






RNN
特点:输入层是层层相关联的,输入包括上一个隐藏层的输出h1和外界输入x2,然后融合一个张量,通过全连接得到h2,重复
优点:结构简单,参数总量少,在短序列任务上性能好
缺点:在长序列中效果不好,容易梯度提升或者爆炸
import torch
import torch.nn as nn
import torch.nn.functional as F
# 参数一: 输入张量的词嵌入维度5, 参数二: 隐藏层的维度(也就是神经元的个数), 参数三: 网络层数
rnn = nn.RNN(5, 6, 2)
# 参数一: sequence_length序列长度, 参数二: batch_size样本个数, 参数三: 词嵌入的维度, 和RNN第一个参数匹配
input1 = torch.randn(1, 3, 5)
# 参数一: 网络层数, 和RNN第三个参数匹配, 参数二: batch_size样本个数, 参数三: 隐藏层的维度, 和RNN第二个参数匹配
h0 = torch.randn(2, 3, 6)
output, hn = rnn(input1, h0)
# print(output.shape)
# torch.Size([1, 3, 6])
# print(hn.shape)
# torch.Size([2, 3, 6])
LSTM
解决了RNN的缺点,在长序列中效果好,现在仔细研究中间图的结构

最左边是的黄色矩形部分是遗忘门,就是结合前一层的的h1+输入x2拼接,然后经过全连接层后输出ft,就是把之前的一些信息遗忘一部分,
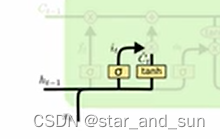
第二第三是一部分输入门,拼接完过后经过全连接结合σ激活函数it,以及拼接后用一个tanh激活函数ct,然后和上一层的结合起来
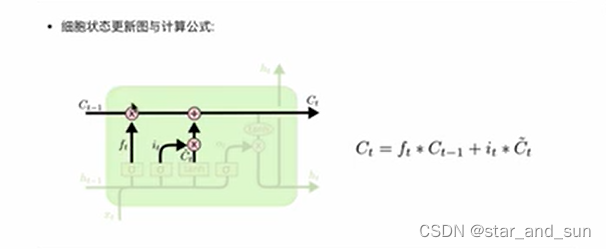
第三部分是输出门,图的右边黄色的矩形到结尾
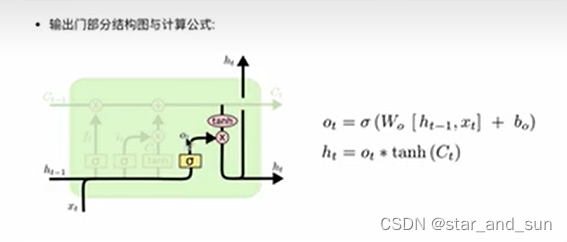
此外Bi-LSTM,是双向的,相当于运用了两层LSTM但是方向不同,前面是单向的,信息从左到右的的传递相当于考虑前面的信息,Bi-LSTM是左右信息都考虑,然后拼接结果
# -------------------------------------
import torch
import torch.nn as nn
lstm=nn.LSTM(5,6,2)
input=torch.randn(1,3,5)
h0=torch.randn(2,3,6)
c0=torch.randn(2,3,6)
output,(hn,cn)=lstm(input,(hn,cn))
#-------------------------
class Attention(nn.Module):
def __init__(self, query_size, key_size, value_size1, value_size2, output_size):
super(Attention, self).__init__()
self.query_size = query_size
self.key_size = key_size
self.value_size1 = value_size1
self.value_size2 = value_size2
self.output_size = output_size
self.attn = nn.Linear(self.query_size + self.key_size, self.value_size1)
self.attn_combine = nn.Linear(self.query_size + self.value_size2, self.output_size)
def forward(self, Q, K, V):
attn_weights = F.softmax(self.attn(torch.cat((Q[0], K[0]), 1)), dim=1)
attn_applied = torch.bmm(attn_weights.unsqueeze(0), V)
output = torch.cat((Q[0], attn_applied[0]), 1)
output1 = self.attn_combine(output).unsqueeze(0)
return output1, attn_weights
query_size = 32
key_size = 32
value_size1 = 32
value_size2 = 64
output_size = 64
attn = Attention(query_size, key_size, value_size1, value_size2, output_size)
Q = torch.randn(1, 1, 32)
K = torch.randn(1, 1, 32)
V = torch.randn(1, 32, 64)
res = attn(Q, K, V)
# print(res[0])
# print(res[0].shape)
# print('*****')
# print(res[1])
# print(res[1].shape)
# --------------------------------------------















 316
316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









