。如下图是目前主流的一种流批一体的实现
老架构:
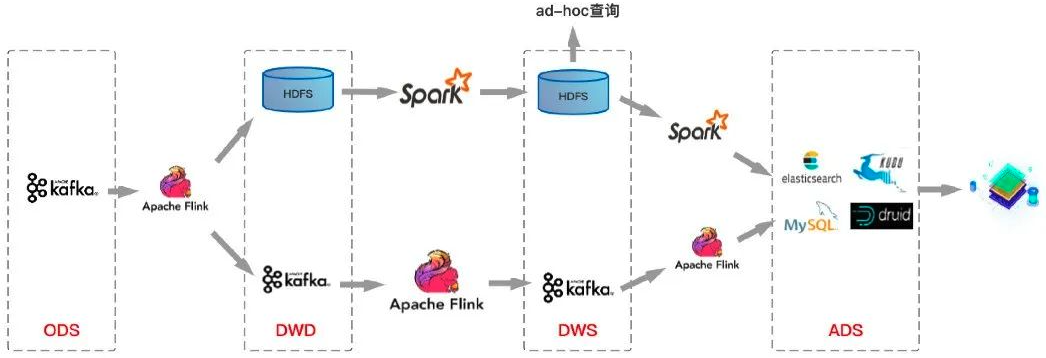
新架构:
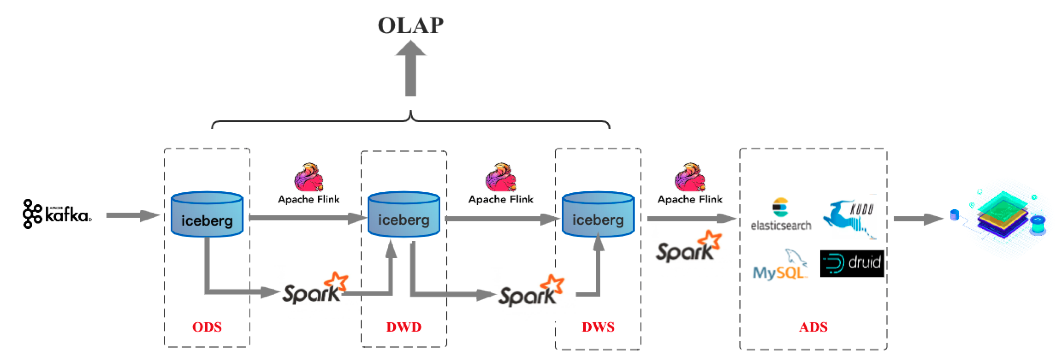
可以看到,上述的新架构中在存储层面实现了统一,但是在计算层面还是一套Flink、一套Spark,这是因为目前Flink对于批处理模式支持的还不算好,Flink今年的发布会也强调了后续要加强批处理模式的支持,争取做到业界一流的水平。Spark对于实时数据的处理不太好,但是我个人感觉在近实时的场景下,可以把Flink换成Spark Streaming。
三、对比Iceberg、Hudi、Paimon
- Iceberg的文件布局如下
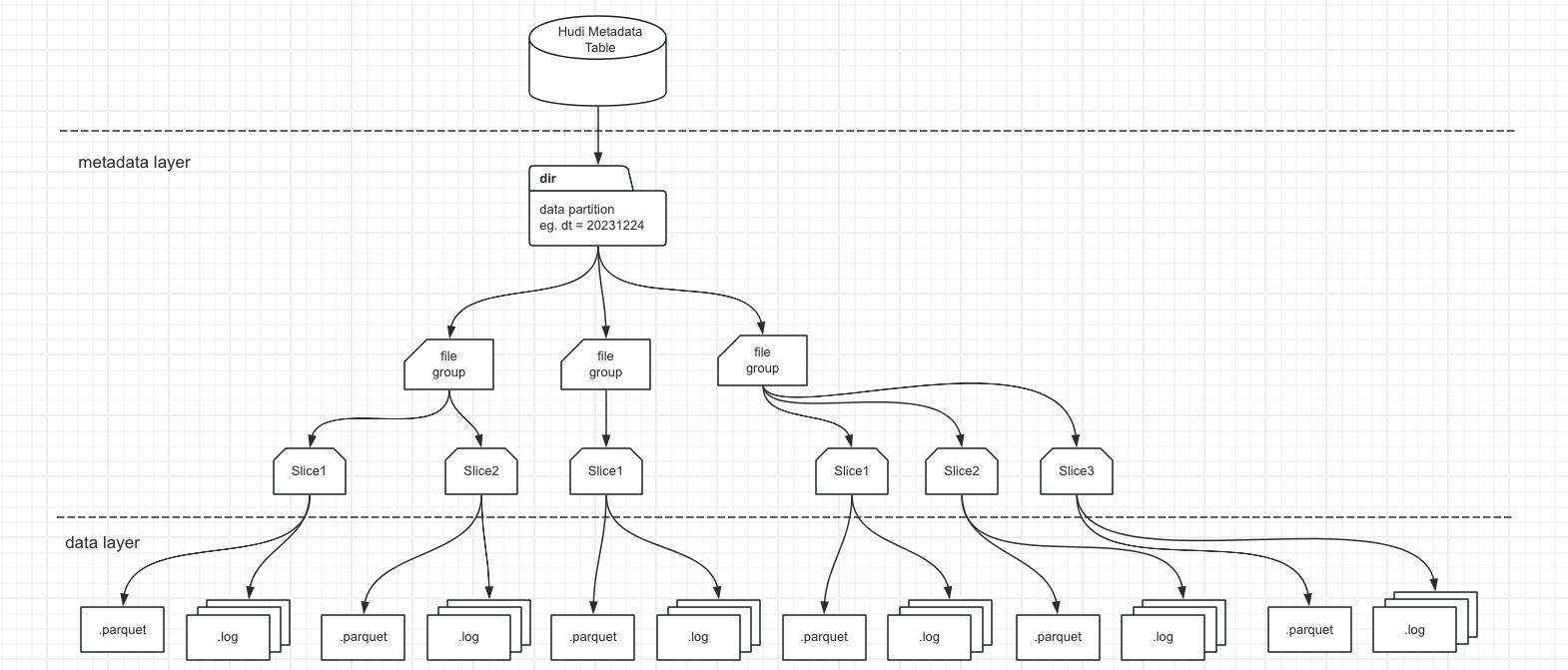
- Hudi的文件布局如下:
- Paimon的文件布局如下:
- Paimon的架构图和Iceberg几乎一致,但是它的底层文件存储用的不是orc/parquet + avro,而是用的LSM树进行存储的,这样可以在查找的时候用二分查找,比Iceberg的快。
- 为了支持快为什么不用Hudi呢?Hudi的索引维护起来比较费时,且Hudi对Flink的支持不太好,按照Paimon开发者的话来说就是为了加入一个小的功能,需要天翻地覆的重构,大重构又会诞生很多的 Bugs,还不一定能支持的很好。
| 特性 | Iceberg | Hudi | Paimon |
|---|---|---|---|
| Schema变更 | 支持 | 不支持 | 支持 |
| Upsert | 支持,但是慢 | 支持且快 | 支持且快 |
| 对Flink集成度 | 一般 | 一般 | 好 |
| 存储成本 | 小 | 大 | 最大 |

















 727
727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









