







说点真实的感受 :网上看啥组件都好,实际测,啥组件都不行。效果好的不开源收费,开源的效果不好。测试下来,发现把组件融合起来,还是能不花钱解决问题的,都是麻烦折腾一些。这里分享了目前网上能够看到的资料。很多资料都是反复重复的,且效果不好的。目前网上基本没有太好用的工具,也没有太好的方案资料。剩下的就是收费效果好的。
PDF解析中的诸多挑战
版面分析:如何得到标题、如何的得到段落(正确的段落)、如何得到表格、如何得到图片,图和得到图片上的文字?
还有细节问题:双栏和多栏的问题、公式问题
扫描件:扫描件本质上是图片,如何从图片中解析得到文件。
PDF解析的主要思路
针对上述的挑战,PDF解析主要分为两个方向。一是标准PDF文件,程序可读。二是扫描文件,实际上就是图片,程序不可直接读。
- 解析和结构分析: PDF 抓取工具首先解析 PDF 文件并分析其结构以识别文档中的各种元素。 解析涉及检查布局、字体样式、表格、标题和其他结构组件,以了解内容的组织和安排。
- 文本提取: 然后,该工具采用 OCR 技术将扫描或基于图像的 PDF 转换为机器可读的文本。 OCR 算法通过分析 PDF 中的视觉数据并识别字符,将其转换为可编辑和可搜索的文本来实现此目的。
- 数据提取和模式识别: 一旦数据转换为机器可读格式,PDF 抓取工具就会应用模式识别算法来识别文本中的特定数据点,例如文档中的关键字、模式或预定义结构。 例如,抓取工具可以根据预定规则或正则表达式查找发票号码、日期、客户姓名或产品详细信息。
- 输出和格式: 然后,PDF 抓取工具将提取的数据组织成相关字段和结构化格式,例如电子表格、数据库或 JSON/XML,以供进一步分析。
OCR解析的路线
OCR是唯一的解决扫描版文件的方案,包括获取图片上的内容。
unstructured
Paddle-structure
Meta的版面恢复大模型:Nougat
Meta的版面恢复大模型:Nougat | Breezedeus.com
Nougat被戏称为富人的玩具。有一段这样的描述,就知道它有多慢了!“在一台配备有24GB VRAM的NVIDIA A10G显卡的机器上,可以并行处理6页内容。生成速度在很大程度上取决于给定页面上的文本量。在没做任何推理优化时,按平均每页有 ~1400 个 tokens算,Nougat base模型处理一个batch图片的平均时间为19.5秒。”
Nougat:结合光学神经网络,引领学术PDF文档的智能解析、挖掘学术论文PDF的价值 - 汀、人工智能 - 博客园
P2T检查走小模型的路线,目前拿来做内容识别还是OK的,特别是在公式方面。

PDF 解析工具对比
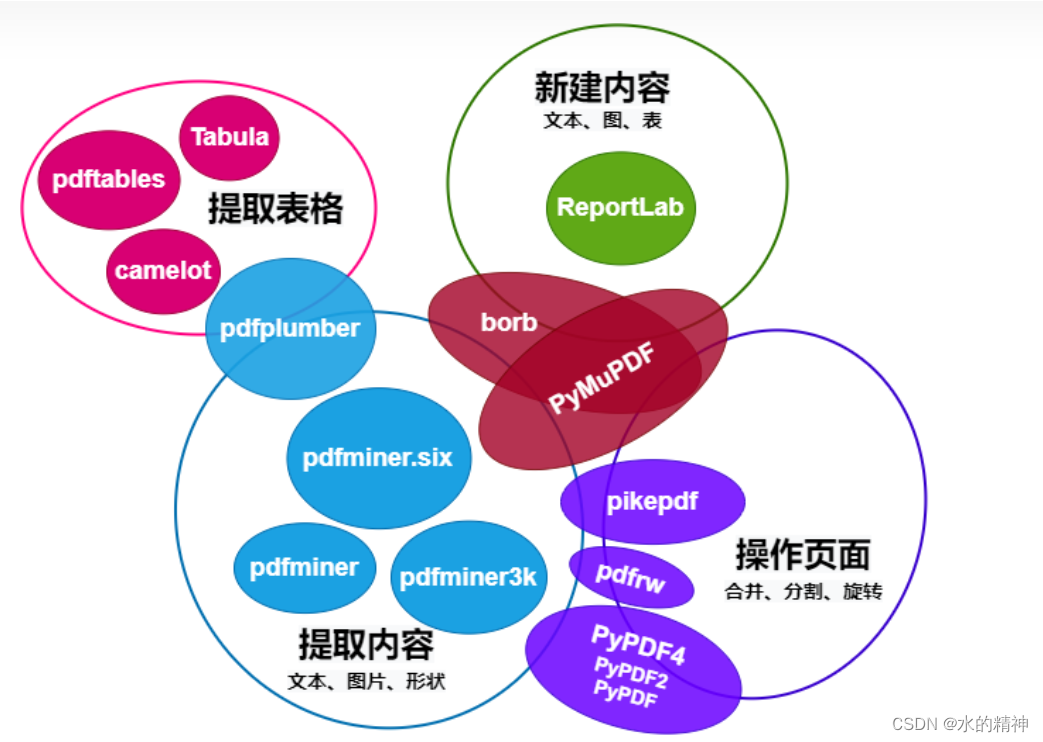
大模型RAG问答下的实用开源文档解析工具总结及技术思考:从文档版本分析到单双栏处理
可以拿到bbox的组件
pdfplunber pdfminer pymupdf papermage 这些组件是不是都可以拿到bbox?
- pdfplumber:pdfplumber 是一个基于 PDFMiner 的 Python 库,专门用于提取 PDF 文件中的文本和表格数据。它提供了一些方法来获取文本、表格和页面的 bounding box 信息。
- pdfminer:PDFMiner 是一个功能强大的 PDF 处理工具,可以用于提取 PDF 文件中的文本和布局信息。通过 PDFMiner,你可以获取文本、图片、表格等元素的位置信息,从而获得它们的 bounding box。
- pymupdf:PyMuPDF(也称为MuPDF)是一个用于处理 PDF 文件的 Python 库,提供了丰富的功能,包括提取文本、图像和其他元素的信息,以及获取它们的 bounding box。
- papermage:Papermage 是一个用于处理 PDF 文件的 Python 库,它使用了 PDFMiner 和其他一些工具,可以用于提取 PDF 文件中的文本、图像和布局信息,包括 bounding box。
可以拿到bbox的组件组件对比
- pdfplumber:
- 优点:pdfplumber 提供了简单易用的接口,使得提取文本和表格数据以及获取 bbox 变得非常方便。
- 它能够准确地提取文本的 bbox,并且支持表格的识别和提取。
- 在处理包含复杂布局的 PDF 文件时表现较好。
- 缺点:对于处理包含大量图像的 PDF 文件时,性能可能不如其他库。
- 对于一些特殊格式的 PDF 文件,可能会出现解析错误。
- 优点:pdfplumber 提供了简单易用的接口,使得提取文本和表格数据以及获取 bbox 变得非常方便。
- pdfminer:
- 优点:PDFMiner 是一个功能强大且灵活的库,可以用于处理各种类型的 PDF 文件。
- 它提供了丰富的功能和选项,使得用户可以对文本和布局信息进行更深入的处理和分析。
- 缺点:相比于其他库,PDFMiner 的接口相对较复杂,需要更多的代码来实现相同的功能。
- 在处理复杂布局的 PDF 文件时,可能需要额外的调整和处理,以获得准确的 bbox 信息。
- 优点:PDFMiner 是一个功能强大且灵活的库,可以用于处理各种类型的 PDF 文件。
- pymupdf:
- 优点:PyMuPDF(MuPDF)是一个快速和高效的 PDF 处理库,对于大型 PDF 文件的处理效率较高。
- 它提供了一些简单的方法来获取文本、图像和布局信息,并且可以准确地提取 bbox。
- 缺点:PyMuPDF 的文档和社区支持相对较少,有时可能需要进行一些自行探索和调试。
- 优点:PyMuPDF(MuPDF)是一个快速和高效的 PDF 处理库,对于大型 PDF 文件的处理效率较高。
- papermage:
- 优点:Papermage 是一个基于 PDFMiner 和其他一些工具构建的库,它提供了一些简单的接口来处理 PDF 文件。
- 它支持获取文本、图像和布局信息,并且能够准确地提取 bbox。
- 缺点:Papermage 相对较新,可能还不够成熟,可能存在一些功能上的限制和问题。
- 相比于其他库,Papermage 的文档和社区支持较少。
- 优点:Papermage 是一个基于 PDFMiner 和其他一些工具构建的库,它提供了一些简单的接口来处理 PDF 文件。

















 1160
1160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









