







c++版本引入学习(98/11/14/17)
文章目录
1.语言上的强化
1.1变量
1.1.1 nullptr
c++11之前:c++会使得NULL,0,两个变量是一个东西,从而无法区分;(有些编译器会将 NULL 定义为 ((void*)0),有些则会直接将其定义为 0);
弊端:
c++不允许直接将 void * 隐式转换到其他类型;
void foo(int);
void foo(char*);
转换不了void*,编译器只能转换成0,导致 C++ 中重载特性发生混乱;(这里会调用foo(int));
c++11之后:
引入了 nullptr 关键字,专门用来区分空指针、0。而 nullptr 的类型为 nullptr_t,能够隐式的转换为任何指针或成员指针的类型,也能和他们进行相等或者不等的比较
nullpter-》char*
o->int
1.1.2 constexpr
c++11之前:
缘由:编译器能够在编译时就把这些表达式直接优化并植入到程序运行时,增加程序的性能
const关键字;
弊端:数组的长度必须是一个常量表达式
#include <iostream>
//常量
int len_foo() {
int i = 2;
return i;
}
//常量表达式
constexpr int len_foo_constexpr() {
return 5;
}
int main() {
int len = 10;
// char arr_3[len]; // len是常量
const int len_2 = len + 1;
constexpr int len_2_constexpr = 1 + 2 + 3;
// char arr_4[len_2]; // 非法 这是一个 const 常数,而不是一个常量表达式
char arr_4[len_2_constexpr]; // 合法
char arr_5[len_foo()+5]; // 非法 len_fo会返回一个常量
char arr_6[len_foo_constexpr() + 1]; // 合法
return 0;
}
c++11之后:constexpr 让用户显式的声明函数或对象构造函数在编译期会成为常量表达式;
1.1.3 元组 std::tuple
C++11 新增了 std::tuple 容器用于构造一个元组,进而囊括多个返回值
std::tuple<int, double, std::string> f() {
return std::make_tuple(1, 2.3, "456");
}
int main() {
auto [x, y, z] = f();
std::cout << x << ", " << y << ", " << z << std::endl;
return 0;
}
弊端:11-14无法使用简单的方法取出特定的元素,目前使用std::tie拆包;
1.2 类型推导
1.2.1 auto (自动类型推导)
for(vector<int>::const_iterator it = vec.cbegin(); itr != vec.cend(); ++it)
->
for(auto it = vec.bengin();it!=vec.end;++it)
auto i = 5; // i 被推导为 int
auto arr = new auto(10); // arr 被推导为 int *
注意:
auto auto_arr2[10] = {arr}; // 错误, 无法推导数组元素类型
报错信息:
2.6.auto.cpp:30:19: error: 'auto_arr2' declared as array of 'auto'
auto auto_arr2[10] = {arr};
1.2.2 decltype(与auto一样)
decltype的类型推导并不是像auto一样是从变量声明的初始化表达式获得变量的类型,而是总是以一个普通表达式作为参数,返回该表达式的类型,而且decltype并不会对表达式进行求值
int i = 4;
decltype(i) a; //推导结果为int。a的类型为int。
auto x = 1;
auto y = 2;
decltype(x+y) z;
auto+decltype一起使用,推导出返回值的类型;在c++14被摒弃;
template<typename T, typename U>
auto add(T x, U y) -> decltype(x+y){
return x + y;
}
->合法化: 普通函数也具有返回值类型的推导;
template<typename T, typename U>
auto add(T x, U y){
return x + y;
}
1.2.3 区间for迭代
int main() {
std::vector<int> vec = {1, 2, 3, 4};
if (auto itr = std::find(vec.begin(), vec.end(), 3);
itr != vec.end())
*itr = 4;
for (auto element : vec)
std::cout << element << std::endl; // read only
for (auto &element : vec) {
element += 1; // writeable
}
for (auto element : vec)
std::cout << element << std::endl; // read only
}
1.2.4 > 括号
在传统 C++ 的编译器中,>>一律被当做右移运算符来进行处理。
std::vector<std::vector<int>> matrix;//c++11之前非法
c++11之后合法
1.3 初始化列表
C++11 把初始化列表的概念绑定到了类型上,并将其称之为 std::initializer_list,允许构造函数或其他函数像参数一样使用初始化列表
class MagicFoo {
public:
std::vector<int> vec;
MagicFoo(std::initializer_list<int> list) {
for (std::initializer_list<int>::iterator it = list.begin();
it != list.end(); ++it)
vec.push_back(*it);
}
};
int main() {
MagicFoo magicFoo = {1, 2, 3, 4, 5};
for (std::vector<int>::iterator it = magicFoo.vec.begin(); it != magicFoo.vec.end(); ++it)
std::cout << *it << std::endl;
}
1.4 变长参数模版
递归表达:
template<typename T, typename... Ts>
void printf1(T value, Ts... args) {
std::cout << value << std::endl;
printf1(args...);
}
int main() {
printf1(1, 2, "123", 1.1);
return 0;
}
弊端:
虽然使用了变参模板,却不一定需要对参数做逐个遍历,我们可以利用 std::bind 及完美转发等特性实现对函数和参数的绑定
1.5 lambda表达式
lambda也分为值拷贝,引用拷贝,在使用lambda表达式需要注意;
[捕获列表](参数列表) mutable(可选) 异常属性 -> 返回类型 {
// 函数体
}
排序例子;
int main()
{
vector<int> myvec{ 3, 2, 5, 7, 3, 2 };
vector<int> lbvec(myvec);
sort(lbvec.begin(), lbvec.end(), [](int a, int b) -> bool { return a < b; }); // Lambda表达式
cout << "lambda expression:" << endl;
for (int it : lbvec)
cout << it << ' ';
}
外部变量:
int main()
{
int a = 123;
auto f = [a] { cout << a << endl; }; // 捕获外部变量a
f(); // 输出:123
auto x = [](int a){cout << a << endl;}(123); //输入参数
}
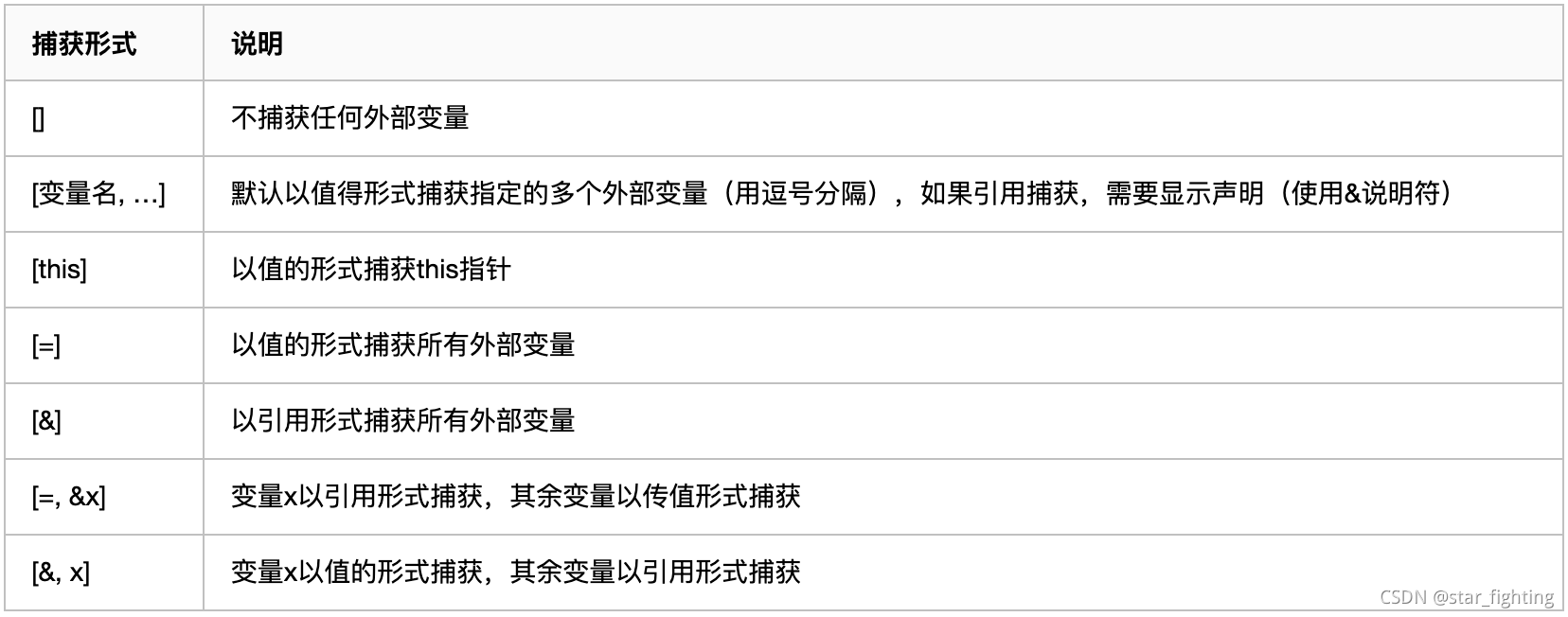
mutable关键字,该关键字用以说明表达式体内的代码可以修改值捕获的变量`
int main()
{
int a = 123;
auto f = [a]()mutable { cout << ++a; }; // 不会报错
cout << a << endl; // 输出:123
f(); // 输出:124
}
1.6 函数对象包装器 std::function
std::function 是一种通用、多态的函数封装, 它的实例可以对任何可以调用的目标实体进行存储、复制和调用操作(函数的容器)-》能够更加方便的将函数、函数指针作为对象进行处理
std::bind
std::placeholder
int foo(int a,int b,int c) {
}
int main()
{
//将参数1,2绑定到函数 foo 上,但是使用 std::placeholders::_1 来对第一个参数进行占位
auto bindFoo = std::bind(foo,std::placeholders::_1,1,2);
bindFoo(1);
}
#include <iostream>
#include <functional>
void fn(int n1, int n2, int n3) {
std::cout << n1 << " " << n2 << " " << n3 << std::endl;
}
int fn2() {
std::cout << "fn2 has called.\n";
return -1;
}
int main()
{
using namespace std::placeholders;
auto bind_test1 = std::bind(fn, 1, 2, 3);
auto bind_test2 = std::bind(fn, _1, _2, _3);
auto bind_test3 = std::bind(fn, 0, _1, _2);
auto bind_test4 = std::bind(fn, _2, 0, _1);
bind_test1();//1 2 3
bind_test2(3, 8, 24);//3 8 24
bind_test2(1, 2, 3, 4, 5);//1 2 3
bind_test3(10, 24);//0 10 24
bind_test3(10, fn2());//0 10 -1
bind_test3(10, 24, fn2());//0 10 24
bind_test4(10, 24);//24 0 10
return 0;
}
1.7 右值引用
左值:表达式完成后依旧存在的对象,会维持到该作用域结束
右值:表达式结束后,不再存在
纯右值(prvalue, pure rvalue),纯粹的右值,要么是纯粹的字面量,例如 10, true; 要么是求值结果相当于字面量或匿名临时对象,例如 1+2。非引用返回的临时变量、运算表达式产生的临时变量、 原始字面量、Lambda 表达式都属于纯右值;(字符串字面量只有在类中才是右值,当其位于普通函数中是左值。)
将亡值(xvalue, expiring value),是 C++11 为了引入右值引用而提出的概念(因此在传统 C++ 中, 纯右值和右值是同一个概念),也就是即将被销毁、却能够被移动的值。
2.容器
2.1 线性容器array
std::array
原因:array是有固定大小的容器,std::vector 是自动扩容的,当存入大量的数据后,并且对容器进行了删除操作, 容器并不会自动归还被删除元素相应的内存,这时候就需要手动运行 shrink_to_fit() 释放这部分内存
std::vector<int> v;
std::cout << "size:" << v.size() << std::endl; // 输出 0
std::cout << "capacity:" << v.capacity() << std::endl; // 输出 0
// 如下可看出 std::vector 的存储是自动管理的,按需自动扩张
// 但是如果空间不足,需要重新分配更多内存,而重分配内存通常是性能上有开销的操作
v.push_back(1);
v.push_back(2);
v.push_back(3);
std::cout << "size:" << v.size() << std::endl; // 输出 3
std::cout << "capacity:" << v.capacity() << std::endl; // 输出 4
// 这里的自动扩张逻辑与 Golang 的 slice 很像
v.push_back(4);
v.push_back(5);
std::cout << "size:" << v.size() << std::endl; // 输出 5
std::cout << "capacity:" << v.capacity() << std::endl; // 输出 8
// 如下可看出容器虽然清空了元素,但是被清空元素的内存并没有归还
v.clear();
std::cout << "size:" << v.size() << std::endl; // 输出 0
std::cout << "capacity:" << v.capacity() << std::endl; // 输出 8
// 额外内存可通过 shrink_to_fit() 调用返回给系统
v.shrink_to_fit();
std::cout << "size:" << v.size() << std::endl; // 输出 0
std::cout << "capacity:" << v.capacity() << std::endl; // 输出 0
2.1 元组
std::make_tuple: 构造元组
std::get: 获得元组某个位置的值
std::tie: 元组拆包
#include <tuple>
#include <iostream>
auto get_student(int id)
{
// std::tuple<double, char, std::string>
if (id == 0){
return std::make_tuple(3.8, 'A', "张三");
}
if (id == 1){
return std::make_tuple(2.9, 'C', "李四");
}
if (id == 2) {
return std::make_tuple(1.7, 'D', "王五");
}
return std::make_tuple(0.0, 'D', "null");
}
int main()
{
auto student = get_student(0);
std::cout << "ID: 0, "
<< "GPA: " << std::get<0>(student) << ", "
<< "成绩: " << std::get<1>(student) << ", "
<< "姓名: " << std::get<2>(student) << '\n';
double gpa;
char grade;
std::string name;
// 元组进行拆包
std::tie(gpa, grade, name) = get_student(1);
std::cout << "ID: 1, "
<< "GPA: " << gpa << ", "
<< "成绩: " << grade << ", "
<< "姓名: " << name << '\n';
}
获取元素可以通过:std::get<属性>();
std::tuple<std::string, double, double, int> t(“123”, 4.5, 6.7, 8);
std::cout << std::getstd::string(t) << std::endl;
弊端:如果元素一样呢?
可以通过下标的方式:
std::cout << std::get<3>(t) << std::endl;
元祖进行合并:std::tuple_cat(tup1,tup2);
auto new_tuple = std::tuple_cat(get_student(1), std::move(t));
遍历元祖:
3.智能指针
std::shared_ptr/std::unique_ptr/std::weak_ptr
3.1 shard_ptr
记录多少个 shared_ptr 共同指向一个对象,std::make_shared 会分配创建传入参数中的对象;
std::make_shared()并返回这个对象类型的std::shared_ptr指针当引用计数变为零的时候就会将对象自动删除
#include <iostream>
#include <memory>
void foo(std::shared_ptr<int> i) {
(*i)++;
}
int main() {
auto pointer = std::make_shared<int>(10);
foo(pointer);
std::cout << *pointer << std::endl; // 11
return 0;
}
std::shared_ptr 可以通过 get() 方法来获取原始指针,通过 reset() 来减少一个引用计数, 并通过use_count()来查看一个对象的引用计数
auto pointer = std::make_shared<int>(10);
auto pointer2 = pointer; // 引用计数+1
auto pointer3 = pointer; // 引用计数+1
int *p = pointer.get(); // 这样不会增加引用计数
std::cout << "pointer.use_count() = " << pointer.use_count() << std::endl; // 3
std::cout << "pointer2.use_count() = " << pointer2.use_count() << std::endl; // 3
std::cout << "pointer3.use_count() = " << pointer3.use_count() << std::endl; // 3
pointer2.reset();
std::cout << "reset pointer2:" << std::endl;
std::cout << "pointer.use_count() = " << pointer.use_count() << std::endl; // 2
std::cout << "pointer2.use_count() = " << pointer2.use_count() << std::endl; // 0, pointer2 已 reset
std::cout << "pointer3.use_count() = " << pointer3.use_count() << std::endl; // 2
pointer3.reset();
std::cout << "reset pointer3:" << std::endl;
std::cout << "pointer.use_count() = " << pointer.use_count() << std::endl; // 1
std::cout << "pointer2.use_count() = " << pointer2.use_count() << std::endl; // 0
std::cout << "pointer3.use_count() = " << pointer3.use_count() << std::endl; // 0, pointer3 已 reset
3.1 unique_ptr
是一种独占的智能指针,它禁止其他智能指针与其共享同一个对象,从而保证代码的安全:
注意:C++11 没有提供 std::make_unique
实现make_unique:
template<typename T, typename ...Args>
std::unique_ptr<T> make_unique( Args&& ...args ) {
return std::unique_ptr<T>( new T( std::forward<Args>(args)... ) );
}
unique_ptr只允许一个指针指向他
但是可以利用std::move转移他的权限:
#include <iostream>
#include <memory>
struct Foo {
Foo() { std::cout << "Foo::Foo" << std::endl; }
~Foo() { std::cout << "Foo::~Foo" << std::endl; }
void foo() { std::cout << "Foo::foo" << std::endl; }
};
void f(const Foo &) {
std::cout << "f(const Foo&)" << std::endl;
}
int main() {
std::unique_ptr<Foo> p1(std::make_unique<Foo>());
if (p1) p1->foo();//打印
{
std::unique_ptr<Foo> p2(std::move(p1));
f(*p2);//打印
if(p2) p2->foo();//打印
if(p1) p1->foo();//不打印
p1 = std::move(p2);
if(p2) p2->foo();//不打印 作用yu结束 p2销毁
}
if (p1) p1->foo();//打印
}
之后出现了一种特殊情况,引出weak_ptr(两个shared_ptr相互指)
struct A;
struct B;
struct A {
std::shared_ptr<B> pointer;
~A() {
std::cout << "A 被销毁" << std::endl;
}
};
struct B {
std::shared_ptr<A> pointer;
~B() {
std::cout << "B 被销毁" << std::endl;
}
};
int main() {
auto a = std::make_shared<A>();
auto b = std::make_shared<B>();
a->pointer = b;
b->pointer = a;
}
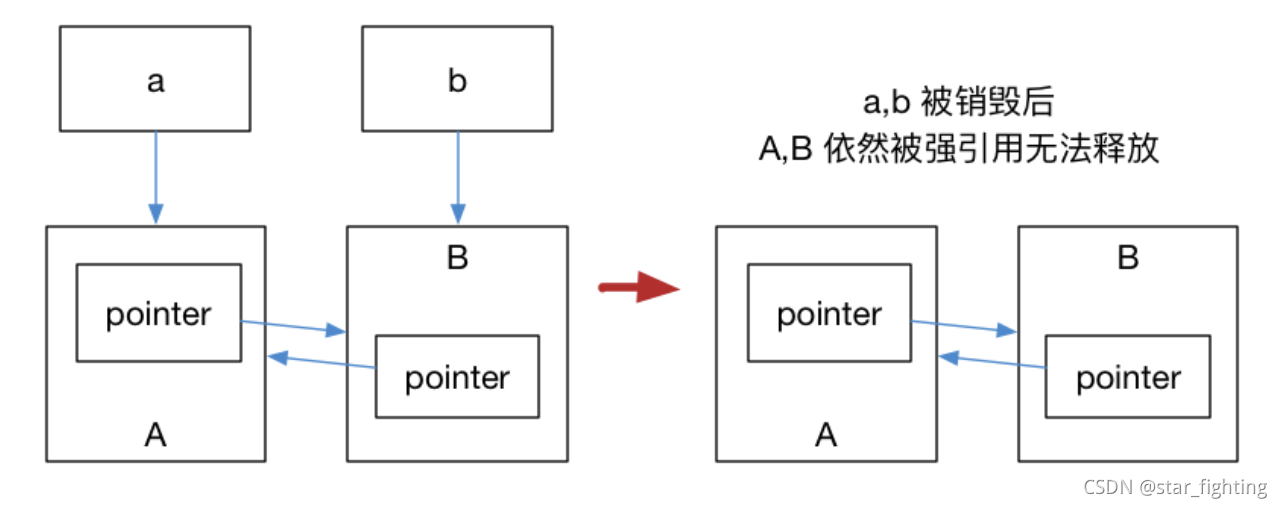
弱引用不会引起引用计数增加;
std::weak_ptr 没有 * 运算符和 -> 运算符,所以不能够对资源进行操作,它的唯一作用就是用于检查 std::shared_ptr 是否存在,其 expired() 方法能在资源未被释放时,会返回 false,否则返回 true
4.线程并发
std::thread 用于创建一个执行的线程实例,所以它是一切并发编程的基础,使用时需要包含 头文件, 它提供了很多基本的线程操作,例如 get_id() 来获取所创建线程的线程 ID,使用 join() 来加入一个线程等等
引入互斥量
std::mutex 是 C++11 中最基本的 mutex 类,通过实例化 std::mutex 可以创建互斥量, 而通过其成员函数 lock() 可以进行上锁,unlock() 可以进行解锁
注意:std::unique_lock 与std::lock_guard都能实现自动加锁与解锁功能,但是std::unique_lock要比std::lock_guard更灵活,但是更灵活的代价是占用空间相对更大一点且相对更慢一点。
区别:std::lock_guard 不能显式的调用 lock 和 unlock, 而 std::unique_lock 可以在声明后的任意位置调用, 可以缩小锁的作用范围,提供更高的并发度。
#include <iostream>
#include <thread>
int v = 1;
void critical_section(int change_v) {
static std::mutex mtx;
std::unique_lock<std::mutex> lock(mtx);
// 执行竞争操作
v = change_v;
std::cout << v << std::endl;
// 将锁进行释放
lock.unlock();
// 在此期间,任何人都可以抢夺 v 的持有权
// 开始另一组竞争操作,再次加锁
lock.lock();
v += 1;
std::cout << v << std::endl;
}
int main() {
std::thread t1(critical_section, 2), t2(critical_section, 3);
t1.join();
t2.join();
return 0;
}














 3079
3079











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









