






 本文探讨了自编码器和变分自编码器在深度学习中的重要性,介绍了基础模型如Autoencoder和DenoisingAutoencoder,以及它们在图像生成、视频处理和噪声去除等方面的应用。着重讲解了VAE及其扩展,如ConditionalVAE和TD-VAE,展示了这些模型在现代AI技术中的关键角色。
本文探讨了自编码器和变分自编码器在深度学习中的重要性,介绍了基础模型如Autoencoder和DenoisingAutoencoder,以及它们在图像生成、视频处理和噪声去除等方面的应用。着重讲解了VAE及其扩展,如ConditionalVAE和TD-VAE,展示了这些模型在现代AI技术中的关键角色。
目录
收起
1 引言
2 符号术语
2.1 AE中的符号
2.2 VAE中的符号
3 基础自编码器
3.1 Autoencoder
3.2 Denoising Autoencoder
随着Stable Diffusion和Sora等技术在生成图像和视频的质量与帧率上取得显著提升,能够在一个低维度的压缩空间进行计算变得越发重要。这种方法不仅大幅度提升了处理效率,还保证了生成内容的高质量。正是在这种背景下,变分自编码器(VAE)及其相关模型的重要性日益凸显。 —— AI Dreams, APlayBoy Teams!
1 引言
在当今深度学习和人工智能的飞速发展中,自编码器(AE)和变分自编码器(VAE)等模型已成为理解和生成复杂数据结构的关键工具。这些模型不仅推动了我们对高维数据表示的深入理解,还在多个领域,如图像处理、自然语言处理和声音合成等方面发挥着至关重要的作用。
特别地,最近在图像生成领域引起广泛关注的Stable Diffusion,以及在视频处理领域的Sora,都严重依赖于VAE模型。这些先进技术能够将图片或视频压缩到潜在空间中,从而在这些潜在空间上处理数据,大大提高了效率。通过在潜在空间进行操作,这些系统能够以前所未有的速度和灵活性生成高质量的图像和视频内容。
在这篇博客中,我们将深入探讨自编码器的世界,介绍其基本原理、不同类型及其在实际问题中的应用。我们将从基础的符号和术语讲起,帮助读者理解后续内容。紧接着,我们会深入分析各种类型的自编码器,从基本的Autoencoder到Denoising Autoencoder、Sparse Autoencoder和Contractive Autoencoder等。
进一步,我们将转向VAE及其扩展。我们会详细探讨标准VAE以及通过各种手段扩展VAE的多种方法,如Conditional VAE、Beta-VAE、VQ-VAE和VQ-VAE-2等。这些模型在处理图像和声音数据方面展现出了卓越的性能。此外,我们还将介绍专门处理时间序列数据的TD-VAE,以及其他一些VAE的变体。
通过本博客,读者不仅能全面了解自编码器及其变种的知识,还能洞察这些模型在现代AI技术中的重要地位和应用潜力。无论您是数据科学家、研究人员还是对深度学习充满好奇的初学者,都能从这篇博客中获得宝贵的知识和灵感。
2 符号术语
2.1 AE中的符号
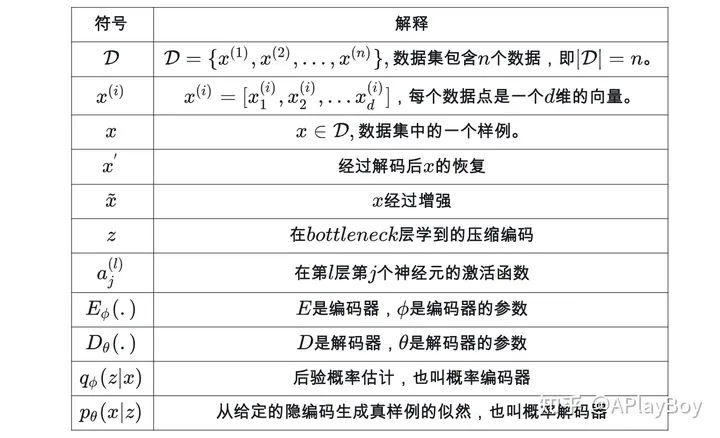
letex手机显示有问题,这里做了截图
2.2 VAE中的符号
符号解释先验概率似然概率后验概率符号解释��(�)先验概率��(�|�)似然概率��(�|�)后验概率
3 基础自编码器
3.1 Autoencoder
Autoencoder是一种自监督的神经网络,用于学习数据的高效表示。其主要目标是通过压缩数据并尝试重构它来捕捉数据的关键特征。
Autoencoder,即自编码器,是一种以无监督学习方式工作的神经网络。它的核心目标是通过学习一个恒等解码函数 �≈�(�)=��(��(�)) ,来重构原始输入数据。在这个过程中,Autoencoder不仅实现了数据的重构,还对数据进行了压缩处理,揭示了数据的更有效的压缩表示。
两大部分
- 编码器网络(Encoder):这一部分将原始的高维输入 � 转换为低维的隐编码 � 。通常,输入的维度大于输出的维度,实现了对数据的压缩和特征提取。数学上,编码器可以表示为 �=��(�) ,其中 �� 是编码函数, � 是其参数。
- 解码器网络(Decoder):解码器的任务是从隐编码 � 中恢复出原始数据 �′ 。其结构可能包含逐渐扩展的输出层。解码器可以表示为 �′=��(�) ,其中 �� 是解码函数, � 是其参数。
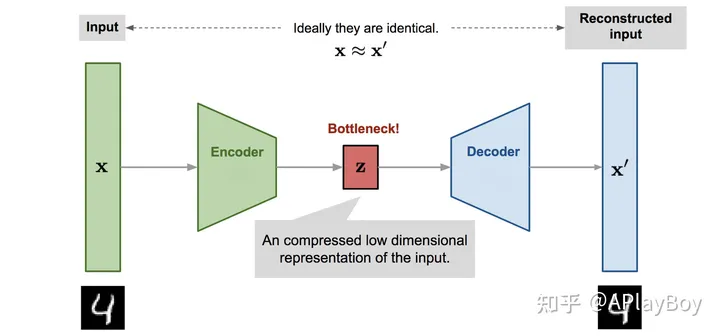
Autoencoder模型架构
实质
Encoder网络类似于我们使用主成分分析(PCA)或矩阵分解(MF)进行数据降维的过程。此外,Autoencoder对于从隐编码 � 中恢复数据的过程进行了特别的优化。一个良好的中间表示(即隐编码 � )不仅能够有效捕捉数据的潜在变量,还对数据解压缩过程有所助益。
损失函数
在学习过程中,我们的目标是使得重构后的数据 �′ 尽可能地接近原始输入 � ,即 �≈��(��(�)) 。通过这种方式,同时学习编码器和解码器的参数 � 和 � 。这实际上等同于学习一个恒等函数。为了量化重构数据和原始数据之间的差异,我们可以使用不同的方法,例如当激活函数为Sigmoid时使用交叉熵,或者直接采用均方误差(MSE)损失函数为:�(�,�)=1�∑�=1�(��−��′)2应用:
-
- 数据降维:类似于PCA,但能捕捉非线性关系。
- 特征提取:从复杂数据中提取有用的特征。
- 数据去噪:学习去除输入数据中的噪声。
- 生成模型:生成与训练数据相似的新数据。
3.2 Denoising Autoencoder
Denoising Autoencoder是Autoencoder的一个变体,专门用于数据去噪和更鲁棒的特征学习。它通过在输入数据中引入噪声,然后训练网络恢复原始未受扰动的数据。这个过程迫使网络学习更为鲁棒的数据表示,忽略随机噪声,从而提高模型对输入数据中噪声或缺失值的容忍度。
由于Autoencoder(自编码器)学习的是恒等函数,当网络的参数数量超过数据本身的复杂度时,存在过拟合的风险。为了避免这一问题并提高模型的鲁棒性,这种改进方法是通过在输入向量中加入随机噪声或遮盖某些值来扰动输入,即 �~ ∼����������(�) ,然后使用 �~ 训练模型恢复出原始未扰动的输入 � 。
在数学上,这可以表示为 �≈��(��(�~)) ,其中 �~ ∼����������(�) 、损失函数为 �(�,�)=1�∑�=1�(��−��′)2 。
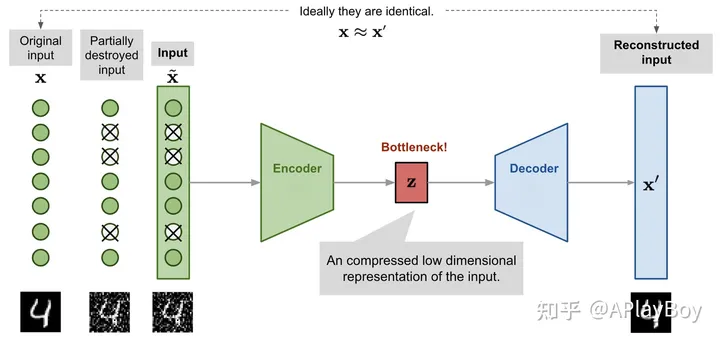
Denoising Autoencode模型框架
人们即使在视觉部分被遮挡或损坏的情况下,也能轻易地识别出场景和物体。Denoising Autoencoder的设计灵感正来源于这一人类视觉的特性。通过修复输入的损坏部分,Denoising Autoencoder能够发现并捕获输入空间中的关系,进而推断出缺失的部分。
对于那些具有高冗余度的高维输入,例如图像,该模型能够依据多个输入维度的组合信息来恢复去噪后的版本,而不是对单个维度产生过拟合。这为学习更加鲁棒的隐含表征奠定了坚实的基础。引入的噪声是通过随机映射 ����������(�) 控制的,而不局限于特定类型的扰动过程(如掩蔽噪声、高斯噪声、椒盐噪声等),这种扰动过程可以自然地融入先验知识。
在原始DAE论文的实验中,通过在输入维度上随机选择固定比例的维度,然后将它们的值强制置为 0 来添加噪声。这种方法听起来有点类似于dropout,但值得注意的是,Denoising Autoencoder最早于2008年提出,比dropout的论文早了整整4年。
应用:
-
- 图像去噪:用于清理图像和视频中的视觉噪声。
- 数据预处理:改善其他机器学习模型处理噪声数据的能力。
- 提高模型鲁棒性:对于自然语言处理和声音识别等领域的数据清洗。
- 特征提取:从噪声数据中提取关键特征,用于后续的数据分析或机器学习任务。


















 939
939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











