






Part X 因子分析
当我们有一组来自混合高斯模型的数据 ,使用EM算法可以计算出混合模型。在这个设置中,我么通常认为有足够的样本
用来描述高斯结构。例如:样本的个数m 远大于样本的特征维度。现在,考虑当n>>m的情况。在这样的问题里面,即使建立一个
单高斯模型都是困难的,更别说一个混合高斯模型。特别的,由于的一个低纬子空间,如果我们使用m个数据点建立高斯模型,然
后使用最大似然估计计算均和协方差:m个数据点只是
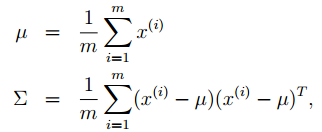
我们会发现,方差矩阵是奇异的。意味着不存在,以及
。而这两者是多元正态分布概率密度函数的必要参数。
通常,除非m在一个合理的范围上超过n,否则最大似然估计计算出的均值和协方差是相当差的。尽管如此,我们仍然希望能够为
数据建立合理的高斯模型,通过样本数据获得正确的协方差矩阵。如何做到这一点呢?
在下一节中,我们将回顾2个协方差矩阵的约束。它们将允许我们用少量的样本数据去计算协方差矩阵,但并不能令人满意的解决
问题。接下来,我们讨论了高斯的一些特性。具体的:如何找到高斯的边缘和条件分布。最后,我们提出了因子分析模型。
1、协方差矩阵的约束
如果我们没有足够的数据去计算完整的协方差矩阵。我们可能考虑对协方差矩阵进行一些限制,例如:我们现在协方差矩阵为对
角矩阵。在这个设置中,那么,很容易通过极大似然估计求出其值:

因此,协方差矩阵的对角元素可以直接从样本数据中计算获得。 回想一下,高斯密度的轮廓是椭圆。一个对角协方差矩阵对应的
多元高斯轮廓线是轴对称的。
有时,我们会对协方差矩阵进一步约束,不仅是对角矩阵,并且对角元素都相等。在这个设置中,有。通过最大似然估计计算:
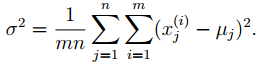
这个模型对应的高斯密度轮廓是圆形的(二维时,高维时是球体)。
如果我们要计算一个完整的,没有约束的协方差矩阵,那么要求m >= n+1,才能使最大似然估计的结果是非奇异矩阵。但是在
上面的任意一个约束下,只要m>=2,我们就能获得非奇异的协方差矩阵。
然而,限制协方差矩阵为对角阵也意味着:随机变量Xi、Xj是不相关、是相互独立的。但是,通常样本数据是相关的。这时如果
我们使用上述2个约束,将会建模失败。在下文中,我们将讨论"因子分析模型",它比对角矩阵使用更多的参数,且能够捕捉到样本
数据间的相关性。同时它不必计算整个协方差矩阵。
3 边缘和条件高斯分布
在描述因素分析前,我们讨论如何找到一个多变量高斯分布的随机变量的条件和边缘分布。
假设我们有如下随机变量向量:

其中:逆对角元素存相互对称
。
按照我们的假设,x1和x2是联合多变量高斯分布,那么x1的边缘分布是什么?明显E[X1] = u1,Cov(x1) = E[(x1 − µ1)(x1 − µ1)] = Σ11。根据协方差矩阵的定
义有:
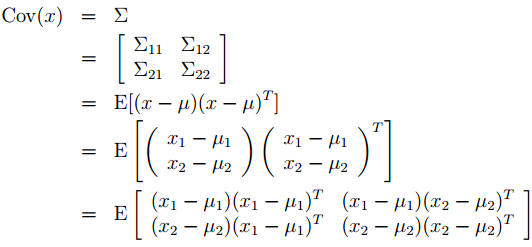
从上式可以得到:随机变量 的边际分布为
的边际分布为;若在
 给定的前提下,的条件分布为
给定的前提下,的条件分布为,其中:
在下一节的因素分析模型中,这些寻找高斯的条件和边缘分布的公式将是非常有用的。
由以上的直观分析,我们知道了因子分析其实就是认为高维样本点实际上是由低维样本点经过高斯分布、线性变换、误差扰动生
成的,因此高维数据可以使用低维来表示。
3、因子分析模型
在因子分析模型中,我们假设联合分布(x,z)如下,其中z是一个隐藏随机变量:
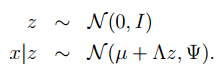
其中:,并且
为对角阵,
 。
。
其等价于:
假如随机变量z和x的联合高斯分布可以写成如下形式:
由于,因此,
。
那么:
由上文可知:
下面对其分别求解:
因此,随机变量z和x的联合高斯分布为:
随机变量x的边际分布为,因此,给定的训练集
,我们就可以得出其对数的似然方程:
为了得到最大似然估计,需要对似然方程求最大值。然而,求解该方程的最大值极其困难,因此我们可以采用EM算法对极大似然函数进行求解。
五、EM算法求解因子分析
条件概率,根据第二三节的结论可以推出:
根据EM算法的定义可知,E-step为:
M-step需要最大化:
这里的下标是指以
为随机变量,
为密度函数的期望。
我们忽略与带估计参数无关的项,实际就是求下式的最大值:
下面我们分别求出待估参数:
(1)
为求出上式关于的偏导,可将上式整理,去除与
无关项,可得等价式:
上式第2行至第3行根据trAB=trBA, 第3行至第4行根据。
令上式为0,可得:
解得:
根据对的定义,
为
,因此可得:
将上述两式结果带入可得:
(2)
将M步的公式对求偏导,可得:
(3)

再令,即可得到
的值。
六、总结
当样本由混合高斯模型得来,并且样本的数量m小于样本的维度n时,由于协方差矩阵为奇异的,因此无法直接通过极大似然进行参数估计。因子分析模型通过引入隐随机变量和随机噪声,构造样本与隐随机变量的联合分布,该联合分布的协方差矩阵为非奇异的。然后再利用EM算法进行参数估计,建立模型。















 4226
4226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









